
서울 강서구 데이터바우처 사업관리 가공기업
서울 강서구 에는 라크(주), 주식회사 테크스페이스, 주식회사 닥터송 외 18개의 가공기업이 있습니다.
넷츠프리 주식회사 소개
- 넷츠프리 주식회사은 2018-12-10에 설립되었습니다.
- 주소 : 서울 강서구 마곡중앙8로1길 26 4층 406호
- 주요 서비스 : [인공지능 요약솔루션, 비노미ai] (가) 영상자료 (텍스트, 오디오포함)를 업로드하여 텍스트로 전환(나) 전환된 텍스트자료를 키워드산출하여 요약솔루션 편집기로자동 전송 (다) 개인화 맞춤 요약편집기로 원하는 만큼, 필요한 내용만 마음대로 요약작업(라) 요약한 결과를 다양한 파일로 다운로드 또는 웹으로게시후 공유 [인공지능 요약솔루션, 비노미on] (가) 템플릿라이브러리에서 원하는 마이크로러닝 템플릿선택(나) 선택한 템플릿을 활용하여 PPT보다 쉽고 빠르게 콘텐츠 제작 (다) 제작된 콘텐츠를 게시하고 원하는 사용자를 초대하여바로 학습/공유가능 [비토미 관리도구](가) 템플릿라이브러리에서 원하는 마이크로러닝 템플릿선택(나) 선택한 템플릿을 활용하여 PPT보다 쉽고 빠르게 콘텐츠 제작 (다) 제작된 콘텐츠를 게시하고 원하는 사용자를 초대하여바로 학습/공유가능
- 보유 솔루션 : [보유 기술력] (가) CONX기반의 인공지능 엔진기술보유(나) 최신의 인공지능 요약알고리즘을 적용한 요약추출인공지능모델 개발 및 보급 (다) 광범위한 KoBART모델을통한 차별화된 학습모델을 구현한 인공지능 요약생성모델 개발 및 보급 (라) 인공지능 키워드산출모델개발 및 보급 (마) 자동화 학습을 위한 MLOPs 환경 구축 및 운영 (바) 마이크로러닝 학습설계사 글로벌 마스터 인증 (사) 마이크로러닝 학습설계과정에 따른 플랫폼 개발 및운영 (아) 마이크로러닝 콘텐츠개발 연구원을 통한 콘텐츠 개발및 콘텐츠제작
- 품질 확보 전략 : 4년간 축적된 영상교육자료로 마이크로러닝 콘텐츠로제작한 원본자료와 요약본 자료로 학습된 차별화된 AI요약솔루션 비토미ai는MLOPs를 구축하여 정규적으로 자동화 기계학습을 통해 고도화가 되기 때문에 고객의 요구에 맞게 각산업별 특화된 모델을 생산하게 됩니다.[품질확보를 위한 전략](가) 현재 진행되고 있는 요약서비스를 통해 축적된 데이터의양에 따라 자동 기계학습을 통한 고도화(나) 요약결과의 품질을 위한 내부 콘텐츠연구원들에 의한검수 및 보완작업을 통한 정확도 향상 (다) 원본의 내용의 왜곡을 방지하기 위한 요약추출방식적용 (라) 요약의 만족도를 높이기 위한 다양한 맞춤형 요약편집기제공 (마) 영상자료 관리도구를 통한 영상 원본자료관리 및재생/재요약을 통한 다양한 요약산출가능 (바) 분기별 고객의 요구사항을 접수하여 업그레이드 및고도화 작업
- 유지보수 전략 : 신속한 유지보수 지원을 위해 자체 단계별 서비스절차와서비스팀을 운영합니다.[유지보수 전략](가) 단계별 서비스절차에 따라 4시간이내 응답후 조치작업(나) 기술팀은 수요기업이 사용하는 시스템상황을 점검하는대시보드를 구축하여 실시간 모니터링(다) 콘텐츠팀은 지속적인 콘텐츠 템플릿을 개발하여 수요기업이콘텐츠개발시 활용하도록 콘텐츠라이브러리 운영 (라) 클라우드환경을 통해 서비스의 지속성 유지
- 카테고리 구분 : 전처리
- 실적 : 최근 3년간의유사한 주요사업현황으로는, (가) 한화생명 신입사원 교육프로그램을 마이크로러닝콘텐츠로제작 (나) 메트라이프생명 보험상품교육을 마이크로러닝콘텐츠로제작하고 영상교육파일 요약서비스 제공(다) 한국방역협회, 소독업무법정교육과정을 마이크로러닝플랫폼에 런칭(라) 사이버한국외국어대학, 마이크로러닝센터구축 및 콘텐츠공동개발 (마) 아모레퍼시픽, 글로벌리더를위한 마이크로러닝 교육플랫폼 구축 (바) 수협중앙회, 마이크로러닝콘텐츠제작및 플랫폼구축(사) 한양대학교 사범대학 교육공학과와 마이크로러닝 공동연구및 학습설계방식 도입(아) 한독약품, 요약솔루션서비스 (자) 서초여성일자리주식회사, 요약솔루션 서비스(차) KG에듀원, 교원임용과정에요약솔루션 런칭 (카) 나야넷, 안전보건교육과정마이크로러닝콘텐츠와 요약솔루션 런칭
- 기업 개요 및 핵심역량 : 넷츠프리는 마이크로러닝기반의 인공지능 핵심요약솔루션과마이크로러닝플랫폼을 제공하는 벤처기업입니다.급격히 증가한 온라인교육과 화상교육/화상회의로인해 늘어가는 영상자료를 인공지능 요약솔루션, 비토미를 통해 텍스트로 변환하고, 개인맞춤형 요약편집기로 필요한 핵심요약만을 을 제공하여 1시간의긴영상자료를 5%이내로 요약하여 짧은 시간에 반복학습을 통해 학습효율을 향상시킬 수 있습니다.
[당사의 핵심역량](가) 각 분야에 10년이상의경험이 있는 전문화된 탁월한 팀(나) 자체 개발한 인공지능 핵심요약 생성/추출 엔진과 모델보유 (다) 자체 개발한 핵심키워드 산출 인공지능 모델보유(라) 국내 유일의 마이크로러닝 학습설계방식 보유 (마) 마이크로러닝 학습설계방식기준의 마이크로러닝 플랫폼자체개발하여 보유(바) PPT보다 쉽고 빠른 마이크로러닝 저작도구 보유[기술력 입증현황](가) 한화생명 스타트업 육성기업선정 (나) 한국데이터진흥원 데이터바우처 AI가공분야 공급기업(다) 한국교육학술정보원 교육혁신분야 육성사업 선정 (라) 교육부 지식샘터 디지털랩 공급기업 (마) 정보통신산업진흥원 AI바우처 공급기업 (바) 모바일콘텐츠자동화 특허출원 (사) 마이크로러닝 학습설계사 민간과정 운영 (한양대학교 교육공학과 와 공동 연구) - 활용 사례 : [사례1
– 영상교육자료의요약보기] 증가하는 영상자료를 사용자들이 쉽고 빠르게 찾아서요약내용을 확인후 원하는 내용이면 재생하게 하는 사례(가) 영상자료를 업로드(나) 키워드와 요약내용을 추출하여(다) 고객서버의 영상자료를 요약과 키워드를 통해 쉽고빠르게 확인하도록 서비스 구축 (라) 개선점: 영상자료를보면서 원하는 내용을 확인하는 시간절감, 영상자료 찾는 시간 절감 [사례2
– 온라인교육/화상교육/화상회의후 요약결과 제공]증가하는 온라인교육/화상교육/화상회의후 요약결과를 제공하여 커뮤니케이션을 향상하고, 학습효율을 향상 (가) 영상자료를 업로드(나) 핵심 요약편집기로 핵심 요약내용을 산출 (다) 이메일, 온라인, 웹등 다양한 방법으로 핵심요약내용을 전달하여 개인화된 학습가능 (라) 개선점: 영상을2번 시청할 필요없이 1번 시청후 요약내용을 통해 정확하게필요한 내용을 학습할 수 있어 시간절감과 학습효과향상 [사례3
– 마이크로러닝콘텐츠제작] 강사 또는 선생님들이 PPT보다 쉽고 빠르게 마이크로러닝 콘텐츠를 제작하여 자신만의 학습환경을 구축(가) 템플릿 라이브러리에서 템플릿선택(나) 선택한 템플릿으로 콘텐츠 제작(다) 완료된 콘텐츠를 학습자를 초대하여 학습/공유 (라) 개선점: 자신만의온라인교육환경을 구축하여 자신의 콘텐츠사업 및 교육서비스를 제공할 수 있음
(주)비투아시스템즈 소개
- (주)비투아시스템즈은 2007-01-17에 설립되었습니다.
- 주소 : 서울 강서구 마곡중앙로 161-8 B동 604호(마곡동, 두산더랜드파크)
- 주요 서비스 : ●1단계(계획수립) 수요기업으로부터 공식적으로 데이터 가공서비스 요청을 접수 받게 되면, 수요기업과의 협의 과정을 통해 다음과 같은 Task를 도출하여 상호 합의 후 진행합니다.
– 요청 배경 및 추진 목적
– 요구사항 수집 및 환경 분석 : 데이터 유형, 보유 장비 현황 등
– 담당자 인터뷰 : 담당자 요구사항, Pain point 등
– 요구사항 확정 : 서비스 규모 산정
– 데이터 가공 프로세스 및 구축 환경 공유
– 사업수행계획서 제출●2단계(데이터 가공서비스 구축) 데이터 가공서비스의 전 처리 과정은 아래와 같이 5단계 처리 순서에 따라 진행되며, 단계별 종료 절차는 수요기업과 합의 후 후속 단계를 진행하게 됩니다.
전 처리 과정은 당사에서 개발한 플랫폼을 적용하게 되며, 단계별 상세 내용은 다음과 같습니다.
① 데이터수집 수요기업이 보유하고 있는 다양한 데이터 형태를 분석하여 가공이 필요한 데이터를 분류하는 과정입니다.
데이터 형태는 엑셀, 데이터베이스, 장비와 인터페이스 되는 로우 데이터 등 다양한 형태로 존재가 가능합니다.
② 데이터저장 데이터수집 단계에서 확정된 데이터를 일종의 로우 데이터 형태로 저장하는 과정입니다.
기본적으로 데이터는 제공되는 환경의 데이터베이스에 저장이 됩니다.
③ 데이터처리 저장된 데이터를 기반으로 분석에 필요한 데이터를 정제 후 가공된 데이터를 데이터 마트 형태로 저장하는 과정입니다.
이 데이터 정제 과정에서는 수요기업이 데이터 속성의 필요성 여부를 결정하게 됩니다.
④ 데이터분석 데이터 마트가 구성이 되면, 본격적으로 계층 또는 부서에서 요청한 데이터를 분석하게 됩니다.
분석된 결과는 시각화 기능으로 표현이 가능하고, CSV 파일(엑셀) 형태로 다운로드가 가능합니다.
⑤ 데이터시각화 분석된 데이터를 기반으로 시각화가 필요한 경우 다양한 그래프를 활용하여 제공이 가능하며, 목록 형태로도 데이터를 제공할 수 - 보유 솔루션 : 자체 개발한 “중소 및 중견기업 전용 빅데이터 플랫폼”당사가 자체적으로 개발한 “중소 및 중견기업 전용 빅데이터 플랫폼”은 하둡 기반의 Open SW 기반으로최대한 Slim화 하였으며, 데이터 가공에 필요한 전 처리 과정은 Python 언어를 기본적으로 활용합니다.또한, 고성능 빅데이터 분석용 서버를 보유하고 있어, 대용량 데이터 처리가 가능한 수준입니다.
- 품질 확보 전략 : 데이터 가공서비스에 대한 품질관리 확보 전략은, 대기업에서 적용하고 있는 개발 방법론(분석
->설계
->개발
->테스트
->이행)과 품질관리 프로세스를 응용하여 적용하며,무엇보다 책임감을 가지고 품질을 보증할 수 있도록 하겠습니다.다만, 산출물의 경우에는 수요기업과의 협의를 통해 적절한 수준으로 조정은 가능합니다. - 유지보수 전략 : 공급기업으로부터 인계된 데이터 가공서비스는 수요기업이 목적에 맞게 사용하고 있는지 지속적인 관리가 필요합니다.이를 위해 공급기업으로써 다음과 같은 활동을 전개합니다.① 시스템 모니터링 및 활용 리포트 제공 시스템 모니터링을 통해 수요기업의 활용도를 다각도로 점검하여, 정기적으로 활용 리포트 제공하며, 이를 통해 수요기업이 목적에 맞게 활용할 수 있도록 유도한다.② 정기 방문점검 활동 정기적으로 수요기업을 방문하여, 문제점을 도출하고 시스템에 반영하는 일련의 개선 활동을 전개합니다.③ 정기 CSI(고객만족도) 조사 실시 수요기업을 대상으로, 정기적인 CSI 조사(년1~2회)를 실시하며, 이를 통해 수요기업의 불만 요인을 발굴하여 조치함으로써 공급기업의 책임과 의무를 다 하고자 합니다.④ 1년간 무상 유지보수 실시 공급기업으로부터 인계된 데이터 가공서비스는 최초 1년간 무상 유지보수가 제공되며, 이후부터는 수요기업과 협의를 통해 유상 유지보수를 체결하는 것으로 한다.
다만, 최초 1년 이내에 발생되는 추가 요구(개발)사항에 대해서는 수요기업과 협의하여 유상으로 진행하는 것을 원칙으로 한다. - 카테고리 구분 : 전처리,코딩,시각화,정보추출또는조합,분석
- 실적 : 최근 3년간 당사가 수행한 데이터와 관련된 사업실적은 다음과 같습니다.
– 09년 7월~현 재 : SK브로드밴드 DW 및 빅데이터(Oasis) 시스템 유지보유
– 19년 9월~현 재 : SK브로드밴드 빅데이터(LDAS) 구축 및 유지보유
– 19년 7월~20년 4월 : SK브로드밴드 빅데이터(Ocean) 고도화 구축
– 21년 7월~21년 9월 : 미래에셋증권 노후 DW 장비 교체 프로젝트
– 22년 1월~23년 1월 : SK브로드밴드 빅데이터(Oasis) Cloud 전환구축
– 23년 2월~23년 5월 : SK텔레콤 DBM 스파크 전환구축(계약진행중) - 기업 개요 및 핵심역량 : ●기업개요 당사는 ‘07년 1월에 설립한 16년차 업력의 기업으로, 비즈니스 서비스 기반의 빅데이터 전문기업을 지향하고 있습니다.
당사의 주요사업 분야는 다음과 같습니다.
– 빅데이터시스템 구축 사업
– 빅데이터시스템 유지보수 사업
– 빅데이터시스템 비즈니스 모델 연구개발
– 응용시스템 구축 및 유지보수 사업●핵심역량 당사는 16년간 대기업 파트너사로서 고객사 데이터 처리 업무수행 경험을 통해 업무지식 및 데이터 처리 기술력을 보유하고 있으며, 21명의 정규직 중 13명(62%)이 빅데이터 관련 기술을 보유하고 있습니다.
당사의 주요 핵심역량은 다음과 같습니다.
– 대기업 기반의 프로젝트 수행 경험 및 고객 대응력 확보(마트 설계 및 구현 등)
– 데이터 가공 및 처리 업무에 대한 높은 이해도 (데이터 추출/저장/처리/분석/시각화)
– 데이터 처리 응용 기술(PL/SQL, Informatica, Datastage, TeraStream, BI툴(MSTR) 등)
– 빅데이터 처리 응용 기술(Hadoop, Hive, Spark SQL, Oozie, AirFlow, Snowflake, Python 등)
– 다양한 데이터베이스 처리 기술(Oracle Exa, Oracle, SyBase, PostgreSQL, Tibero 등)
– Cloud 기반의 다양한 Open SW 기술력 보유
– 직원들에 대한 지속적인 신기술(AI,딥러닝 등) 교육훈련 실시
– 프로젝트 관련 산출물 작성 능력 보유 - 활용 사례 : <;사례1> 다양한 공공데이터 포탈 데이터의 가공이 필요한 경우<;사례2> 포탈사이트에서 웹 크롤링으로 수집된 데이터의 가공이 필요한 경우<;사례3> 다양한 DB에 저장된 데이터의 가공이 필요한 경우<;사례4> 다운로드 받은 엑셀 CSV파일 데이터의 가공이 필요한 경우<;사례5> Open API를 통해 수집된 XML데이터를 하둡 파일시스템에 적재 후 가공이 필요한 경우
주식회사에프엘이에스 소개
- 주식회사에프엘이에스은 2019-05-19에 설립되었습니다.
- 주소 : 서울 강서구 마곡중앙로 161-8 A동 614호
- 주요 서비스 : ■[일반 가공] 관심사 기반 오디언스를 활용한 마케팅 성과 데이터 분석 및 대시보드 시각화 서비스
– 관심사 기반으로 세그먼트된 타겟을 활용한 마케팅 집행
– 이를 기반으로 데이터수집 분석부터 분석 및 시각화를 통한 마케팅 전략 도출까지 수요기업 스스로 데이터 기반의 마케팅을 운영할 수 있는 서비스 제공1 데이터 수집 : 맞춤형 이벤트 정의, SDK 설치2 데이터 전처리 : 데이터 통합(구글 빅쿼리), 소스코드 작성3 정보 추출 및 조합 : 관심사별 클러스터링, 관심사별 매출 추이4 품질 : 데이터 품질 검사5 시각화 및 분석 :KPI 대시보드, 수요기업 맞춤형 대시보드제작6 분석 : 성과 분석, 마케팅 전략 수립 ■[AI 가공] 개인화 추천 및 자연어 생성을 위한 인공지능 모델 구축 서비스
-인공지능 개발 전 단계(데이터 수집/가공/전처리/분석)에 관련된 기술 개발노하우를 바탕으로각 단계마다 전문가를배치하여 수요기업에 최적화된 텍스트 증강 모델 및 개인화 추천 모델 제공※공급 기업인 FLES는 고려대학교 HIAI 연구소와 인공지능 연구를 위한 공동연구센터 설립(KFLEXT)1 데이터 구축 : 상품/콘텐츠 데이터 수집, 학습용 데이터 추가 확보, korSTS 데이터셋2 데이터 설계 및 전처리 : 자연어 처리 (어간 추출, 표제어 추출, 불용어 제거, 특수문제 제거 등)3 모델링 : FL
-Recom(개인화 추천
-자연어 분석 : RoBERTa
-base 모델), FL
-Creator(자연어 생성
-KoGPT2, KoBART)4 테스트 : 데이터 품질검사, 모델 성능 개선5 분석 : FL
-Recom(유사도 분석), FL
-Creator(핵심 키워드 도출 및 문장 생성)※가공 서비스의 경우에 데이터 구매 서비스를 포함해서 서비스 이용 가능Ex
1) 일반 가공의 경우 최대 4500만원 지원 > 4500만원 중 구매 비용 1600만원 차감 후 금액으로 상품 구성 가능Ex
2) AI가공의 경우 최대 7000만원 지원 > 7000만원 중 구 - 보유 솔루션 : ■FLES는 고려대학교 HIAI 연구소와 KFLEXT 인공지능 공동연구센터 운영·국내 자연어 처리 분야에 강점이 있는 고려대학교의 인공지능 연구소로 FLES와 공동연구센터 설립·공동연구센터의 23년도 연구과제는 마케팅 성과 예측모델과 스스로 학습하는 대화형 모델로 진행 중 ① 개인화 및 사용자 활동 로그 데이터 수집 능력 ■ 콘텐츠를 통한 사용자 관심사 분석 ·FLES 는 운세 콘텐츠 프로바이더로서 B2B2C 의 다양한 채널을 통해 운영하고 있습니다.
이를 통해 사용자의 정확한 개인정보를 수집할 수 있는 경쟁력을 확보하고 있을 뿐만 아니라 콘텐츠를 통해 사용자의 고민과 관심사를 파악할 수 있는 데이터 수집 및 분석 능력을 보유하고 있습니다.
■ 사용자 프로파일링을 통한 개인화 콘텐츠 추천 인공지능 기술 보유 ·학습한 STS 모델과 데이터의 전처리 과정을 통해 유사한 상품을 추천해주는 기술 ■ FLES SDK를 통해 외부 서비스 사용자 로그 데이터 수집 ·페이지 이동경로, 클릭 영역, 구매내역 등 60가지 이상의 사용자 활동 로그 데이터 수집② FL
-Recomm ( FLES 콘텐츠 유사도 기반 추천시스템 ) ■ 개인화 콘텐츠 추천 인공지능 기술언어 모델인 Roberta 모델을 베이스로 운세 콘텐츠, 사용자의 구매 내역 등의 로그 분석 데이터, korSTS 데이터셋 등을 학습하여 이를 기반으로 사용자의 이용 패턴에 맞는 콘텐츠를 추천하는 기술로, 텍스트를 비교 / 분석하여 유사도(cosine
-similarity)를 기준으로 콘텐츠를 추천하는 방식입니다.③ FL
-Creator ( AI 역술가 ) ■ Transformer 기반의 사전학습 언어모델인 KoGPT2 와 KoBART 모델을 기본 모델 구조로 채택하여 당사는 140만 개 이상의 운세 풀이 텍스트 DB를 학습시키고 이를 통해 새로운 콘텐츠 DB를 생성하는 자연어 생성 기술을 보유하고 있습니다.
■ 해당 기술은 학습용 데이터가 부족한 도메인의 수요기업의 경우, 사람에 - 품질 확보 전략 : ■데이터 품질 관리 전담 부서
– 당사의 플랫폼은 인가 된 운영자만 접속할 수 있도록 설계되어 있습니다.
– 또한 당사의 데이터 수집 도구는 OTP 를 통한 2중 인증을 통해서만 접근이 가능하기 때문에 고객사의 데이터를 안전하게 지킵니다.
– 판매하는 데이터의 품질이 곧 캠페인의 성과와 관련된 문제로 생각하고 제공된 오디언스의 마케팅 성과 향상을 위한 기술 개발을 위해 끊임없이 노력하고 있습니다.■ KFLEXT(고려대학교 HIAI연구소) 인공지능 연구센터를 통한 기술 고도화
– 수요 기업에게 제공된 데이터(AdID) 에 대한 마케팅 성과 예측 모델링 - 유지보수 전략 : ■밀착 케어를 통한 데이터 기반 마케팅 역량 강화
– 플랫폼 내에서는 주문 단위별 담당자를 배치, 1:1 채팅을 통한 밀착 케어가 가능하도록 구성되어 있습니다.
소재 제작부터 마케팅 진행 시 필요한 노하우 컨설팅을 통해 마케팅 성과 향상을 위해 노력합니다. - 카테고리 구분 : 전처리,품질,코딩,시각화,정보추출또는조합,분석
- 실적 : ■2022년 데이터바우처 사업 (구매)
– 총 13개 수요기업 매칭
– 1개 기업 “우수”, 12개 기업 “보통” 최종결과평가 확정■2023년 AI 바우처 지원사업 공급기업 선정 - 기업 개요 및 핵심역량 : FLES :”Accelerating your business with data”FLES 는 데이터 기반의 비즈니스 성장, 비즈니스를 통한 인류 행복 기여라는 비전 아래누구나 쉽게 데이터 기반의 비즈니스를 할 수 있는 환경을 제공하기 위해 노력하는 기업입니다.■주요 사업 분야: 시스템 통합, 콘텐츠 서비스, 데이터 거래 플랫폼
– 공공 기관부터 중소/중견 기업까지 30건 이상의 프로젝트 개발 경험
– 회원 수 50만 명의 운세 서비스
– AudienceM : 타겟 마케팅에 활용하는 데이터(오디언스) 거래 플랫폼
– 2022 고려대 HIAI 연구소와 공동연구센터 설립 데이터바우처 사업 수행 (13개 수요기업) 혁신바우처 공급기업 선정 관광혁신바우처 공급기업 선정
– 2023 데이터바우처 공급기업 선정 ( 구매&가공 ) AI 바우처 공급기업 선정■FLES 는 회원 수 50만 명의 운세 서비스를 운영하고 있습니다.이를 통해 사용자의 관심사와 행동 데이터를 수집하고 이를 마케팅에 활용하실 수 있도록 제공하고 있습니다.
■데이터 판매 상품:타겟 마케팅에 활용하는 모바일 기기ID (AdID)
– 라이프스타일, 데이트, 여행 및 지역정보, 금융, 도서, 건강/운동, 비즈니스, 교육, 커뮤니케이션, 반려동물 등 주요 산업군에 관심을 가지고 있는 오디언스를 추출하여 제공합니다.
-데이터활용의 예시①시의성 있는 프로모션 활동 ◇교육콘텐츠를 제공하는 사업자가 시험을 준비하는 사람을 대상으로 프로모션을진행하고자 한다면, 시험에 합격하고 싶다는 소원을 남긴 사용자,시험과관련된 콘텐츠를 보는 사용자들을추출하여 제공할 수 있습니다.②특정 카테고리에 관심 있는 앱 사용자 확보 마케팅 ◇자사의 산업군 분류는 구글 플레이스토어,앱 스토어의 카테고리를 기준으로 합니다.
◇반려 동물과 관련된 앱을 신규로 런칭한 사업자가 구매력 있는 사용자를 확보하고자한다면, - 활용 사례 : ① 서비스 특징에 맞는 프로모션 활동 ■ 전자책을 판매하는 서비스의 경우, 단순히 구매하는 행동 보다 실제 구매한 전자책을 끝까지 읽는 사용자를 트래킹 하는 것이 중요합니다.
당사의 SDK를 통해 일정 수준 이상 스크롤을 내린 경우 이벤트를 발생시켜 데이터를 수집한다면 “완독 사용자”들을 대상으로 별도의 프로모션을 진행할 수 있습니다.
■ 유사한 사례에서 ROAS(광고비에 대한 매출 비율) 수치가 3배 이상 상승하였습니다.
② 데이터 가공을 통한 새로운 구매 전환 시나리오 생성 ■ 최근 연애에 관심도가 높은 사용자들이 특정 제품에 구매 전환이 높다는 결과를 도출해내고 이를 기반으로 아직까지 해당 제품을 구매하지 않았지만 유사한 관심사를 가진 사용자들을 대상으로 프로모션을 진행할 수 있습니다.
■ 유사한 프로모션을 통해 특정 제품에 대한 판매가 2배 이상 증가하였습니다.③ AI 솔루션
– 개인화 추천■사용자 검색어, 콘텐츠 또는 제품 조회 데이터 등 수집한 데이터의 텍스트 유사도 분석을 통한 개인화 추천 모델■ 추천 검색어 및 콘텐츠 기능■ 연관 콘텐츠 추천④ AI 솔루션
– 자연어 생성 모델■ 140만 개의 운세 풀이 DB를 학습하고 주제별 핵심 키워드를 추출하여 새로운 풀이를 만들어내는 자연어 생성 모델■ 독립 문장 생성 모델: 여러줄의 장문 데이터를 분절하여 각 문장별 핵심 키워드 추출■ 의존 문장 생성 모델 : 분류 기준, 문장에 추가로 포함해야하는 단어, 기존에 생성된 문장
(주)글로버킷 소개
- (주)글로버킷은 2016-07-18에 설립되었습니다.
- 주소 : 서울 강서구 마곡중앙로 161-8 (두산더랜드파크) B동 706호
- 주요 서비스 : 가공업무 진행 계획
– 데이터가공 계획 수립:고객사가 원하는 형태의 데이터 가공 요구사항을 정확하게 정의데이터가공 시스템 구성
– 정의된 데이터 가공을 위해 데이터 가공에 필요한 데이터 수집, 기데이터 활용 방법 데이터 종류 등을 고려하여 상세 데이터 가공 시스템을 체계적으로 구축데이터 가공
– 텍스트, 이미지, 영상, 음성 등 모든 데이터를 구축된 데이터 가공 시스템에 맞게 가공데이터 검수
– 가공이 완료된 데이터는 고객사가 원하는 형태 및 품질 등을 검수데이터 변환 및 전달
– 가공된 데이터를 철저하게 검수한 후 고객사가 원하는 데이터로 추출하여 전달데이터 가공 소스별 상세
– 이미지 : Bounding Box, Segmentation, Cuboid, Landmark Polygon, Masking, Image Collect 등 이미지 데이터 가공
– 텍스트 : SQuAD, Q&A Dataset, Q&A Validation, Speech act,A/B Test, Product experience, Text Collect , Question Collect 등 텍스트 데이터 가공
– 음성 : Audio Transcription, Audio Categorization, Audio Segmentation 등 음성 데이터 가공
– 영상 : Keyframe collect, Joint landmark, Autonomous vehicle 등 영상 데이터 가공 - 보유 솔루션 : DQ Analyzer데이터 품질 점검 분석기자체 관리툴통계 분석 패키지 R, 파이썬 등 사용자체 개발텍스트 가공 솔루션TEXT합의 도출다국어 지원키워드 및 문장별 분류키워드 카운딩 시스템자체 개발텍스트 변환 솔루션AI 음성인식 엔진 사용음성을 음소별로 분류다양한 음원 데이터로 추출피드백 시스템자체 개발첨삭기능 솔루션산업별 최적화하 글쓰기 첨삭 가공국가별 첨삭 기능 제공
- 품질 확보 전략 : 데이터품질관리 체계 구성 및 조직 구성
– 표준관리, 구조관리, 품질관리 등 데이터 품질을 포함한 체계적 데이터 관리 조직 구성하고 데이터품질 관리 프레임워크 적용
– 데이터 품질 관리 프레임 워크 운용데이터품질관리 세부 내용 관리
– 데이터 관리 정책, 데이터 관리 기능, 데이터 관리 프로세스, 데이터 관리 조직, 데이터 관리 도구 항목으로 세분화 하여 관리데이터 품질 진단 프로세스
– 계획 및 현황분석
– 품질 (프로세스 검토)
– 진단 (산출물 검토, 데이터값 품질 측정 및 진단 등)
– 개선방안 수립 (현상 및 원인 분석, 개선기회도출, 결과보고)데이터 품질 컨설팅 의뢰
– 필요시 외부 업체에 데이터품질 컨설팅 의뢰 - 유지보수 전략 : 교육 훈련 계획
– 교육효과를 극대화 하기 위해 차별화 된 교육과정을 개설하여 관리자, 사용자, 운영자,개발자 별로 담당직무에 적합한 교육을 실시하고 적용된 전문기술 교육 중심으로 교육을 진행하며, 사용자 지침서 등의 교육교재를 철저히 지원하여 교육목표에 부합되는 교육이 이루어지도록 수행
– 데이터셋 인수 후 총 2일간 일별 4시간 교육(수요기업과 일정 협의) 일정으로 운영관리자와 유지보수관리자 구분하여 교육 진행 각 2시간 실습교육
– 운영관리자 (시스템개요) : 시스템의 전반적인 이해 및 프로세스 및 기능 사용법 교육유지보수 관리자 (시스템 상세내역 및 운영관리)
– 시스템개요
-시스템 구성 및 상세 설계 내역
– 시스템 구성 및 사용법
– 시스템에 적용된 개발툴(환경)에 대한 이해 및 유지보수를 위한 운영교육
– 운영자 지침서에 의한 사용법
– 시스템 기능을 토대로 한 운영교육
– 장애/응급사항에 대한 대처할 수 있는 복구 방법유지보수 계획
– 수리보수의 경우 최소 6개월 무상 유지보수
– 완전화보수, 적응보수의 경우 고객사와 비용 협의하여 진행하며 유무선 상으로 최대한 서비스 지원 - 카테고리 구분 : 전처리,품질,시각화,정보추출또는조합,태깅또는라벨링,분석
- 실적 : 2022년 데이터바우처 지원사업에 공급기업으로 참여하여 총 6개 수요기업에 데이터가공 사업 수행 완료 (AI 6개사)2019 데이터 표준 구축 업무
– 온라인 배포용 광고 문구 가공 (인비절라인코리아)2018 데이터 품질
– 판매사원 교육용 영상 데이터 품질 확보 업무 진행 (삼성전자판매) - 기업 개요 및 핵심역량 : 데이터바우처 사업 수요기업의 경험을 바탕으로 수요 기업의 요구에 정확히 맞춘 데이터 가공 능력약 15년 간 데이터를 기반으로 한 디지털마케팅 대행 경험과 노하우 보유(대표자 경력)당사는 2021년 데이터바우처 사업에 공급기업으로 참여하여 7개 수요기업과 협약 후 사업 수행 완료
- 활용 사례 : ‘데이터 기반 최적 전기차 충전소 검색 및 인프라 확인 시스템’을 위한 전기차 충전소 혼잡도를 예측하는 데이터셋 가공충전소별 대기시간, 예상 충전 소요시간, 혼잡도, 충전기 종류 등을 고려하여 지도 상에서 데이터를 보여줄 수 있는 가공 데이터와 요일, 시간대, 지역 별 충전소에 대한 정보를 인공지능 학습을 통해 미래 특정 시간, 지역에 대한 전기차 충전소 혼잡도를 예측하는 데이터 셋 가공세계 자동차 산업은 내연기관차에서 전기차로의 시장전환이 급격히 전환 중에 있으며 우리나라 정부에서도 전기차 관련 강력한 정책을 펼치는 중이고 전기차가 빠르게 보급되는 것에 반해 충전인프라 확충은 다소 지연되고 있으며 전기차 사용자간 갈등 증가세에 있으므로 이에 대한 데이터셋 수요가 상당할 것으로 예상됨당사는 대표이사가 관련 포털업체 재직에 따른 경험, 역량과 함께 개발 후 업계 네트워크를 시작으로 최종적인 소비자에게 효과적인 홍보와 마케팅을 진행할 수 있는 역량을 지님
한국시험인증원(주) 소개
- 한국시험인증원(주)은 2017-08-22에 설립되었습니다.
- 주소 : 서울 강서구 마곡중앙로 161-8 B동 1216호
- 주요 서비스 : ㅇ 데이터 가공 및 시험 서비스
– 개발 로그 분석을 통해 품질저하 원인 확인 및 조치
– 이슈 데이터 분석 및 이슈트레킹 정보 제공
– 결함 확인 및 결함 개선 방안 제공
– 최적의 테스트 환경 도출ㅇ AI바우처 공급 사업을 위한 데이터 가공 서비스
– 영상/텍스트 데이터 설계 및 전처리
– AI 데이터셋 구축
– AI 가공 및 모델링ㅇ SW품질 시험 서비스
– AI 성능, 자원효울성 등 성능시험
– 수집 데이터 송/수신 기능 등의 기능시험
– 정적/동적 테스트의 기능안전시험
– 정보 기밀성, 통신 기밀성 등의 사이버시큐리티시험 - 보유 솔루션 :
- 품질 확보 전략 : ㅇ 조직 구성 및 역할 분장, 인력 운용 전략
-데이터 가공업무를 수행하는 인력은 테스팅 전문가와 데이터분석 전문가로 구성
-각 분야에서 10년 이상의 경력을 보유하고 있는 전문가가 가공업무 수행
-고객관리 및 고객응대를 위한 별도 인력을 확보하여 기업의 요구사항을 놓치지 않고 대응하고자 노력함
-프로젝트별 라벨링 규칙 및 S/W에 대한 숙련도가 높은 전문 라벨링 이력이 2회 이상의 전수검사 시행
-지속적인 데이터 가공서비스 인력 확보 추진
-추가 인력 확충을 통하여 가공서비스 수요기업 증가에 대한 수요에 대응ㅇ 물적 자원 활용 전략
– 테스트자동화플랫폼 : 자사에서 개발한 플랫폼으로 개발 전체단계를 관리할 수 있는 통합빌드 프레임워크와 테스팅자동화 모듈, 데이터 분석 및 예측을 통한 테스트프로세스 최적화 모듈 탑재
– KNIME : Open Source로 제공되고 있는 데이터 분석, 보고 및 통합 플랫폼입니다.
KMINE은 모듈식 데이터 파이프라인 개념을 통해 기계학습 및 데이터마이닝을 위한 다양한 기능 제공
– Wireshark : Open Source로 제공되고 있는 패킷 분석 프로그램입니다.
Wireshark는 네트워크 통신을 통해 가공 혹은 가공되지 않은 데이터 스캔 및 분석 기능 제공 - 유지보수 전략 : ㅇ하자보수
-검수 완료 후 1년 이내에 발생하는 데이터의 결함에 대한 하자보수
-기본 점검 및 설치 전 환경 점검, 문제 발생 시 비대면 지원/현장 지원ㅇ 품질개선
-에러수정, 기능 자체의 문제점으로 인한 수정/보완, 결과물의 수정
-운용 중 장애 발생 시 수요기업이 재설치를 요구할 경우 무상 설치하여 업무 차질 최소화 (유저 분석 데이터에 한함)
-결과물 최적화 및 안정화, 업그레이드 지원, 정상 운영을 위한 기술 지원 - 카테고리 구분 : 전처리,품질,시각화,정보추출또는조합,태깅또는라벨링,분석
- 실적 : 1.
디지털인프라 진단 및 개선사업ㅇ 발주처 : 한국정보통신기술협회ㅇ 사업기간 : 2022.03.28 ~ 2022.12.09ㅇ 수행업무 : 국민안전 분야 SW를 대상으로 데이터 품질 점검 수행ㅇ 상세업무
– 데이터의 정확성/완전성/일관성/신뢰성 등의 지표를 활용하여 품질점검 수행
– 발견된 데이터 품질 결함에 대한 개선 방법 가이드 제공
– 개선이 어려운 결함에 대해서 기술지원을 통한 결함 수정2.
데이터바우처 지원사업ㅇ 협약기간 : 2020.07.01 ~ 2020.11.27ㅇ 수행업무
– SNS 여행지 태크 크롤링 및 인기여행지 추출
– 데이터기반 문화관광상품 정보제공 서비스 구축ㅇ 상세업무
– 여행 관련 게시물 태크 크롤링
– 데이터 클렌징 및 정제
– 데이터 분석 및 모델링 - 기업 개요 및 핵심역량 : ㅇ 한국시험인증원은 KOLAS 국제공인 시험기관으로서 테스트 전문 인력이 산업분야/제품특성에 맞는 효율적이고 정확한 테스팅 서비스와 데이터 가공 서비스 제공ㅇ 기업에서 발생하는 개발 및 테스팅 산출물을 분석하고, 이슈사항의 개선방안 도출 및 전달ㅇ 분석 결과는 테스트자동화 플랫폼을 통하여 대시보드 형태로 시각화 제공ㅇ 다양한 SW표준을 보유한 공인 시험기관인 만큼 다양한 제품에 대한 테스트 수행을 진행하여, 보다 많은 데이터 분석 경험 및 전문지식 보유ㅇ SW 품질진단 및 관리 기관으로 선정되며 일반적인 데이터뿐만 아니라 교통, 재난관리, 사회안전 등 국민 안전과 밀접한 분야의 데이터를 진단 수행하였으므로 다양한 데이터 활용 경험 보유ㅇ 데이터 품질 시험, AI바우처 성능 시험, AI바우처 공급 사업을 통해 데이터 특성을 파악하는 경험이 다수 존재하여, 적합한 형태로 데이터 가공 및 관리하는 노하우 보유ㅇ AI 개발 분야와 데이터 분석 및 가공 분야의 담당 파트장이 해당 분야 전공의 석·박사로 구성되어 있으며, 체계화된 프로세스 제공
- 활용 사례 : ㅇ 영상 데이터 추출 : 영상 데이터 데이터베이스화를 위해 정지영상 및 동영상에서 특정 객체 추출ㅇ 영상 클러스터링 : 텍스트, 자동차 그리고 사람과 같은 특정 객체 군집화ㅇ 동영상 스크립팅 : 특정 상황에 대한 동영상 데이터베이스화를 위해 동영상 스크립팅하여 분류ㅇ 객체 라벨링 : 정지영상 및 동영상 상에 표출되는 Multi
-Object를 라벨링하여 객체별 데이터베이스 생성
주식회사 테크스타 소개
- 주식회사 테크스타은 2021-07-14에 설립되었습니다.
- 주소 : 서울 강서구 마곡중앙로 161-8 B동 706호
- 주요 서비스 : 가공업무 진행 계획
– 데이터가공 계획 수립:고객사가 원하는 형태의 데이터 가공 요구사항을 정확하게 정의 데이터가공 시스템 구성
– 정의된 데이터 가공을 위해 데이터 가공에 필요한 데이터 수집, 기데이터 활용 방법 데이터 종류 등을 고려하여 상세 데이터 가공 시스템을 체계적으로 구축데이터 가공
– 텍스트, 이미지, 영상, 음성 등 모든 데이터를 구축된 데이터 가공 시스템에 맞게 가공데이터 검수
– 가공이 완료된 데이터는 고객사가 원하는 형태 및 품질 등을 검수데이터 변환 및 전달
– 가공된 데이터를 철저하게 검수한 후 고객사가 원하는 데이터로 추출하여 전달데이터 가공 소스별 상세
– 이미지 : Bounding Box, Segmentation, Cuboid, Landmark Polygon, Masking, Image Collect 등 이미지 데이터 가공
– 텍스트 : SQuAD, Q&A Dataset, Q&A Validation, Speech act, A/B Test, Product experience, Text Collect , Question Collect 등 텍스트 데이터 가공
– 음성 : Audio Transcription, Audio Categorization, Audio Segmentation 등 음성 데이터 가공
– 영상 : Keyframe collect, Joint landmark, Autonomous vehicle 등 영상 데이터 가공 - 보유 솔루션 : DQ Analyzer데이터 품질 점검 분석기자체 관리툴통계 분석 패키지 R, 파이썬 등 사용자체 개발텍스트 가공 솔루션TEXT합의 도출다국어 지원키워드 및 문장별 분류키워드 카운딩 시스템자체 개발텍스트 변환 솔루션AI 음성인식 엔진 사용음성을 음소별로 분류다양한 음원 데이터로 추출피드백 시스템자체 개발첨삭기능 솔루션산업별 최적화하 글쓰기 첨삭 가공국가별 첨삭 기능 제공
- 품질 확보 전략 : 데이터품질관리 체계 구성 및 조직 구성
– 표준관리, 구조관리, 품질관리 등 데이터 품질을 포함한 체계적 데이터 관리 조직 구성하고 데이터품질 관리 프레임워크 적용
– 데이터 품질 관리 프레임 워크 운용데이터품질관리 세부 내용 관리
– 데이터 관리 정책, 데이터 관리 기능, 데이터 관리 프로세스, 데이터 관리 조직, 데이터 관리 도구 항목으로 세분화 하여 관리데이터 품질 진단 프로세스
– 계획 및 현황분석
– 품질 (프로세스 검토)
– 진단 (산출물 검토, 데이터값 품질 측정 및 진단 등)
– 개선방안 수립 (현상 및 원인 분석, 개선기회도출, 결과보고)데이터 품질 컨설팅 의뢰
– 필요시 외부 업체에 데이터품질 컨설팅 의뢰 - 유지보수 전략 : 교육 훈련 계획
– 교육효과를 극대화 하기 위해 차별화 된 교육과정을 개설하여 관리자, 사용자, 운영자,개발자 별로 담당직무에 적합한 교육을 실시하고 적용된 전문기술 교육 중심으로 교육을 진행하며, 사용자 지침서 등의 교육교재를 철저히 지원하여 교육목표에 부합되는 교육이 이루어지도록 수행
– 데이터셋 인수 후 총 2일간 일별 4시간 교육(수요기업과 일정 협의) 일정으로 운영관리자와 유지보수관리자 구분하여 교육 진행 각 2시간 실습교육
– 운영관리자 (시스템개요) : 시스템의 전반적인 이해 및 프로세스 및 기능 사용법 교육유지보수 관리자 (시스템 상세내역 및 운영관리)
– 시스템개요
-시스템 구성 및 상세 설계 내역
– 시스템 구성 및 사용법
– 시스템에 적용된 개발툴(환경)에 대한 이해 및 유지보수를 위한 운영교육
– 운영자 지침서에 의한 사용법
– 시스템 기능을 토대로 한 운영교육
– 장애/응급사항에 대한 대처할 수 있는 복구 방법유지보수 계획
– 수리보수의 경우 최소 6개월 무상 유지보수
– 완전화보수, 적응보수의 경우 고객사와 비용 협의하여 진행하며 유무선 상으로 최대한 서비스 지원 - 카테고리 구분 : 전처리,품질,시각화,정보추출또는조합,태깅또는라벨링,분석
- 실적 : 2022년 데이터바우처 지원사업에 공급기업으로 참여하여 총 6개 수요기업에 데이터가공 사업 수행 완료 (AI 6개사)2019 데이터 표준 구축 업무
– 온라인 배포용 광고 문구 가공 (인비절라인코리아)2018 데이터 품질
– 판매사원 교육용 영상 데이터 품질 확보 업무 진행 (삼성전자판매) - 기업 개요 및 핵심역량 : 데이터바우처 사업 수요기업의 경험을 바탕으로 수요 기업의 요구에 정확히 맞춘 데이터 가공 능력약 15년 간 데이터를 기반으로 한 디지털마케팅 대행 경험과 노하우 보유(대표자 경력)2020년 데이터바우처 사업에 상반기 수요기업 인력으로 참여하여 성공적으로 사업 수행 (대표자 경력)당사는 2022년 데이터바우처 사업에 공급기업으로 참여하여 6개 수요기업과 협약 후 사업 수행 완료
- 활용 사례 : ‘데이터 기반 최적 전기차 충전소 검색 및 인프라 확인 시스템’을 위한 전기차 충전소 혼잡도를 예측하는 데이터셋 가공충전소별 대기시간, 예상 충전 소요시간, 혼잡도, 충전기 종류 등을 고려하여 지도 상에서 데이터를 보여줄 수 있는 가공 데이터와 요일, 시간대, 지역 별 충전소에 대한 정보를 인공지능 학습을 통해 미래 특정 시간, 지역에 대한 전기차 충전소 혼잡도를 예측하는 데이터 셋 가공세계 자동차 산업은 내연기관차에서 전기차로의 시장전환이 급격히 전환 중에 있으며 우리나라 정부에서도 전기차 관련 강력한 정책을 펼치는 중이고 전기차가 빠르게 보급되는 것에 반해 충전인프라 확충은 다소 지연되고 있으며 전기차 사용자간 갈등 증가세에 있으므로 이에 대한 데이터셋 수요가 상당할 것으로 예상됨당사는 대표이사가 관련 포털업체 재직에 따른 경험, 역량과 함께 개발 후 업계 네트워크를 시작으로 최종적인 소비자에게 효과적인 홍보와 마케팅을 진행할 수 있는 역량을 지님
영림원소프트랩 소개
- 영림원소프트랩은 1993-05-22에 설립되었습니다.
- 주소 : 서울 강서구 양천로 583 우림블루나인 비즈니스센터 A동 23층
- 주요 서비스 : 영업 분석
– 수주, 출고, 매출, 수금 등의 현황의 거래처, 제품, 부서, 사원, 유통채널별insight 제공제품/원자재 분석
– 제품과 주요원자재 간의 연관분석을 제공손익 분석
– 매출, 제조원가, 수익성 등의 현황의 거래처, 제품, 부서, 사원, 유통채널별insight 제공재무 분석
– 재무제표분석, 경영지표분석, 현금흐름표 분석을 통하여 insight 제공생산성 분석
– 수율, 불량현황 등의 제품별, 공정별 insight 제공구매 분석
– 구매단가, 구매거래처등의 현황과 구매이상징후 관련 insight 제공※ 나이스평가정보(주) 기업신용정보 데이터 연동 제공 - 보유 솔루션 : ‘K
-System AI경영분석’은 20년 이상 ERP전문가들의 실무 경험을 표준화한 분석모델과 AI기술을 융합하여 기업의 경영성과 극대화를 위한 정보를 제공합니다.[경영성과 극대화를 위한 다양한 분석모델]중요제품의 원재료 리스크 분석손익분석을 통한 수익관리모델재무제표 기반의 종합 경영 지표 분석구매부정 방지를 위한 구매이상징후 모니터링수금율 관리를 통한 중소기업 자금관리 효율화현금흐름분석을 통한 기업가치증대품질Cost 절감을 위한 불량원가 재 정의 및 전사적 관리단순하고 직관적인 생산이슈 파악현금유동성을 확보하여 최적 자금 운영을 위한 모델 제시 - 품질 확보 전략 : 샘플 데이터 생성 및 검증다양한 AI 알고리즘 검증을 위한 데이터 지원개발 및 운영 환경의 차이로 인한 리스크 점검산업 및 업종에 맞는 다양한 데이터 테스트
- 유지보수 전략 : 산업별 유지관리 컨설턴트를 운영함으로 고객 만족 실현시스템, 전화, e
-mail, fax 등 다양한 채널에서 AS 접수 가능하며 접수 시 신속 대응월간 서비스 처리내역을 기록/보관하여 분석 Report를 제공 - 카테고리 구분 : 전처리,품질,코딩,시각화,분석
- 실적 : 코스메카코리아 경영분석 납품외 국내 65개사에 영업, 제품/원자재, 손익, 재무, 생산성, 구매분석 서비스로 BI/경영분석솔루션을 컨설팅 및 납품
- 기업 개요 및 핵심역량 : 영림원소프트랩은 국내 ERP 시장의 선두주자로서 기업용 소프트웨어인 ERP를 연구, 개발, 제공하는 전문기업입니다.[기업 개요]글로벌 경영 혁신을 선도하는 ERP 플랫폼 기업30년간 축척된 노하우 보유, ERP 핵심 인력 확보, 각 산업별 맞춤 서비스 제공ERP 전문기업으로 국내 3위의 점유율을 차지, 2400여개 고객사에 ERP구축고객 니즈를 반영한 신규 서비스 매년 출시로, 안정적인 수익기반 확보AI 기반 기술 고도화로 서비스 고부가가치화[기업 현황]국내 최초로 한국형 ERP를 발표한 이후 WBS(World Best Software) ERP부문 선정,GCS(Global Creative Software) 프로젝트 선정, GS인증을 통해 대외적으로 기술력을 인정받고 있음[핵심 역량]안정된 사업 구조: 최적화된 산업별 서비스 모델 제공 확대 & 유지보수 서비스 강화로 안정된 수익성 유지ERP 전문 조직: 산업별 비즈니스 프로세스에 대한 깊은 이해를 기반으로 만든 모듈형 ERPR&D 역량: 다양한 업무 경험의 연구개발 인력, 다년간의 클라우드 및 솔루션 연동기술력 확보생산성 높은 자체 개발 도구 보유로 구축기간 단축을 통한 수익성 증대
- 활용 사례 : 빅데이터기반 수요예측KBot(챗봇)을 활용한 Self
-Service분석다양한 Machine Learning Algorithm을 활용한 예측 및 목표 관리외부지표를 활용한 상관관계 분석다양한 분석관점에서의 리스크관리관심 키워드 등록을 통한 뉴스 요약 분석
주식회사 써니마인드 소개
- 주식회사 써니마인드은 2021-12-27에 설립되었습니다.
- 주소 : 서울 강서구 하늘길 70 항공지원센터 2층 가꾼 B호
- 주요 서비스 : □ 데이터 가공 서비스 상세 정보써니마인드의[데이터 퐁퐁]은NLP모델 개발 전 단계(데이터 수집/가공/전처리/분석)에 관련된end
-to
-end서비스를 제공하고 있으며각 프로세스에 최적화된 다양한 접근방식 및 솔루션을 보유하고 있습니다.[데이터 퐁퐁]은수요기업의 개별 니즈와 비즈니스 요구사항에 최고로 적합한맞춤형 서비스 제공을 위한 초기 기획 컨설팅과 데이터 생산 및 기획 활용 등AI/NLP모델 개발 전 단계에 걸친 철저한 프로젝트 관리 체계를 보유하고 있습니다.①데이터 수집:수요처의 요구 사항에 맞추어 다음과 같은 다양한 데이터 수집 옵션을 제공합니다.(
1)프로젝트 도메인에 따른커스텀 웹크롤러 개발(
2) RapidAPI, Google Cloud NLP API등다양한API를 활용한 텍스트 데이터 수집(3)오픈 데이터 리서치 및 활용 지원②데이터 라벨링:작업 가이드 라인 작성 및 철저한 작업자 교육을 토대로,다음과 같은 다양한 데이터 라벨링 옵션을 제공합니다.(
1)클라우드 컴퓨팅 환경(AWS EC
2)에서SpaCy의Prodigy를 활용한 라벨링 시스템(
2)숙련된 전문 작업자 선발(3)크라우드 소싱 시스템을 통한 작업자 투입(4)세미오토라벨링(Semi
-auto Labeling)을 통한 반자동 라벨링 기술 활용③데이터 전처리:수요처가 필요로 하는 학습 데이터의 요건에 따라 다양한NLP기술을 통해 데이터 전처리를 수행합니다.(
1)데이터 토큰화(Tokenization)(
2)어간 추출(Stemming)(3)표제어 추출(Lemmatization)(4)불용어 제거(Stopwords)(5)특수문자 제거(Punctuation)(6)품사 태깅(POS Tagging)④데이터 분석:프로젝트 목적에 가장 적합한 데이터 분석 방법을 모색하고, NLP작업 유형에 따라 핵심적인 텍스트 분석 기술을 제공합니다.(
1)텍스트 분류(Text Classification)(
2)개체명 인식(Named Entity Recognition)(3)토픽 모델링을 통한 주제 추출(4)직관적이고 정교한 데이터 시각화※ - 보유 솔루션 : □써니마인드가자체 개발한 인공지능 자동리뷰분석SW는 최신AI/NLP기술인 전이학습(Transfer Learning)방법론을 활용하여 텍스트의 실질적인 내용 분석에 초점을 맞추어리뷰 퀄리티(Quality)및 콘텐츠(Contents)내역을 정확히 파악합니다.
□써니마인드가 개발한SW는속성기반 감성분석(Aspect
-based Sentiment Analysis)기술과리뷰 진정성 분석(Review Authenticity Analysis)기술,부정적/악성 리뷰 감지(Offensive Language Detection)기술 등 다양한NLP전용 인공지능 알고리즘 모델들을 장착하고 있습니다.따라서 저희 기업은영어 및 한국어 자동 리뷰분석SW서비스를 통해 초개인화 맞춤형 마케팅 및 고객관리(온라인 인지도 제고,고객 경험 관리,고객 만족도 제고,브랜드 평판 관리 등)서비스를 가능하게 합니다.
□써니마인드의[데이터 퐁퐁]은데이터 가공 및 개발 업무를 위해고성능GPU장착 개발 및 서버용 워크스테이션을 다수 보유하고 있으며,각 고객들의 니즈 충족과 비즈니스 요구사항 최적화를 위한다양한 환경의 클라우드 플랫폼 및SW들을 활용하고 있습니다.아울러 쾌적한 컨설팅/고객 응대를 위한 회의실 및효율적인 커뮤니케이션 도구들을 보유하고 있습니다.①장비 및 시설 현황
– 2 * GPU(RTX3080) PC 3EA
– 3 * GPU(RTX3090) PC 1EA
– Multi
-core CPU(Thread Ripper) Work Station 1EA
– WM65B 전자칠판 1EA②플랫폼 및SW현황구분품목명용도SW리뷰마인드AI리뷰분석SW (자체 개발)리뷰데이터 인공지능 자동분석SWSpaCy Prodigy데이터 라벨링데이터 분석클라우드 플랫폼NIPA고성능 컴퓨팅 자원 지원(25TFLOPS)데이터 분석모델 학습클라우드 플랫폼AWS EC2, SageMaker, Mechanical Turk데이터 라벨링모델 학습SaaS시스템 구축클라우드 플랫폼네이버 클라우드데이터 라벨링모델 학습데이터 분석APIRapidAPI, Google C - 품질 확보 전략 : □써니마인드의[데이터 퐁퐁]은다음과 같은데이터 품질 확보 전략을 바탕으로 철저한 데이터 생산 관리를 수행합니다.①작업자 선발 및 교육(
1)프로젝트 별 작업 가이드 라인을 구축하고 자사의LMS시스템을 활용하여 작업자 교육을 진행합니다.또한자체 선발용 테스트를 구축하여 통과된 작업자만 선별하여 작업에 투입하고 있습니다.(
2)프로젝트 참여 도중 자체 개발모니터링 시스템을 통해 작업 자격을 관리합니다.이때일정 기준치 미달 시 작업 자격을 박탈하여 품질 저하를 방지합니다.②품질 관리 방안(
1)자체품질 개선 프로세스를 통해 품질 진단/측정하여 개선 요건을 도출합니다.(
2)중복 데이터 처리 시스템 및 불합격 데이터 처리 기준 적용하여 불합격 데이터 이력을 관리하고 불합격 원인을 추적합니다.(3)품질 진단 및 측정 체크리스트를 도입하여 품질 검사 결과에 관한 보고서를 작성하고,이를 분석하여 가공 서비스 절차에 반영하여 품질을 향상시킵니다.③검수 전략(
1)전수 및 교차 검수를 원칙으로 하며,이에 자체 개발SW를 통해 분석을 진행하고AI기반 검수 알고리즘 및 모니터링 시스템을 구축하여더 정확한 검수 절차를 진행하고 있습니다.(
2)전담PM이 리뷰마인드 자체 품질관리 지표에 따라 각 검수 프로세스를 진단하며 보완합니다. - 유지보수 전략 : □[데이터 퐁퐁]유지보수 지원 전략
1)서비스 제공 계획 및 목표서비스 제공 방식 및 목표는 가공 계획 수립 시점에 기업과 협의하여 결정하고,이때협의된 내용으로 최종 납품 진행 및 검수 확인서로 상호 간 계약에 따라 결과물이 제공되었음을 합의합니다.
2)서비스 유지보수 및 고객 관리 방안서비스 유지보수 기간 및 내용,범위는 다음과 같습니다.구 분내 용유지보수 기간● 무상하자보수 기간:수행사업 종료일까지●유상하자보수 기간:무상하자보수 기간 후 협의하여 제공유지보수 내용●서비스 종료 후 관련 내용 이메일 및 유선 대응●가공 완료 데이터 이용 시 기능상 장애가 발생한 경우,해당 데이터 항목 수정/보완 조치●데이터 재가공이 필요하다고 협의될 경우,가능범위 내에서 재가공 수행추가적인 데이터 가공이 필요할 경우,협의 후 가능범위 내에서 추가 가공 수행●오프라인 지원 필요 시,해당 지역 다수 기업 통합하여 당일 방문 및 밀착 지원유지보수 범위●무상하자보수:공급한 가공데이터에 하자가 있는 경우,무상하자보수를 원칙으로 함●무상유지보수:무상 하자보수 기간 동안 일어나는 유지보수 활동●유상유지보수※수요기업의 실수 또는 천재지변에 의한 하자 및 장애에 대해서는 책임을 지지 아니함※무상하자보수 기간 중 신규 데이터 가공, AI모델 재설계 등을 요청할 경우,상호 협의하여 실비 제공을 원칙으로 함※유지보수 인력 이외의 인력이 수행한 데이터 수집,데이터 라벨링,데이터 전처리,데이터 분석 및AI모델 관련 서비스 등에서 문제가 발생한 경우에는 유상처리를 원칙으로 함 - 카테고리 구분 : 전처리,품질,코딩,시각화,정보추출또는조합,태깅또는라벨링,분석,기타
- 실적 : 거래처명거래/협약 시기판매 아이템데이터 유형㈜케이토픽2022.06.01.~2022.11.30.2022 데이터바우처 AI가공 서비스 공급TOPIK 문제은행 및 모범답안, 각 문항별 실제 학생 답변 이미지 데이터㈜아보룩스2022.06.01.~2022.11.30.2022 데이터바우처 AI가공 서비스 공급한국전통설화 1만여 개 데이터마이스터정보기술㈜2022.06.01.~2022.12.15.2022 산업맞춤형 AI인력양성 사업 공급 서비스기업내부문서
– Word(인력프로파일 데이터)수테크시스템즈㈜2022.06.01.~2022.12.15.2022 산업맞춤형 AI인력양성 사업 공급 서비스공공분야 웹 텍스트 데이터한국문화관광연구원2022.08.01.~2022.10.30.빅데이터 분석 기반 코로나 전후 한국 문화 및 콘텐츠에 대한 인식의 변화 연구 용역해외 언론사의 한국 관련 뉴스 기사 데이터한국표준협회2021.08.01.~2021.12.07.디지털 전환(빅데이터 분석 및 활용 부문) 교육 컨설팅 한국데이터산업진흥원2021.08.01.~2021.09.08.디지털 뉴딜 콘텐츠 기획 공모 장려상 수상 서울특별시2022.05.01.~2022.06.30.G밸리 산업박물관 관람VR 콘텐츠 제작 산업 트렌드 관련 기존 내부 보유 문서 - 기업 개요 및 핵심역량 : □ 주식회사 써니마인드(이하‘써니마인드’)는딥러닝AI및NLP, NLU기술 기반의 자동 리뷰 분석/고객관리/마케팅 서비스를 제공하는 AISaaS/API솔루션을 자체 개발한 경험을 보유한 벤처 기업입니다.자체 기술로 개발한 영어 및 한국어 인공지능 자동리뷰분석 솔루션 개발 및 운영 경험을 보유중이며,풍부한 다국어 자연어처리(NLP)전문AI모델 개발 프로젝트 경험과 노하우를 보유하고 있습니다.
□저희 기업은[데이터 퐁퐁]이라는 AI/NLP 데이터 가공서비스 브랜드를 보유,텍스트 데이터 수집 및 가공,전처리 및 분석, NLP용 딥러닝 및 머신러닝 분야에 특화된 대내외로 인정받은숙련된 기술성과 전문성을 바탕으로 다양한NLP인공지능 모델 개발을 위해 필요한 전 과정에서 고품질의 서비스 제공이 가능합니다.
□써니마인드의[데이터 퐁퐁]은비정형 빅데이터(언어/텍스트)에 대한 최신AI/NLP모델 및SW개발 기술을 보유하고 있을 뿐만 아니라,다국어 기반AI/NLP분야R&D기술 개발에 필수적인 데이터 및 기반 기술들을 확보하고 있습니다.따라서,저희 기업은 기술적 측면에서AI/NLP분야에서 국내 독보적인 수준을 자랑합니다.
□써니마인드의[데이터 퐁퐁]은사용자(수요기업)의 입장에서 고민하고 최선의 방안을 지원하는 고객 중심 기업으로서,수요기업에서 필요로 하는AI/NLP모델 개발 프로세스 전반에 걸쳐 빠르고 효율적인 데이터 생산 및 지원 서비스를 제공합니다.저희 기업은 항상고객의 입장에서 최고의 비즈니스 유용성 및 비용 효율성을 제공합니다. - 활용 사례 : □ 활용 사례
– 한국문화관광연구원: 한국 관련 외신 뉴스 기사에 대한 빅데이터 크롤링 및 AI데이터 분석
– ㈜케이토픽: 외국인을 위한 한국어 AI학습/평가 플랫폼 개발
– ㈜아보룩스: K
-콘텐츠 작가 및 기획자를 위한 한국 전통 설화 라이브러리 구축
– 수테크시스템즈㈜: 자사솔루션 고도화를 위한 AI인력양성 교육 프로젝트
– 마이스터정보기술㈜: 자연어처리 및 추천 모델 개발을 위한 AI인력양성교육 프로젝트
□ 저희 기업은 현재까지 질의응답, 감성분석, 텍스트 분류, 개체명 인식, 텍스트 요약 등 자체 보유한 다양한 NLP 기술들을 바탕으로 이를 필요로 하는 수요 고객들에게다양한AI 데이터 관련 컨설팅 서비스를 제공하고 있습니다.
사단법인 문화체육진흥(ko)008102720180108181000452 소개
- 사단법인 문화체육진흥(ko)008102720180108181000452은 2017-12-12에 설립되었습니다.
- 주소 : 서울 강서구 허준로 198 가양프라자 204호
- 주요 서비스 : 주요 서비스데이터 수집 / 전처리수집 : 메타데이터의 웹 크롤링 수집 / 네트워킹 인적자원 내 직접 수집 등전처리 : 원시테이터의 AI 가공을 위한 전처리 작업 (텍스트, 이미지, 영상)텍스트 / 이미지키워드 라벨링 / 문서 요약 / 바운딩박스 / 폴리곤 / 이미지 수집 등미디어(음성, 영상)Audio To Text / 태깅 / 분류 등
- 보유 솔루션 : □ 주요 서비스1.
주요 기술*클라우드 기반 크라우드 소싱 플랫폼 인공지능 학습용 대규모 데이터 가공 서비스
– 데이터 구축량 및 일정에 맞는 가변적인 클라우드 서버 운용.
– 데이터 수집, 정제, 가공, 검수 등 전체 과정에 대한 플랫폼 기반데이터 구축.
– 다양한 사업으로 확보된 대규모 인적 네트워크 확보.
– 크라우도 소싱 플랫폼을 기반으로한 대규모 크라우드 워커의 효율적인 관리.
– 인공지능 학습용 데이터를 위한 데이터 라벨링, 가공 및 품질관리.*스포츠 문화 확산을 위한 문화 컨텐츠 기획·연출·공연 서비스
– 청소년 캠프, 콘서트 등 문화체육 분야의 행사 연출, 개최, 진행
– 문화체육 분야의 강의, 공연 등의 촬영 데이터 수집*국민 건강 증진을 위한 문화체육 컨텐츠 공유 플랫폼 서비스
– 문화체육 분야의 영상, 음원 컨텐츠 및 플랫폼 제작
– 피트니스, 헬스케어 서비스를 위한 운동 데이터 수집 및 가공
– 스포츠 전문가 운동 영상 제작, 가공 및 미디어센터, 문화평생교육원 서비스 - 품질 확보 전략 : □ 가공 데이터 품질관리 프로세스
– 기획단계부터 서비스 제공 이후 사후관리까지 각 프로세스에 품질을 관리할 수 있는 체계 마련
– (기획) 수집 및 가공이 필요한 데이터의 정의.
실현가능성 파악.
요구사항 정의.
– (설계) 커뮤니케이션 방안.
데이터 수집 매뉴얼 수립.
오류 개선 절차 진행.
– (수집) 지속적인 교육과 수집 매뉴얼의 최신화.
리스크 모니터링.
– (검수, 가공) 사용자 교육 및 매뉴얼 최신화.
법률 검토 유효성 확인.
– (품질관리) 품질관리 조직 재편성.
검시기준 설정 및 체크리스트 마련.
– 공급기업과 수요기업 인력으로 재편성
– 유기적인 소통과 지속적인 모니터링으로 데이터 및 솔루션의 품질 유지
– 준비성, 완전성, 유용성, 기준 적합성, 기술 적합성 등에 근거한 측정 모듈 구축 - 유지보수 전략 : □ 수요기업 협업 체계
– 수요기업에게 본 사업이 규정하는 데이터 가공 서비스 제공에 그치지 않고 활용할수 있는 인프라 내에서의 네트워킹 및 기술적 컨설팅 활동을 지원함
– 최종 데이터 및 솔루션 활용에 있어서 지자체 및 공기관 등의 유관기관과 협력하여 활용할 수 있는 방안에 대해서 컨설팅함
– 수요기업들 간의 상호 정보와 경험의 공유가 가능한 기술교류회 및 워크숍을 주기적으로 개최함
□ 유지 보수
– 사업 완료 후 품질관리 조직을 재편성하여 데이터 품질의 유지
– 발생 하자에 대한 보수 책임자를 배치하고 신속한 대응을 위한 소통 창구 마련구분내용유지보수 범위
– 데이터 가공 서비스를 통해 수집 가공된 데이터
– 본 사업을통해 제공한 작업도구 등의 소프트웨어
– 데이터 활용을 위해 제공되 시각화 서비스 및 솔루션 등무상 유지보수
– 무상은 하자보수로 정의하며 단순 오류수정
– 사업완료 6개월 이내 발생 결함에 적용유상 유지보수
– 고객사의 과실 및 천재지변에 의한 사항
– 무상 유지보수 이후의 결함 및 장애금액
– 투입된 공수 기준의 별도 비용 협의 필요 - 카테고리 구분 : 전처리,품질,시각화,정보추출또는조합,태깅또는라벨링,기타
- 실적 : 수행년도사업내용소요예산(억원)지원기관2022인공지능 학습용 데이터 구축 사업(16번
– 한국어 대학강의 데이터 분야)17한국지능정보사회진흥원2022인공지능 학습용 데이터 구축 사업(28번 표 정보 질의 응답 데이터 분야)17한국지능정보사회진흥원 - 기업 개요 및 핵심역량 : □ 기업 개요* 국민 건강복지 증진 및 문화체육 인재 양성을 위한 ‘문화체육진흥원’
– 재능기부 문화 확산을 위한 한부모가정 및 저소득층 학생 소외계층 청소년을 대상으로한 스포츠 복지교육, 현장 체험 진행
– 노령층 건강증진을 위한 노령층 대상 스포츠 복지 교육, 체험 진행
– 체육문화 활성화를 위한 건강 콘서트 개최 * 콘텐츠 및 데이터 관련 사업 수행
– 온라인 평생교육원을 통한 문화체육 콘텐츠 제작 및 미디어센터 플랫폼 운영
– 콘텐츠 및 데이터 활용, 융합적 공익사업 실현을 위한 공익사단법인 심사 중
– 2022년도부터 인공지능 기반 문화체육 서비스를 위한 사업 확장
□ 주요 사업 및 핵심역량<;주요사업>* 국민건강증진 및 사회화합 분위기 조성을 위한 다양한 체육문화공연사업수행 경험
– 평생체육 연구 보급 및 확산
– 체육문화 공연 사업
– 융복합 스포츠 인재양성* 2022 인공지능 기반 문화체육 서비스 (인공지능 학습용 데이터 구축 사업)
– 한국어 대학강의 데이터 가공
– 표 정보 질의응답 데이터 가공<;핵심 역량>* 문화체육 콘텐츠 및 데이터 제작 역량
– 평생교육원 문화체육 콘텐츠 서비스 미디어센터 운영
– 문화체육 연극/공연 기획 및 콘텐츠 구축 역량
– 문화체육진흥원 이사진 및 체결된 MOU 등 다양한 인적 자원 보유* 수집, 정제, 가공, 검수 등 데이터셋 과제에 대한 인공지능 학습데이터 구축 경험
– 메타데이터 수집 가공을 위한 개발도구 자체 개발 역량
– 사업 운영을 위한 TF팀 조직 및 크라우드 워커 소싱
– 대규모 데이터 수집, 가공을 위한 인력 매뉴얼 제작, 교육, 배포 경험 - 활용 사례 : *2022년도 인공지능 학습용 데이터 구축 지원사업 2개 과제 수행중1.
표 정보 질의 응답 데이터 역할: 데이터 수집, 정제, 가공, 크라우드 워커 관리 데이터 수집: 표가 포함된 문서(pdf, hwp)의 웹 크롤링 데이터 정제: 정제 도구를 활용한 작업 가능한 데이터로의 변환 데이터 가공: 인공지능 학습데이터 구축을 위한표에 대한 질의 응답 정보 라벨링 2.
한국어 대학 강의 데이터 구축 과제 역할: 데이터 수집, 정제, 가공, 검수, 크라우드 워커 관리 및 운용 데이터 수집: 대학 강의 데이터 구입, 대학 강의 및 평생교육원 강의 데이터 녹음 데이터 정제: 구입,녹음 데이터로부터 음성 구간 분리 가공 데이터 가공: 인공지능 학습데이터 구축을위한 전사, 전문용어 태깅 등음성구간 라벨링 데이터 검수: 인공지능 학습데이터 품질 확보를 위한크라우드워커 교육, 관리, 데이터품질 검수.
주식회사 리스트 소개
- 주식회사 리스트은 2013-01-10에 설립되었습니다.
- 주소 : 서울 강서구 화곡로 416 (가양역 더스카이밸리5차 지식산업센터) 720호
- 주요 서비스 : 1.
공급기업 데이터 서비스 종류 및 상세 내용 가.
데이터 수집·정제·가공
– 전처리, 합산, 라벨링, 비식별화, 테이블 및 컬럼 표준화, 코딩 및 품질개선
– 지도, 그래프, 차트 등 분석 대시보드 적용을 위한 시각화 데이터 구축
– 콘텐츠 내 데이터 추출, 이미지 및 영상 등 멀티미디어 콘텐츠 어노테이션
– 수요기업의 요구사항에 맞춘 (일반가공) 또는 (AI가공) 진행 나.
AI학습데이터 구축
– 질의응답 및 대화기술 적용 인공지능 및 챗봇을 위한 데이터 가공·정제·구축
– 인공지능 추론모델 개발 및 적용 가능 데이터 가공·정제·구축
– 기계학습용 이미지 및 텍스트(메타데이터) 레이블링 등 데이터셋 구축
– 수요기업의 요구사항에 맞춘 학습용데이터 구축 솔루션 사용 및 (AI가공) 진행 다.
LOD 구축 및 컨설팅
– 지능형 데이터를 위한 온톨로지 데이터베이스 가공·구축
– Linked Data 구축을 통한 데이터 구조화 및 머신리더블 형식 가공
– 콘텐츠 메타데이터 연계를 위한 Linked Data 표준변환 및 인터페이스 제공
– 수요기업의 요구사항에 맞춘 (일반가공) 또는 (AI가공) 진행 라.
지식베이스(Knowledge base) 구축 및 활용 컨설팅
– 정형·비정형 데이터 가공·정제·분석 및 실시간 데이터 저장·처리
– 구축(납품)데이터의 자동 증강을 위한 데이터 수집체계 확보 컨설팅
– 챗봇 및 상용 챗봇빌더용 대화지식 구축
– SKT 및 KT의 스마트스피커용 지식베이스 납품 실적 보유
– 수요기업의 요구사항에 맞춘 학습용데이터 구축 솔루션 사용 및 (AI가공) 진행2.
데이터 서비스 주요 기술 가.
(일반가공) POI 데이터 정제 및 가공
-공급기업 보유 솔루션을 활용하여 국제좌표 고유번호인 EPSG로 좌표계 전환
-데이터분석을 용이하게 하기 위해 정제 데이터세트의 EPSG: 4326(Korea 2000 / Unified CS) 변환 작 - 보유 솔루션 : 1.공급기업 보유솔루션가.공급기업 보유 데이터 구축 도구“RichData”
-RichData는 효과적인 데이터 구축 및 활용을 위해 크라우드소싱(crowdsourcing)방식으로 데이터수집,가공 및 표준화 지원 데이터 구축 플랫폼
-이미지,영상,음성,텍스트 등 고품질 데이터 수집 및 가공(어노테이션,레이블링)
-인공지능 등 기계가 인식할 수 있는(machine
-readable)데이터 구축 및 모델링
-모바일 지원으로 시간과 장소에 구애받지 않고 비대면 일자리 창출 가능
-공급기업인 주식회사 리스트는 데이터 구축 플랫폼“RichData”와 관련기술을 보유하고 있으며 해당 플랫폼은2021년 부산관광공사의 관광분야 데이터구축 사업에 실제 투입되어 상용화 적용이 완료된 데이터 구축 도구
-데이터 구축단계에서 필요한 크라우드소싱 데이터 레이블러(어노테이션)인력풀은2019~2021년 데이터구축 프로젝트에 참여한 약20여 명을 보유하고 있으며,수요 증가에 따른 추가 작업자 필요시 고용노동부에 정식 등록된 인력수급 전문 에이전시인㈜아이시피를 통해 상시 수급나.공급기업 보유 데이터 구축 서비스“제보(jebo)”
-뉴스,공공민원,날씨 및 교통 애플리케이션 등으로 확인할 수 없는 빠르고 정확한 정보공유를 목적으로서비스 개발
-주변 생활 속 유용한 정보,민원사항 등을 사진 및 글 업로드를 통해 제보 플랫폼 내에서 실시간으로 확인 가능
-관심사 공유 및 소통을 넘어서 위험상황,날씨 변화 등 실시간 제반사항 정보를 가장 빠르게 획득할 수있는 플랫폼 역할 - 품질 확보 전략 : 1.
가공서비스의 품질 확보 전략 단계정의품질진단진단대상 정의○ 품질 이슈에 대한 수요 및 현황을 조사하여 품질 진단 대상 데이터베이스를 선정하고, 진단 방향성을 정의품질진단 실시○ 품질 진단 대상에 대한 품질진단 계획 수립 후 품질 진단 영역별 진단을 수요기업과 협의된 결과를 중심으로 실시진단결과 분석○ 오류 원인 분석, 업무 영향도 분석을 통해 개선과제를 정의 (단기 개선과제, 중·장기 개선과제 등)품 질 개 선개선계획 수립○ 품질 개선 과제별 개선 방향 정의 및 개선 추진을 위한 추진 계획을 수립개선 수행○ 상세 수준의 품질개선 계획 수립 및 개선 영역별 품질 개선 실시품질 통제○ 목표 대비 결과 분석, 평가를 통한 품질관리 목표 재설정 및 지속적 품질통제 수행가.수요기업의 요구사항과 데이터의 구조 및 값에 대한 기술분석을 통한 데이터 품질관리
-데이터 구축 시 데이터 표준의 적용 및 점검,데이터 구조의 일관성 확보,데이터 관리 산출물의 품질확보 등의 활동 수행나.품질 지표와 업무 규칙을 정의하고,이를 바탕으로 품질검사 기준을 마련해 실제 데이터를 진단하고 결과를 분석 및 수요기업과 협의
-공공기관의데이터베이스 표준화 지침·공공데이터 관리지침·공공데이터 공통표준용어(행정안전부 고시)및 공공데이터 품질관리 매뉴얼(한국지능정보사회진흥원, 2018.01.)등품질관리 기준에 따라 자체적으로 품질검사를 수행
-품질검사 결과 오류 데이터에 대한 개선 활동을 통해 품질확보 - 유지보수 전략 : 1.
수요기업 대상 서비스 제공 및 관리 계획가.수요기업 유지보수 지원체제역할담당자명이메일피드백 시간유지보수책임자임영숙 실장adagioys@li
-st.com영업시간 내 피드백 가능 (09:00~18:00)유지보수담당자정송인후 책임song.meraki@li
-st.com부심성철 주임scsim@li
-st.com나.수요기업 유지보수 지원내용구분내용유지보수 대상ㅇ 공급한 데이터의 모든 구성 데이터 요소를 대상으로 지원무상하자보수 기간ㅇ 사업완료 후 6개월간 지원유지보수내용하자보수ㅇ 검수 완료 후 6개월 이내에 발생하는 결과 데이터의 결함에 대한 유지보수ㅇ 데이터 납품 후 데이터 연관 장애발생 시 온·오프라인 지원품질개선ㅇ 납품데이터 자체의 문제점으로 인한 수정/보완, 목적물의 수정ㅇ 수요기업이 데이터 운용 중 장애 발생 시 데이터 재요청을 요구할 경우 무상으로 제공하여 업무 차질 최소화(단, 데이터 결함 발생 시)ㅇ 데이터 정상 운영을 위한 데이터 기술지원환경적응ㅇ 수요기업의 신규 데이터 운용 개선/확장에 따른 변동사항 시ㅇ 신규운영체제 및 개방 데이터 프로그램 추가 설치에 따른 변동사항 시유지보수범위예방점검ㅇ 데이터 유지 보수에 대한 교육, 기술지원 실시 (담당자 변경 시)ㅇ 예방정비 점검 활동 시, 정기점검 실시ㅇ 데이터 무상 유지보수 기간 중 연 2회 정기적 예방점검 진행무상하자보수ㅇ 공급한 데이터에 하자가 있는 경우는 무상 하자보수를 원칙으로 함유상유지보수ㅇ 고객의 실수 또는 천재지변에 의한 장애에 대해서는 책임을 지지 아니한다.ㅇ 무상 하자보수 기간 중 데이터의 기존 시스템을 변경하는 경우, 상호 협의 하여 데이터를 유지·보수를 제공함을 원칙ㅇ 유지보수 인력 이외의 인력이 수행한 데이터 개조, 첨가 및 조정 등으로 전달된 데이터에 중대한 영향을 끼친 경우에는 유상 처리(처리 금액의 경우 데이터의 범위에 따라 차등)ㅇ 하자보수 기간 중 새로운 서비스 혹은 새로운 운영환경으로 이식하는 경우 데이터 및 기술지원은 유상 제공(처리 금액의 경우 데이터의 범위에 따라 - 카테고리 구분 : 전처리,품질,코딩,정보추출또는조합,태깅또는라벨링,기타
- 실적 : 1.
데이터 서비스(데이터 가공) 주요 성과 가.
한국지능정보사회진흥원(NIA) 공공데이터 기업 매칭 지원사업 공급기업
– 2021년 6개 과제 中 1개 과제, 우수사례(Top 20)로 선정 (‘20~21 총 240개 대상)
– 2020년 3개 과제 데이터 구축 수행나.
한국데이터산업진흥원(Kdata) 데이터바우처 지원사업 공급기업
– 2021년 5개 과제(AI가공 1건, 일반가공 4건) 中 2개 과제, 우수과제로 선정
– 2020년 4개 과제(AI가공 3건, 일반가공 1건)
– 2019년 4개 과제(AI가공 2건, 일반가공 2건)다.
정보통신산업진흥원(NIPA) AI바우처 지원사업 공급기업
– 2021년 AI솔루션 제공 1건(어린이·청소년 체험활동 추천 솔루션)라.
과기정통부 빅데이터 플랫폼 및 센터 네트워크 구축사업 참여기업
– 2019년 문화·미디어 분야 빅데이터 플랫폼 데이터 융복합·가공마.
행정안전부 범정부 공공데이터 창업공모전 국무총리상 수상
– 2019년 전국 요양시설 주변 POI 데이터 구축으로 수상(수요기업 : 케어닥)2.
최근 3년의 주요 유사사업 참여 실적 및 성과 가.
2022 공공데이터 기업매칭 지원사업(국토안전관리원, 한국국제협력단, 인천관광공사, 한국수목원정원관리원, 여성가족부 / 총5개 과제)나.
2021 공공데이터 기업매칭 지원사업(한국문화예술위원회 3개 과제, 부산관광공사 2개 과제, 한국청소년활동진흥원 / 총6개 과제)다.
2020 공공데이터 기업매칭 지원사업(한국문화예술위원회, 한국청소년활동진흥원, 한국한의학연구원 / 총3개 과제)라.
2021 데이터바우처 지원사업(네버시티, 메드미디어, 서프홀릭, 밴플, 차봇모빌리티 / 총5개 과제)마.
2020 데이터바우처 지원사업(우림엔알,레드타이,모두컴퍼니,바로서비스 / 총4개 과제) - 기업 개요 및 핵심역량 : 1.기업 개요회사명주식회사 리스트사업자번호107
-87
-85562설립일자2013년 1월 10일 (설립 10년차)대표자오원석주소지서울특별시 강서구 화곡로 416, 720호 (가양역 더스카이밸리5차 지식산업센터)주요 사업
– 대용량 공공데이터 구축, 가공, 표준화 및 품질
– 데이터베이스, 소프트웨어 개발 및 제공업
– 기계주도 대화형 챗봇 등 인공지능 솔루션(ALVIS)
– 크라우드소싱 기반 인공지능 학습용데이터 구축
– 교육, 학술정보 제공 및 컨설팅(ISP)핵심가치“주식회사 리스트는 데이터의 잠재력을 세상과 연결시키고 있습니다”2.
주요 사업분야주식회사 리스트는 민간기업 및 공공기관의 데이터 활용에 대한 인식 제고와 확산, 그리고 데이터 기반 IT 서비스 산업 활성화 및 데이터 전주기 생태계 조성을 위해 양질의 지능형 데이터를 구축하고 이에 대한 활용방안을 제시합니다.
-주식회사 리스트의 주요 사업영역세부사업 분야상세 추진내용데이터 구축 / 품질확보 사업
– 공공데이터 구축 및 개방 지원사업
– 데이터바우처 지원사업기계학습용 데이터 가공 사업
– AI학습 데이터 구축사업
– 크라우드소싱 기반 지능형 데이터 구축사업인공지능형 챗봇 솔루션
– 인공지능을 활용한 사서 업무 지원도구 개발
– AI바우처 지원사업LOD 및 지식베이스 구축
– Linked Open Data 발행 및 응용서비스 개발사업
– 공공데이터기반 지식그래프 활용체계 구축사업 등 - 활용 사례 : 1.
공급기업 데이터 활용 사례가.
AI가공 사례
1)국제 가상전시 플랫폼에AI큐레이션을 적용하기 위한 데이터 가공(202
1), ㈜네버시티
-기존 가상전시관의 경우 작가가 작품을 선택하여 등록 시 직접300개 가량의 전시관 디자인 템플릿을 검색하여,직접 선택하도록 진행
-데이터 가공 및 적용을 통해서 개발된 색상기반 자동 추천 방식을 도입
-작품 등록 시 자동으로3개의 템플릿이 추천되며,반복 수행을 통해서 편의성 제공
2)메뉴 추천 서비스용AI학습 데이터 가공(2020),㈜레드테이블,3)스톡 비디오 정제 및 가공(2020),㈜트립클립나.일반가공 사례
1)밴라이프 지도 구축을 위한 전국POI데이터 가공(202
1),㈜밴플
-온라인RV렌트 중개 서비스 개발
-가공된 데이터를 활용해‘RV검색
-예약
-결제
-반납
-C/S
-정산’기능이 밴플 플랫폼 통해 모두 온라인으 로 통합되도록 서비스 개발
-리포트 및 챠트 확인 기능 개발
-일자별RV검색, RV세부 사양 및 사진 확인, RV결제 가능,보험료 포함된RV의 경우 보험료 포함 결제가능,결제완료와 동시에 예약 확정,취소/환불 가능
리더스경영지도사사무소 소개
- 리더스경영지도사사무소은 2020-03-16에 설립되었습니다.
- 주소 : 서울 강서구 화곡로61길 120 301호
- 주요 서비스 : ㅇ 제공되는 가공서비스
– 빅데이터 분석 : 지표 정의 및 트래킹, 탐색적 데이터 분석, 통계분석, 머신러닝으로 범위를 분류함, 통계 기반 데이터 분석을 통해 수집된 내/외부 데이터 및 정형/비정형 데이터를 활용하여 분석 목적에 따라 가설을 설정하고 필요한 데이터set을 편성하여 통계기반 데이터 분석 모델을 만들고 평가하는 업무를 수행함.
<;구체적인 빅데이터 분석 상세> (
1)지표 정의 및 트래킹(주요지표 개발/산출 및 리포트) (
2)탐색적 데이터분석(그룹별 평균, 합 등 현황 확인) (3)통계분석(가설검정, 모수추정, 변수 간 관계파악, 통계모형 구축) (4)머신러닝(분류 및 회귀 문제해결, 추천 및 이상치 탐지 등) 가공 서비스 구분 ■전처리 ■품질 ■코딩 ■시각화 ■정보추출 또는 조합 태깅/라벨링 ■분석 기타( )
– 텍스트 데이터 분석 : 다양한 형태의 텍스트 데이터로부터 고품질의 정보를 도출하기 위해 협업한 텍스트 데이터를 변환 및 정제하여, 추출된 단어 관계 및 패턴, 규칙을 분석함.
<;구체적인 텍스트 데이터 분석 상세> (
1)필요 단처 추출 및 문장 의미 분석 (
2)단어 빈도 및 연관성 수치계산, 텍스트 데이터 분석 프로세스기획 (3)텍스트 데이터 분석 모델 평가 및 구현, 토픽별 필요 단어분류 (4)긍정,부정, 감성분석 사전제작, 데이터 예측 기법
– 빅데이터 분석 결과 시각화 : 정보를 명확하고 효과적으로 전달하기 위해서 사용자가 분석 결과를 이해하기 쉽게 그래픽 의미를 이용하여 시각적으로 표현하고 전달함.
– 분석용 데이터 구축 : 빅데이터 분석을 위하여 수집 저장된 데이터를 분석용 데이터로 정제, 변환, 적재, 검증함. - 보유 솔루션 : ㅇ 빅데이터 분석 알고리즘을 통한 보유 솔루션
– 불량예측 알고리즘: 특정 설비가 불량품을 생산해낼 가능성을 계산하는 기계학습 기반의 알고리즘과 특정 제품이 불량품이 될 가능성을 계산하는 알고리즘을 적용 분석
– 설비 유효 잔여 수명 예측 알고리즘: 설비별로 수명에 영향을 주는 요인을 도출하며 각 설비가 고장나기 전까지의 남은 시간을 예측하는 알고리즘을 적용 분석
– 공정 패턴 파악 알고리즘: 공정 패턴을 도출하기 위한 시계열 데이터 군집화 알고리즘을 적용 분석, 데이터 군집화 알고리즘을 축적된 대용량 데이터에 적용하여, 대표적인 공정 패턴과 이상 패턴을 도출 - 품질 확보 전략 : 1.
품질 보증 계획 수립
– 기업의 업무환경 및 상황목표 수립
– 품질보증 목표 수립 및 활동계획 수립2.
품질 보증활동
– 형상관리(형상항목 식별)
– 산출물 검토 및 완성도 제고 전략3.
사후관리
– 서비스 품질평가
– 사업 종료 후 인수 시스템에 대한 유지보수 실시 - 유지보수 전략 : 1) 유지보수 전략
– 데이터 가공 분석 결과에 대한 정확도 향상과 분석 목적 달성을 위해 필요한 유지보수차원의 재분석과 재가공을 제공함
– 사업목표내의 데이터에 해당하며, 해당 데이터의 양의 증대나 항목의 변경에 해당하는 경우 유지보수 업무를 제공함
– 무상하자보수 기간은 사업종료 후 6개월로 함
2) 수행 방안
– 사업 완료 후 해당 기업의 데이터 가공 분석의 수행관련 책임자와 분석 담당자를 지정하여 하자보수 및 장애발생에 대하여 신속하게 대응하며, 유지보수 관리조직은 문제 해결을 위해 유지보수 절차에 따라 비상연락망을 구축하여, 사용자 지원창구를 통해 장애 접수 후 유지보수 전담인원에게 이관함으로써 일관성 있는 항시 지원체계를 유지한다. - 카테고리 구분 : 전처리,품질,코딩,시각화,정보추출또는조합,분석
- 실적 : 1.
사출공정 및 제품 선별공정에서의 주요 데이터 가공
– LOSS 데이터 분석 및 가공
– 품질향상 기여 요소 파악 및 데이터 분석
– 데이터 분석을 통한 Planning 역량 강화 - 기업 개요 및 핵심역량 : 리더스 경영지도사사무소는 데이터 가공 및 분석 분야와 관련된 컨설팅을 전문으로 하는 회사로 고객의 업무환경 및상황에 대한 최적의 데이터 솔루션 제공을 목적으로 수요기업의 품질불량저감, 생산성향상, 설비효율증대, 원가절감,수요예측 등 데이터분석을 통해 달성하고자 하는 목표를 파악하여 이를 수집/분석하고, 최근의 기술적 활용 자원(하드웨어 및 소프트웨어)과 현재 상태의 정보시스템과의 관계를 고려하여 해당 기업의 경영환경에 가장 적절하게부합할 수 있는 솔루션을 수요기업에 제공하는 회사임.
- 활용 사례 : 1.
ATP 측정데이터의 분석 및 가공
– 데이터 현황 분석
– 데이터 시각화2.
데이터 가공 도구
– 맞춤형 가공 도구 셋업

데이터바우처 사업관리 가공기업 정보
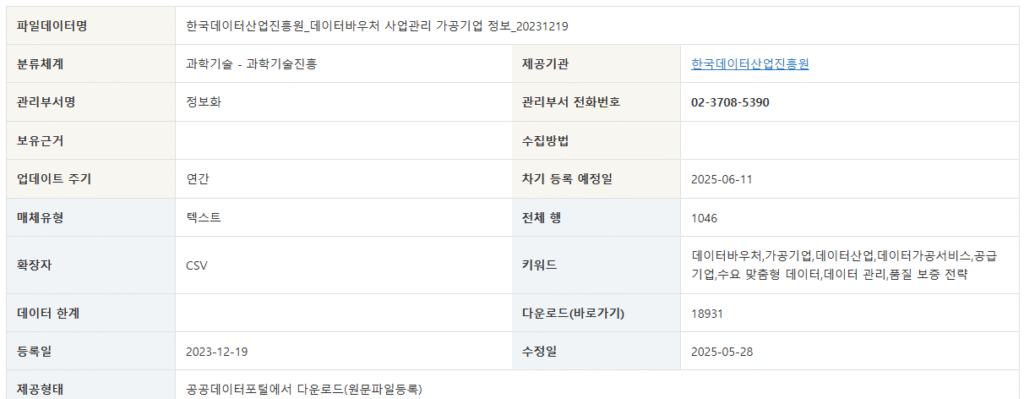
한국데이터산업진흥원 데이터바우처 사업을 통해 지정된 공급기업 중 데이터 가공기업 정보를 제공하고 있습니다. 본 데이터는 데이터바우처 지원사업에 참여하는 기업들의 정보를 포괄적으로 다룹니다. 특히, 수요기업이 필요로 하는 다양한 형태의 데이터 가공 서비스에 대한 정보를 제공함으로써, 데이터 활용의 범위를 넓히고, 기업의 데이터 기반 의사결정을 지원하는 역할을 합니다. 이 데이터가 보유한 컬럼은 다음과 같습니다.
기업한글명(문자형) : 해당 기업의 한글 이름
설립일자(날짜형) : 기업이 설립된 날짜
기본주소(문자형) : 기업의 본사 주소
상세주소(문자형) : 기업의 주소에 대한 추가 정보
주요서비스 상세정보(문자형) : 데이터 가공기업이 제공하는 구체적인 서비스 내용
보유솔루션(문자형) : 기업이 보유한 해결책 및 시스템에 관한 상세 정보
품질확보전략(문자형) : 데이터 품질 확보를 위한 기업의 전략
유지보수전략(문자형) : 데이터 가공 서비스 후속 지원 계획
카테고리구분(문자형) : 제공하는 데이터 가공 서비스의 카테고리 분류
등록일(날짜형) : 데이터가 등록된 날짜
실적(문자형) : 기업의 성과와 실적
기업개요 및 핵심역량(문자형) : 기업의 전반적인 설명과 주요 전문성
활용사례(문자형) : 데이터 및 서비스를 활용한 실제 사례
링크(URL) : 데이터에 대한 추가 정보 및 접근 링크
파일 다운받기
주요서비스 상세정보(요약), 보유솔루션(요약), 품질확보전략(요약), 유지보수(후속지원), 전략(요약), 실적(요약) 등의 일부 데이터 값은 데이터 미집계로 인해 공란이 있습니다.