
대전 서구 데이터바우처 사업관리 가공기업
대전 서구 에는 주식회사 나우닷, 미성정보기술, 주식회사 유클리드소프트 외 6개의 가공기업이 있습니다.
주식회사 나우닷 소개
- 주식회사 나우닷은 2015-09-08에 설립되었습니다.
- 주소 : 대전 서구 계백로 1135 5층 501호(가수원동, mk빌딩)
- 주요 서비스 : □자연어 분석 AI 가공서비스특성
– 자연어로 구성된 데이터를 전처리하여, 분석과 가공, 파생변수도출
– AI 모델링을 통한 자연어 데이처에더 자세한 분석과 예측
□자연어 분석 AI 가공서비스프로세스
1) 개발 모형 요건 정의
– 데이터를 전처리하여, 분석과가공, 파생변수도출이 용이하도록 데이터 가공
2) 데이터수집 및 분석
– 원천데이터 제공 주체 : 수요기업
– 데이터 종류 : 텍스트
– 데이터 유형 : Excel3) 반응변수 정의
-모형 개발에 적합한 정제된 반응변수 정의4) 데이터가공 및 추출
– AI 모델 학습에 용이하고, 자연어가갖고있는의미적 특성을 추출
– 텍스트마이닝(Text Mining) 기법을 활용하여 데이터를 가공함
– 분석 데이터에 나타난 자연어에 대해 핵심어를 추출함5) 학습데이터구축
– 분산된 데이터를 그룹별로 Grouping하여 학습 데이터를 구축6) 모형개발 및 학습데이터 검증
– 구분된 Label을 Target으로 설정
– 가공된 자연어 데이터를 통해 적절한 Label을AI 모델이예측
-Multi
-label classification 모델개발
– 빈도 기반 모델 · 주제 기반 모델 · BERT 기반 모델로 구분하여 그 성능을 평가
□데이터 가공
– 분석 대상 데이터는 대부분 항목이 자연어 형태
– AI 모델 학습에 용이하고, 자연어가갖고 있는 의미적 특성을 추출
-텍스트마이닝(Text Mining) 기법을 활용하여 데이터를 가공함
– NLTK Splitter: python package NLTK(Natural Language ToolKit) 활용한모듈로, 자연어를단어 단위로 분리
– MeCabTokenizer: 오픈소스 형태소 분석 엔진 MeCab을기반으로 하는 한국어 형태소 분석 모듈
– Sejong POS Lemmatizer: 주어 - 보유 솔루션 : □ 빅데이터 크롤링 및 수집 · 라벨링 자체 개발 프로그램 ‘유니업’ 사용
– 수요기업의 필요 데이터에 따른 컨설팅 진행 후 맞춤형프로그램 구현
– 기업요청에 따라 AI 가공 및 라벨링 진행
– 사전 컨설팅 진행 후 견적 결정
– 계약완료 후 서비스 절차 진행
□ 데이터 구축 및 컨설팅 서비스
– AI솔루션을 개발하기위해 필요한 학습데이터 수집, 데이터셋 작성 등 효율적인 데이터 라벨링 작업 수행을 위하여 가장 적합한 형태의 데이터 구축형태를 기획하고 컨설팅 서비스를 제공
□ 데이터 크롤링 및 라벨링 SW제공
– 텍스트데이터에 대한 라벨링 AI 기술을 개발하여 SaaS형태로 소비자에게 제공하고자하며 수동라벨링과 AI기반의 반자동 라벨링을 제공함으로써 소비자의 선택 폭을 넓힘
□ 데이터 수집 및 가공 전처리 가공데이터수집웹/포털 등 데이터크롤링Openapi활용 데이터라벨링AI데이터 가공을 위한 원시데이터라벨링작업숙련된 전문가 투입,반자동라벨링기술 활용(Semi
-auto Labeling)데이터 전처리수요처에서필요로 하는 학습데이터 요건에 따라 다양한 NLP기술을 통한 전처리작업
– Tokenization (토큰화 : 코퍼스에서 용도에 맞게 토큰을 분류)
– Cleansing ( 데이터 정제 : 코퍼스로부터 노이즈 데이터 제거)
– Normalization ( 데이터 정구화 : 표현방법이 다른 단어를 통합하 여 같은 단어로 생성)
– Steaming ( 어간추출 )
– Lemmatization (표제어 추출)
– Stopwords (불용어 제거)
– Puncuation (특수문자 제거)
– POS Tagging (품사 태깅)데이터분석수요처가 원하는 제품이나 서비스에 가장 적합한데이터 분석방법을 제공하여 적절한 정보와 기술 활용예측분석/분류분석/상관분석 - 품질 확보 전략 : □소프트웨어 품질관리체계 도입
– 높은품질의 소프트웨어 제공을 위한 시간적·비용적·품질 요소를 고려하여 개발부터 유지보수를 포함한 소프트웨어의 전주기를체계적으로 관리하고자 함
-품질계획→품질평가→품질관리 과정에서 **대학교 정보보호학과 연구실과의 협업 진행
□보안유지체계
– 협력적보안체계 확립 : 보안체계 마련을 위한 **대학교 정보보호학과 시스템보안 연구실과의 협업
-보안담당자 지정 및 내부 보안 관련 규정 수립
– 대외비문서 관리
– 입·퇴사자 기술 관련 비밀 유지 계약 및 관리
– 직원대상 주기적 기술 보호 예방 교육 진행
– 기술보호 법적 장치활용
□
□성능지표 관리를 통한 품질확보주요성능목표설정근거목표시스템 기능시험표준기술인증인증AI모델 정확도국내최고수준90%ㅇAA - 유지보수 전략 : □AI 가공서비스 추진 체계 설정1.
사업기획 (계획수립/자료조사/요구사항분석)2.
데이터분석 (데이터수집 및 분석/데이터응용결합/2차 데이터 생성 및 검증)3.
모델개발 (AI 모델 개발 / 반복모델 개발/ 라벨링 솔루션 제공)4.
성능평가 (시뮬레이션/종합테스트 및 검증/결과보고)
□고객 전담인력 신규고용 인력확충
□ 프로젝트 별 PM, QM 배정을 위한 교육 및 전문성 강화 - 카테고리 구분 : 전처리,품질,코딩,시각화,정보추출또는조합,태깅또는라벨링,분석
- 실적 : □실적
-22년인공위성 데이터 수집 및 분석
-22년한국해양과학기술 제주 지형 데이터 수집 및 분석
-22년종자별데이터 라벨링
-21년한국기계연구원 롤투롤해석 및 데이터 라벨링
-21년AI 교육프로그램 개발 및 교육데이터 수집, 라벨링 , 분석
-21년SNS 광고마케팅업 고객 데이터 셋 구축 및 크롤링개발
-21년AI 진로 탐색 어플리케이션 개발, 진로데이터AI가공 및 품질검사
-21년데이터 분석 플랫폼 개발 Nexacro(UI툴), UbiReport(레포트툴) , 데이터분석 개발툴개발
-20년한국항공우주연구원 : 데이터 변환 시각화
-19년맞춤 대입 프로그램 개발 및 대입데이터 수집 및 라벨링
-19년데이터베이스 구축 및 고객맞춤 프로그래밍 설계
-19년대구창조경제혁신센터 DB설계및 프로그래밍 - 기업 개요 및 핵심역량 : □기업개요
-4차산업혁명의 기반을 만드는 핵심 원천기술 D.N.A.(Data·Network ·AI)와이를 기반으로 하는 다양한 제품과 서비스를 개발·제공
-데이터 수집 ·가공, 전처리, 분석, AI 알고리즘, 서비스개발 · 제작 및 컨설팅의 모든 과정을 우수한 인적자원을 통해 자체적으로수행
-AI 자연어처리 기술을 기반으로 한 데이터 가공 서비스 ‘유니업'을통해 텍스트 데이터 수집, 정제, 가공, 관리전처리및 분석을 통한 알고리즘 모델링 개발과 같은 숙련된 기술성과 전문성을 바탕으로 고품질의 서비스를 제공
□기업연혁
-2020년빅데이터 ·AI 사업부 신설
-다년간 다양한 기업 및 기관과의 협력을 통한 다양한 AI학습데이터및 기획 개발 사업 능력 검증
-텍스트, 이미지등을 활용한 AI 학습데이터 사업 노하우 및 개발 전문 인력 보유
-데이터 수집 및 정제, 라벨링 작업은 크라우드 워커(Crowd Worker)와 진행하며 수년간 인원 변동 없이 자사의 데이터 작업환경에전문화 되어 검증 및 검수 작업 최적화 - 활용 사례 : □ 데이터 전처리 (가공)
– 고객사의 데이터를 기반으로 원하는 방향, 목적 및 문제해결을 위한 데이터 정제 및 전처리
□ 데이터 분석 및 시각화
– 고객사의 요구사항 및 데이터 분석을 통한 적합한 모델링 기법 제안
– 고객사의 데이터를 기반으로 문제를 정확하게 이해하기 위한 시각화
□ 데이터 기반 AI 모델 및 컨설팅 서비스
– 고객사의 데이터를 기반으로 문제를 해결하기 위한 데이터 모델링
– 해당 문제를 해결하기 위한 데이터가 없는 경우 데이터 수집 방법 제시
– 고객 도메인에 최적화된 시각화 서비스 인프라 설계 지원
미성정보기술 소개
- 미성정보기술은 2019-02-11에 설립되었습니다.
- 주소 : 대전 서구 계백로860번길 58 201호
- 주요 서비스 : 5.
가공서비스의 상세정보
1)가공업무 소개○ 가공 방법론 소개
– 체계적인 가공업무 관리 : (주)미성정보기술의 데이터 가공방법론 정립 및 적용다년간 빅데이터 가공분야에서 경험한 가공기술/지식을 정리하여 가공업무의 분석/설계/구현 단계별 고유의 가공방법론을운영함으로서가공업무 관리 및 실행, 검증을 위한 최상의 가공서비스를 제공합니다.① 가공업무 분석 단계 : (주)미성정보기숭 고유의 가공업무 관리방법론 업무 목적&계획, 데이터 수집, 가공 실행과정, 최종결과물 등을각업무단계에 대한 진행 업무기술② 가공업무 설계 단계 : 다년간의 전문 경험을 토대로 가공 단계별 업무정의 가공업무 종류 데이터 다듬기(식별, 추출, 정제) 데이터개선(대체, 보강, 투영), 개선된 데이터의 활용목적에 맞게 변환(변환, 요약), 오류 및 확인(참조, 검증)로 구분하여 관리③ 가공업무 구현 단계 : 가공기법들을 기술요소별 계층적 구조로 체계적 정리 구조화된 스크립트 가공 단계별 모듈형 구조의 데이터 가공전용 언어 적용.
모든 가공 업무를 모듈화 함으로서 가공 업무를 체계적으로 관리, 가공결과물의 품질을 보장합니다.
2)가공업무 상세 소개 (주)미성정보기술의 가공 업무는 총 5가지의 업무유형을 제공합니다.
수요기업의 요구사항에 맞게 각 업무단계를 적절히 조합하여가공 업무를 진행하게 됩니다.가공 솔루션개요기능라이센스이용여부공간연산(gLoader)
– 공간연산/편집공간정보 개발/가공에 필수적으로 요구되는 공간연산 및 공간정보 수정기술
– 좌표변환/블록배정GIS 서비스개발에서 요구되는 좌표변환 및 블록 배정
– 좌표추출 및 블록조회·블록생성/수정·공간연산·좌표변환·블록배정·좌표추출·블록조회이용(자체 개발)텍스트마이닝(ExtrText)SNS 데이터나 비정형문서 데이터에서 키워드 특성 및 연관성분석·정규표현식처리·키워드 추출이용(자체 개발)크롤링(WebCrawler)웹 페이지상의 특정 영역 정보 크롤링 및 데이터 구축·웹 크롤링 로직·웹 크롤링 정보 구축이용(자체 개발)Qlikvie - 보유 솔루션 : 6.데이터 가공 솔루션S/W 소개○ 가공솔루션S/W 스펙, 범위, 개요가공 솔루션개요기능라이센스이용여부공간연산(gLoader)
– 공간연산/편집공간정보 개발/가공에 필수적으로 요구되는 공간연산 및 공간정보 수정기술
– 좌표변환/블록배정GIS 서비스개발에서 요구되는 좌표변환 및 블록 배정
– 좌표추출 및 블록조회·블록생성/수정·공간연산·좌표변환·블록배정·좌표추출·블록조회이용(자체 개발)텍스트마이닝(ExtrText)SNS 데이터나 비정형문서 데이터에서 키워드 특성 및 연관성분석·정규표현식처리·키워드 추출이용(자체 개발)크롤링(WebCrawler)웹 페이지상의 특정 영역 정보 크롤링 및 데이터 구축·웹 크롤링 로직·웹 크롤링 정보 구축이용(자체 개발)Qlikview·In
-Memory를 통한 빅데이터 분석 ·다양한 데이터 소스 융합/가공·다양한 분석 기능 제공·정보공유 포탈기능·분석템플릿 공유·공동분석 의사결정이용(정식 Qlik Partner)SQREAMGPU를 사용하는 새로운DW아키텍쳐·데이터 처리 플랫폼·전처리 시간감소·페타바이트 급 RAW DATA분석가능이용(충청 총판) - 품질 확보 전략 : 2.
판매 데이터(또는 가공서비스)의 품질확보 전략 ○ 고객관리 및 고객 응대 체계화 및 인력 강화
– 가공업무 이외에, 고객의 요구사항을 체계화하고 지속해서 관리하기 위한 운영시스템 확보
– 별도 조직으로 업무기획팀을 운영하고, 바우처 사업규모 확대에 따라 탄력적으로 인력을 변동시킴으로써 고객사의 요구사항을 가공단계및 유지보수 단계에서 원활히 적용될 수 있도록 관리○ 수요기업 대상 상담 및 컨설팅 제공 계획
– 수요기업은 Datastore 포털 등을 통해 필요업무에 맞는 가공업체를 검색
– 당사는 수요기업에 대해 1차 E
-mail상담, 전화상담, 방문 인터뷰를 통해 수요기업이 데이터 가공을 통해 원하는 목적을 정확히 파악하고 사전 컨설팅 서비스를 제공Contact DataStore Q&A 매칭데이→ 데이터 가공/분석이 필요한 수요기업들은 Data Store를 통해 필요업무에 해당하는 업체 검색(Q&A활용) 오프라인으로 진행되는 매칭데이에 당사 부스를 마련하여 상담진행Online 유선 E
-mail→ 수요기업과의 상담을 유선 및 E
-mail로 1차 상담진행 수요기업의 보유데이터, 가공/분석/활용목적, 최종서비스 등 니즈를 파악 가공/분석 서비스에 대한 업무 프로세스 설명Offline 인터뷰 방문 및 회의→ 온라인으로 진행된 내용을 바탕으로 대략적인 진행방향 및 예상 내용을 바탕으로 방문, 인터뷰 수요기업의 데이터 현황 및 상태파악 수요기업의 구체적인 목표를 담당자와 회의 소요비용 및 기간 협의 전문가활용 방문 및 인터뷰→ 수요기업의 가공/분석 결과물에 대한 활용에 대해 본사 자문위원과의 미팅을 통해 컨설팅 제공 분석결과를 활용한 서비스ㅡ 등에 대한 방안을 전문가와 진행○ 품질관리 방안 및 계획
-수요기업의 니즈를 파악 후 분석을 진행하고 이를 주간 또는 월간으로 정기적인 회의를 진행
– 프로젝트의 진행상황과 방향성을 공유하여 변경이나 추가되는 사항들을 실시간으로 반영
– 품질관리를 위한 담당인력을 확보 후 가용하여 운용계획 - 유지보수 전략 : 3.
수요기업 유지보수(후속 지원) 및 협업체계 전략 ○ 매칭 후 수요기업과의 역할 분담 방안
– 데이터 가공은 당사와 수요기업 간의 긴밀한 Communication을 바탕으로 진행됨
– 수요기업은 보유한 데이터에 대한 설명, 데이터 가공을 통해 얻고자 하는 목적, 데이터 가공결과의 활용방안 등에 대해 충분한 설명을 제공해야 함
– 협약 이후 데이터 가공업무가 진행될 때는 단계별로 수요기업에 중간결과물을 제공하며, 수요기업은 이에 대해 검증 후 검토의견을제시해야 함㈜미성정보기술↔수요기업DataStore 등록매칭데이 참석 회사소개자료→가공기업조회상담 및 방문, 회의진행 가공업무 상담→가공기업선정매칭 및 계약가공요건 정의←가공요구정의서 데이터샘플→분석 및 가공범위 기술협상데이터 정제/표준화←정제/표준화 데이터 원천데이터→정제/표준화 데이터 검수데이터 가공/융복합←가공/융복합 산출물 데이터 검수결과서→가공/융복합 데이터 검수최종 데이터 제공←최종데이터 데이터 검증 산출물→최종 데이터 검수계약종료 및 교육○ 유지보수(후속지원) 및 협업체계 계획
– 정기적인 니즈 파악 : 월별, 분기별 추가적인 수요를 파악
– 기존 결과데이터에 대한 오류 및 애로사항 발생시 프로젝트 참여인원으로 신속한 처리
– 수요기업의 데이터 수요증가에 맞추어 품질 / 가공 / 보수 인력을 추가로 편성계획 - 카테고리 구분 : 전처리,품질,코딩,시각화,정보추출또는조합,태깅또는라벨링,분석
- 실적 : 4.
사업실적연번사업명사업개요사업기간발주처정제 /표준화가공 /융복합분석 /컨설팅1교통카드 통행행태 분석을 위한 자료 처리 및 분석빅데이터 분석2019.06~2019.08한국교통연구원OOO2대전광역시 관광 및 복지분야 빅데이터 분석사업빅데이터 분석2019.08~2020.01대전광역시 OO3정책자금 온라인 운영환경 구축시스템 구축2020.04~2020.05소상공인시장진흥공단O 4코로나19대응 긴급재난생계지원금 DB구축사업데이터 구축가공/융복합2020.04~2020.07대전광역시OO 5대전빅데이터센터 설립 정보화 전략 수립 연구용역(ISP)사업빅데이터 분석2020.07~2020.09대전광역시 OO62020년 공공데이터 기업매칭 지원 사업(주차, 교통분야 빅데이터 분석)빅데이터 분석2020.06~2020.12NIAOOO72021년 공공데이터 기업매칭 지원 사업 (데이터 기반 행정 및 대시민 데이터 활용 활성화를 위한 경제·교통분야 공공빅데이터 구축)빅데이터 구축2021.06~2021.12NIAOOO - 기업 개요 및 핵심역량 : 1.
기업 개요 및 핵심 역량 ○ 사업 개요 ·데이터 수집, 가공, 분석, 시각화, 컨설팅 등 데이터 비즈니스 전문기업(주)미성정보기술은 빅데이터 분석, 학술연구용역, 시스템구현 및 공간데이터에 대한 데이터수집, 데이터가공, 데이터융합기술,시각화 및 전략 컨설팅/모델링을 수행하여 공공 및 민간에서 필요로 하는 Business Intelligence를 지원하는 서비스를 제공하고있습니다.○ 가공업무 인력 현황 구분계전문분야경력합계7111 고급기술자411210~12년중급기술자1
-1
-6~9년분석위원2 213~20년○ 보유한 데이터 가공 솔루션의 특징 소개(주)미성정보기술은 빅데이터 분석 분야 사용되는 In
-memory방식의 BI솔루션 Qlik사의 Qlikview의 파트너쉽을 맺고 있으며 GPU기반데이터 분석 플랫폼인 SQream의 충청지역 총판 지위를 획득하여 공급하고 있습니다.솔루션개요 및 특징공간연산(gLoader) 개요 : 공간정보 개발/가공에 필수적으로 요구되는 공간연산 및 공간정보 수정기술 GIS 서비스개발에서 요구되는 좌표변환 및 블록 배정 좌표추출 및 블록 조회 특징 : ① 블록정보 생성 및 수정 ② 필수 공간연산 기능 제공 ③ 다양한 형태의 좌표변환 기능 ④ 블록배정 기능 ⑤ 지도상에서 좌표추출 ⑥ 블록정보 표출 및 블록 내 속성정보 조회 기능텍스트마이닝(ExtrText) 개요 : SNS 데이터나 비정형문서 데이터에서 키워드 특성 및 연관성분석 특징 : ① 정규표현식 분석, 등록기능 ② 키워드 추출 기능크롤링(WebCrawler) 개요 : 웹 페이지상의 특정 영역 정보 크롤링 및 데이터 구축 특징 : ① 웹페이지 크롤링 로직 구현 ② 웹 크롤링 및 정보 구축분석솔루션(DataAnalysis)
1) Qlikview 개요 : 대용량 소스 데이터를 대상으로 별도의 DB 구축 없이 In
-Memory 방식 지원으 로 빠른 이관 및 - 활용 사례 : 7.
활용사례
1) 교통카드 통행형태 분석을 위한 자료처리 및 분석 (한국교통연구원 분석사업)STEP 1기존 교통카드자료(수단통행)을 통행사슬(trip
-chain, 통행목적)형태로 가공변환STEP 2환승순서 확인 후 순서정보 미확인 데이터 정제STEP 3승하차 자료 미확인 데이터 정제STEP 4실제 총 탑승시간 및 환승 대기시간 산출
2) 대전광역시 관광 및 복지분야 빅데이터 분석사업 (대전광역시 분석사업)STEP 1데이터 보정 프로세스
-외래관광객은 외국인 데이터에서 한국 단기체류 추출, 국적별 보정 통해 데이터 산출
-국내관광객은 LTE계약자에 MS보정, 국적별보정, 휴대폰 On비율보정 통해 데이터 산출STEP 2방문객 분석
-내국(외지,내지), 외국, 숙박 관광객 분석STEP 3관광뉴스 감성분석(웹크롤링, 워드클라우드)STEP 4복지분야 복지 우선지역탐색(생활SOC) 분석데이터 목록
– 대전시 복지데이터, 건강보험공단 의료데이터 가공, 융합 분석STEP 5복지분야 복ㅈ지 우선지역탐색(생활SOC) 분석STEP 6분석보고서 외 분석요약보고서(GIS시각화)작성 및 관련부서 배포
주식회사 유클리드소프트 소개
- 주식회사 유클리드소프트은 2014-04-28에 설립되었습니다.
- 주소 : 대전 서구 대덕대로317번길 20 4층 유클리드소프트
- 주요 서비스 : 데이터 수집 및 전처리,데이터 가공데이터 수집웹/포털 등 데이터 크롤링 수집전처리AI데이터 가공을 위한 원시데이터 전처리 작업데이터 가공텍스트태깅, QA셋,요약기계독해(2020~202
1)사업을2년 연속 진행하며 자연어를 이용한 질의응답 생성 작업의 전문성 갖춤2021년, ‘요약 텍스트 데이터 구축’사업을 진행하며10개의 클래스에 대한 가공작업을 수행함이미지B
-box, Polygon,키포인트, OX분류라벨링 작업을 진행하며 저작도구의 업데이트와 정확한 작업 가이드제작이 가능함3D데이터키포인트, B
-box3D데이터를 가공하여,개체에 대한 키포인트 및3D B
-box수행멀티모달VQA,비디오 튜링테스트전통적 텍스트 외에 여러 입력 방식을 융합하는 입력 기술로서VQA와 비디오Narrtive과제 진행 - 보유 솔루션 : 크라우드 소싱 기반의 오픈 플랫폼’LabelOn’
– ’10만 회원’을 보유한 플랫폼
– 30명으로 구성된 인하우스 기반 ‘전문 검수팀’
– 15명으로 구성된 ‘라벨온 전담 개발팀’
– 인공지능 학습용 데이터 전 유형의 저작도구 보유
– 데이터 특성에 맞는 저작도구의 커스텀 가능
– 데이터 수집부터 최종 정산까지 구축의 전 과정을 지원하는 ‘올인원 시스템’
– 실시간 진척률 확인이 가능한 대시보드 기능과 품질, 정산 등 프로젝트 운영을 위한 사업관리 기능을 포함비정형 데이터 검수 플랫폼 ‘LIME
-DQM’
– 체계적인AI학습용 데이터 품질관리 솔루션으로서200여개 이상의 데이터 검증 모듈
– AI학습용 데이터 생성부터 이후 전주기 지속적인 관리 기능 가능 - 품질 확보 전략 : 품질제고 방안
– RFP를 근거로WBS작성을 실시하며 그에 맞는 데이터 구축 방법을 구상하고,법적 문제 및 리스크 발생 시 적절한 프로세스 준비
– 지속적인 교육과 최신 가이드 제공을 통해 데이터의 품질을 지속적으로 관리
– 검수(인력) 자체 검수팀을 운영하여 작업자가 생성한 작업물 검수
– 검수(SW) LIME
-DQM을 활용하여품질진단 단계 개선 및진단 단계별 피드백사업 단계별 품질관리 프로세스
– 수집된 데이터를 가공 과정의 프로세스,작업 가이드,오류 개선 활동을 중심으로 품질 관리
– 가공 데이터 검수 단계에서 프로세스,도구,조직 체계를 검토하여 일정한 품질의 데이터셋 구축 결과 도출가공 데이터 검수 프로세스
– 데이터 가공 도구를 활용이 가능한 자체 검수 인력 활용
– 비정형 데이터 검수 플랫폼인 LIME
-DQM을 활용한 가공 데이터 품질 강화 - 유지보수 전략 : 유지보수 전략
– 사업 완료 후 프로젝트 및 가공 프로세스의 이해도를 가진 하자보수 책임자 지정
– 하자보수 발생에 대한 신속한 대응과 문제 해결을 위한 비상 연락망 구축무상유지보수대 상
– 사업완료 6개월 이내 발생하는 응용프로그램의 결함에 대한 하자보수
– 가공 가이드라인에 맞지 않게 가공되어 재가공이 필요한 데이터내 용
– 공급한 시스템 오류에 대한 개선
– 가공 가이드라인에 맞지 않는 데이터 대상 재가공
– 프로그램 장애 발생 시 발견한 결함 및 장애 복구유상유지보수대 상
– 고객사의 실수 또는 천재지변에 의한 시스템 장애
– 무상유지보수 기간 경과 후 발견한 하자
– 유지보수 인력 외 인력이 수행한 시스템 개조 증으로 시스템에 영향을 끼친 경우내 용
– 기능 설계의 오류로 인한 기능 수정/보완 (비용 별도 합의) - 카테고리 구분 : 전처리,정보추출또는조합,태깅또는라벨링
- 실적 : 주요 유사사업 실적
– 2022년 S사 자율주행 솔루션 강화를 위한 자율주행 데이터 구축을 수행 하였으며, AI 학습용 데이터 구축 사업에서 유클리드소프트가 참여한 사업은 ‘대규모 시각 추론 학습 데이터’, ‘표 정보 질의응답 데이터’, ‘지능형 양봉 데이터’, 금융,법률 문서 기계 독해 데이터’, ‘외부 지식 기반 멀티모달 질의응답 데이터’, ‘자연어 기반 질의(NL2SQL) 검색 생성 데이터’, 소(한우,젖소) 및 돼지 발정 행동 데이터’로 당해2625만 건의 데이터를 구축하여 3년간 총4806만 건의 데이터 구축을 수행
– 2021년 AI 학습용 데이터 구축 사업에서 유클리드소프트가 참여한 사업은 ‘스마트팜 통합 데이터(버섯)’, ‘스마트팜 통합 데이터(양계)’, ‘Ego
-Vision 관점의 2D, 3D 손 움직임 데이터’, ‘비디오 Narrative’, ‘매체별 기계독해 행정문서’, ‘요약문 및 레포트 생성 데이터’로 당해379만 건의 데이터를 구축
– 2020년 AI 학습용 데이터 구축사업에서도 ‘시각정보 기반 질의응답 AI 데이터 구축’, ‘교통안전 AI데이터 구축’, ‘국어 텍스트 AI데이터 구축’, ‘생활 및 거주환경 AI데이터 구축’ 사업을 수행하여 당해1802만 건의 데이터를 구축 - 기업 개요 및 핵심역량 : 기업개요
– 2018년 빅데이터·AI사업부를 신설하며,특허3개와 저작권1개 이상 보유
– 2019년 빅데이터 분석 및AI R&D연구기업으로 성장하며, 다양한 인공지능 데이터 플랫폼 사업 수행
-다년간 다양한 기업과의 협력과 사업목표 달성을 통해 기업의 사업 협업능력이 검증됨
– 텍스트,이미지,영상,동작 등을 활용한AI학습 데이터 사업 노하우와AI데이터 기획 및 개발 전문인력 보유
– 10만 회원을 보유한 인공지능 학습용 데이터 구축 플랫폼 ‘LabelOn’을 운영 - 활용 사례 : 고객 AI 솔루션의 현장 최적화를 위한 데이터 커스텀 서비스를 제공하여 솔루션의 고도화 효과를 기대할 수 있음[기타수행 사례]
-AI(인공지능)를 활용 동영상에서 특정 사물 인식방안 컨설팅
-중,저준위 방사성 폐기물 핵종 연관성 분석 및 빅데이터 전략계획 수립
-데이터 바우처 일반 가공과 인공지능을 위한 자동화 프로그램 개발
– 시각 탐지 데이터 품질검증
– 시각 탐지 데이터 어노테이터 교육 영상 제작
– 인공지능 기반의 우리동네 쓰레기 무단 투기 관리 시스템 개발
캐치어스 소개
- 캐치어스은 2018-04-03에 설립되었습니다.
- 주소 : 대전 서구 도안북로 88 창업진흥센터 404호
- 주요 서비스 : 캐치어스는 사업예산과 업무 성격에 최적화된 개발 방법론을 통해 안정적 사업관리 기법을 보유하고 있음.특히, 특허, 기술, 기술사업화, 경영, BM 검토에 있어 전문성을 갖추고 있으며, 관련 전문위원 Pool 구축을 통해 사업 수행의 우수성을 보유하고 있음 ○ 대리인 정보 제공
– 대리인의 등록률 추적/조회
– 대리인의 출원수임건에 대해 법적상태를 제공하고, 등록률을 식별 ○ 특허 분석/ IP컨설팅/ 선행기술조사
– 특허동향
– 기술흐름 현황
– 특허장벽 분석
– 핵심특허 정량분석
– 지식재산권 확보 가능성 ○ BM 설계
– 비즈니스 모델의 실제 실현을 위해서는 기술 또는 서비스의 고도화 선행이 필수적인 요소로 작용함.
수익창출의 극대화를 위해 기술성 및 시장성, 권리성, 기술개발 완성도 등을 종합 고려한 BM을 진단하고 설계함.
○ R&D 기획
– 중소기업 R&D 기획 지원의 효과성을 극대화 시키기 위해 그동안 중소기업 R&D 기획에 대한 경험을 통해 기업이 개발하고자 하는 신청 과제에 대한 지원을 강화하여 기술개발 및 사업화 성공률을 높이고자 함 - 보유 솔루션 : ○ 보유 솔루션
– 대리인 정보 제공 서비스
– 특허분석 (특허맵)
– IP 컨설팅
– R&D 기획
– BM 설계
– 선행기술조사
– 기술가치평가 - 품질 확보 전략 : ○ 품질 목표 달성
– 기능성/ 신뢰성/ 사용성/ 효율성/ 유지보수성/ 이식성 ○ 품질 보증 체계
– 문서관리
– 품질기록
– 합동검토
– 검증과 확인
– 시정조치
– 외/내부품질검사 ○ 품질 보증 활동
– 경영층 진단: 품질활동 현황을 점검하고 개선 및 보완 작업을 지시
– 품질관리 담당: 프로젝트 산출물을 검토하여 사내 표준 및 고객 요구사항에 부합하는지 확인 - 유지보수 전략 : ○ 유지보수 활동 조직
– 품질보증 팀: 품질활동 지원
– 프로젝트 관리자: 요구사항 합동 검토
– 품질보증 담당자: 시스템 구축 담당, 컨설팅 담당, 행정업무 담당 ○ 협업체계 전략
– 정보수집/ 검토회의
– 보고서 작성
– 결함관리, 이슈관리
– 시정조치, 예방조치
– 프로젝트 진행 모니터링
– 사업관리
– 이슈 추적 시스템
– 원격 기술지원 대응 - 카테고리 구분 : 전처리,시각화,정보추출또는조합,분석
- 실적 :
- 기업 개요 및 핵심역량 : ○ 기업개요캐치어스는 IP전문가와 고객이 캐치어스를 통해 만나 서로 공감하며 고객의 힘이 되어주는 지식재산 서포터&플랫폼입니다.정직하고 책임감있게 행동하며 친근하게 다가갑니다.
지식재산 서포터&플랫폼캐치어스는 빅데이터를 기반하여 고객 맞춤 지식재산 전문가 매칭과 지식재산관련 통합정보를 제공해주는 ONE
-STOP 서비스입니다.고객이 출원하고자 하는 분야의 전문성이 있는 변리사를 매칭해주는 전문가 매칭, 변리사 검색 서비스, 선행기술조사 및 특허 분석, 기술 번역, 교육, 행사, 컨설팅 등의 지식재산 통합 서비스를 제공합니다.
○ 주요연혁 2018 설립 2019 창업성공패키지 선정(중소기업진흥공단) 2019 변리사 매칭 서비스 출시 2019 IPracrional IP(영국) MOU 체결 2020 IP정보서비스 벤처기업 육성사업 주관기관 선정 (한국특허정보원) 2020 2020 이노스타트업 육성사업 선정 (대전창조경제혁신센터) 2021~2023 데이터바우처지원사업 공급기관 선정 (한국데이터산업진흥원) 2022 혁신성장 바우처 지원사업, 기술거래 촉진 네트워크 사업 (대전TP) 공급기관 지정 2022 로컬소싱 활성화 사업 (중소기업융합회) 공급기관 지정 ○ 핵심역량 1.
지식재산 통합 플랫폼 운영
– 캐치어스는 고객맞춤 IP전문가 매칭 플랫폼과 특허정보 데이터를 기반한 변리사 통계/ 분석 서비스 운영 2.
기술사업화 전문 지식서비스 제공
– 특허컨설팅: 청구항 다이어트, 연차등록료 납부 대행, 특허침해 주사 및 분쟁 지원, 지식재산 경영전략 수립
– 사업화 컨설팅: 기술확보 전략 수립, 기술사업화 전략 수립, 비즈니스모델 개발
– 기술분석: 선행기술조사, 특허맵 분석
– 기술평가: 기술성/시장성/사업성 평가, 기술가치평가 - 활용 사례 : ○ 활용 사례
– 대리인 활동분야(IPC) 식별
– 대리인의 등록률 추적/조회
– 기술 트렌드, 주요 선도기업, 경쟁사, 중복개발 여부, 기술 장벽 분석
– 아이디어 발굴, 기술 이슈별 해결방안, 기술 트렌드, 핵심 특허 대응
– BM 진단 및 설계/ 운용
– 보유특허 기술성, 권리성, 시장성 분석
주식회사 꿀비 소개
- 주식회사 꿀비은 2015-03-19에 설립되었습니다.
- 주소 : 대전 서구 둔산대로117번길 102 601호
- 주요 서비스 : 가공 업무 소개 ·업무 절차 1.
서비스 상담(프로젝트 문의, 업무 소개, 가격 상담) → 2.
프로젝트 기획(프로젝트 설계, 계획 수립) → 3.
가공 업무배정(빅데이터, 머신러닝 팀 업무 착수) → 4.
프로젝트 관리(업무 모니터링, 중간보고) → 5.
결과 보고(결과물 제출,결과 평가, 사후관리)분류수행 내용데이터 모델링 및 전환·전환 데이터 정의 및 분석, 요구사항 정의·매핑 설계 및 정합성 검증 기준 수립·전환 프로그램 개발 및 이행 검증데이터 수집·웹크롤링·데이터 수집 자동화데이터 전처리·탐색적 데이터 분석(이상치, 결측치)·데이터 특성 스케일링데이터 정제·데이터 오류 패턴 확인·데이터 변환 및 정제데이터 융합·데이터의 활용·분석 목적에 따른 융합·테이블 조인, 쿼리데이터 분석·통계분석·기계학습 분석·피쳐 선정, 피쳐 최적화 및 중요도 도출품질진단·품질지표 정의, 프로파일 및 업무규칙 정의·품질진단 및 이상치 탐지·품질오류 데이터 원인 분석데이터 시각화데이터 조회 및 시각화데이터 관리툴 및 대시보드·AI 가공 및 머신러닝 활용분류수행 내용영상처리분류, 박스 처리, 마커(점)속성, OCR 관련 작업을 수행자연어처리형태소 분류, 라벨링, 단어사전 구축 등 구조화되어 있지 않은 비정형 데이터인 텍스트를 분석하고 기계학습과 같이 활용기계학습 분석기계학습을 사용하여 다양한 분야의 시계열 데이터를 예측통계 분석R, SPS를 이용하여 통계 분석을 수행 - 보유 솔루션 : 1.
데이터 가공 솔루션/SW 소개 가공솔루션 소개
– 데이터 처리 작업 환경 구성을 위한 서버 및 doker 인프라 구성
– 다량의 데이터를 처리할 수 있는 HDFS 아키텍처 패키지 구성
– Raw 데이터를 로드하고 이를 가공 및 분석하는데 활용
– Tensorflow를 쉽게 적용하고 활용할 수 있는 Python 환경 및 script 구성
– 데이터 관리 및 모니터링을 위한 웹 기반 인터페이스 개발
– 데이터 품질 자동확인을 위한 script 구성(기본 20종 지원) 가공솔루션 이용 정보
– 빅데이터(패키징), 머신러닝(웹) 솔루션 직접 개발
– 서비스 제공(데이터 가공 서비스) 기간 동안 별도 라이센스 이용료 없음.
이후 일부 기능(무료) 개방 단, 데이터 분석시 R 또는 SPS 이용료 발생 - 품질 확보 전략 : 데이터 품질관리 역량
– 빅데이터 플랫폼&센터 사업, 학습용 데이터셋 구축 사업, 공공데이터 개방 품질관리 수행
– 데이터바우처, AI가공바우처, AI바우처 관련 데이터 품질관리 수행
– 데이터 개방, 공공, 값, 구조, 표준, 관리체계에 대한 전반적인 품질 진단 및 관리
– 민간 및 공공 대상 데이터 품질관리 관련 컨설팅 수행 데이터 품질관리 체계 품질진단 협업체계 구성 품질관리 수요기관 공공 민간기관 품질관리 공급기관 주식회사 꿀비 품질관리실무협의회 프로세스품질관리 담당 데이터품질관리 담당 정상현 조영훈 조직 구분역할 및 책임품질관리수요기관사업 데이터 품질관리 수요기관구축과 품질 연계 업무에 대한 일정 조율품질 문제 발생시 개선 및 처리에 대한 의사결정 지원품질관리공급기관사업 데이터 품질관리 (수행)공급기관구축 단계에 따른 각 파트 별 일정 관리프로젝트 수행 기간별 품질 산출물 관리품질 관련 회의 주재 및 인력 관리품질관리실무협의회품질 문제 발생에 대한 논의를 위한 전문가 협의회수집된 데이터 내용에 대한 자문정기적 품질 회의 주재내부 품질관리 절차 및 방법에 대한 검증 수행프로세스품질관리 담당정의된 품질 요구사항의 공정 품질에 대한 관리 총괄구축 진행 과정 - 유지보수 전략 : AI 학습모델 개발 전문성을 활용하여 수요기업의 사업화 전략 연계 지원데이터를 활용한 서비스 고도화 연계 지원서비스 활용을 위한 시스템 구축 지원
- 카테고리 구분 : 전처리,품질,코딩,시각화,태깅또는라벨링
- 실적 : 사업명사업기간발주처비고자율주행 자동차 고장진단 데이터 셋 구축2022.06~2022.12한국지능정보사회진흥원 온라인 결혼 중개 고도화를 위한 NLP 기반 회원 스크리닝 서비스 개발2022.06~2022.11㈜여보야 재난안전 데이터 플랫폼 구축2022.05~2022.12행정안전부 지하수 정보 통합관리 시스템(AI융합과제)2022.04~2022.12정보통신산업진흥원 2021 년도 빅데이터 데이터 융합 및 가공 용역2021.09~2021.12한국산림복지진흥원 숲길종합정보 데이터 개방체계 구축2021.08~2022.01한국정보화진흥원 학습용 데이터셋 구축사업2021.07~ 2021.12한국지능정보사회진흥원 2021년 데이터바우처 사업2021.06~ 2021.11주식회사 스튜디오닷에이치주식회사 유니브이알 2021 년 문화재돌봄 통합관리시스템 운영 및 유지관리 용역2021.03~ 2021.12전통건축수리기술진흥재단 NGS
-ARS v2.0 프로젝트2021.01~ 2021.07신테카바이오 AI 바우처 주식회사 이편한자동화기술2020.09 ~ 2020.12주식회사 이편한자동화기술 AI 바우처 주식회사 에이소프트2020.09 ~ 2020.12주식회사 에이소프트 산림복지 빅데이터 데이터 융합 및 가공 용역2020.09 ~ 2020.12한국산림복지진흥원 AI 가공 바우처
– 파츠너2020.09 ~ 2020.12주식회사 파츠너 AI 가공 바우처 브레이스2020.09 ~ 2020.12브레이스 데이터바우처 (가공 )2020.07 ~ 2020.11주식회사 에프에스솔루션 데이터바우처 (가공 ) 깨끗한 지하수 연구소2020.07 ~ 2020.11깨끗한 지하수 연구소 NGS
-ARS v2.0 프로젝트 설계 용역2020.03 ~ 2020.05주식회사 신테카바이오 빅데이터 센터 구축 사업 내 센서 네트워크 데이터 안정성 관리 솔루션2019.12 ~ 2020.01클레어 주식회사 빅데이터 - 기업 개요 및 핵심역량 : 사업 개요 데이터에서 핵심과 가치를 발견하고 목적에 맞게 기술을 적용하는 데이터 중심 사업 수행 ·데이터 경험 : 다양한 도메인에서 데이터 경험을 공유하고 방향을 모색하여 고객들이 기술을 통해 쉽고 빠르게 자신만의 데이터 경험을 극대화시킬 수 있도록 추진 ·데이터 탐색 : 도메인에 따른 필요 ·데이터 분석 : 전문가들의 데이터 기반 해석을 통해 원리와 관계를 구명하고 분석 결과를 도출 ·데이터 활용 : ·가치 창출 : 고객 + 기술 + 플랫폼을 연결하는 시스템을 통해 단순 데이터 제공이 아닌 서비스 가치를 창출하도록 지원 전문 분야 빅데이터 시스템 구축, 머신러닝 솔루션 제공 등데이터 처리 관련 다양한 경험 보유 1.
빅데이터 시스템, 플랫폼 구축 2.
자연어처리, 머신러닝 3.
웹 기반 플랫폼 및 정보 시각화 4.
바이오 및 의료 논문 정보 분석 - 활용 사례 : -2022년 바우처 사업 연계 지원사항 예시이성매칭률 향상을 위한NLP모델 개발 및 활용 연계 지원바우처 과지를 통하여 구축된 데이터를 활용하여 이성 매칭률 향상을 위한 모델 개발 협력 지원추천 시스템 고도화 연계 지원
바이오브레인 소개
- 바이오브레인은 2013-02-25에 설립되었습니다.
- 주소 : 대전 서구 둔산대로117번길 66 골드벤쳐타워 208호
- 주요 서비스 : DT
-TX는 텍스트(문헌) 데이터로서 다양한 원천에 따라서 다양한 정보를 지닌 문자 또는 문자코드 데이터이다.
다양한 분야의 문헌 등에서 문자코드로 정제하여 표현하고 문맥등을 파악하여 연결 또는 네트워크 등 형태로 표현할 수도 있다.
이러한 텍스트 데이터에서 아티팩트를 제거하고 정제하여 전처리된 텍스트 데이터를 제공하고 고객의 필요에 따라서 NLP(자연어처리), NLU(자연어이해)등에 활용될 수 있도록, Textual Processing을 하여 텍스트의 특징을 추출해서 함께 제공하기도 한다.
DT
-BI는 생명(생물)정보학 데이터로서 다양한 원천에 따라서 다양한 정보를 지닌 데이터이다.
유전체 염기서열, 단백질 구조, 펩타이드 서열, 마이크로어레이, 단백질 네트워크, 메타볼라이트, 분자 상호작용 등의 데이터 사례가 있을 수 있다.
이러한 생명정보학 데이터에서 아티팩트를 제거하고 정제하여 전처리된 데이터를 제공하고 고객의 필요에 따라서는 데이터의 생물정보학적 특징을 추출해서 함께 제공하기도 한다.
DT
-VD는 영상데이터로서 2차원 배열의 크기, 색상 채널수, 색상 분해능에 따라서 데이터의 세밀도와 용량이 결정된다.
폰을 통해서 촬영한 사진 데이터와 MRI, CT, 초음파, PET 등의 의료영상 데이터, 열화상 데이터, 인공위성에서 촬용한 지리적 데이터 등의 사례가 있을 수 있다.
이러한 영상 데이터에서 아티팩트를 제거하고 정제하여 전처리된 데이터를 제공하고 고객의 필요에 따라서는 데이터의 공간적 특징을 추출해서 함께 제공하기도 한다.
DT
-TS는 시간에 따라서 변동하는 시계열 신호를 이산디지털로 표본화하여 획득한 데이터를 의미하며, 표본화 주파수, 비트 분해능, 표에 따라서 데이터의 세밀도와 용량이 결정된다.
인체에서 신경생리학적인 신호들이 있으며, 이것을 계측한 사례로 EEG, EMG, ECG, EOG, EGG, PPG, MEG, MCG 데이터 등으로 다양하다.
가속도 3축, 자이로 3축, 지자계 3축 등의 관성 센싱을 한 데이터도 있고 날과 시 - 보유 솔루션 : 주식회사 바이오브레인은 생체계측과 인공지능 솔루션을 제조 공급하고 있음데이터 스토어를 통해서 데이터 전처리, 특징 추출하는 서비스와 AI허브를 통해서 다양한 인텔리전트 알고리즘을 검토하고 적용할 수 있는 모델링 서비스를 제공하고 있음조직구성은 BIOS부와 DeepTech 부로 이루어져 있음BIOS부는 10여년 바이오 시계열 데이터에 대하여 계측하고 분석하는 솔루션을 보유하고 있으면 사업화를 위한 제품 라인업이 되어 있음DeepTech 부는 빅데이터 전처리, 특징추출, AI 모델링 솔루션을 보유하고 사용자 맞춤형의 모델 또는 estimator를 제공하고 있는 조직임제공된 데이터에 대하여 수요자 맞춤형 모델링을 위해서는 수요자가 생성한 데이터에 대한 해당 도메인 지식이 중요함핵심 모델링 인력으로 대표이사를 비롯한 기술 인력이 있으며, 다양한 전공들의 배경이 있으며, 데이터에 대한 해당 도메인 지식에 대하여 관련 배경들이 있음특히 대표이사는 아래와 같이 물리학을 기반으로 바이오와 관련된 다양한 배경이 있음 물리학에서는 역학, 통계역학, 전자기학, 양자역학 등에 대한 배경을 통해서 데이터를 생성하는 시스템의 메카니즘에 대한 깊은 이해가 가능함MRI, CT 등의 의용생체 영상에 대한 경험을 통해서 영상과 관련된 데이터의 전처리와 특징추출 모델링이 가능함EEG, EMG, ECG 등에 대한 경험을 통해서 시계열 데이터의 전처리와 특징추출 모델링 가능함대학원에서의 생물정보학 연구를 통해서 유전체 데이터, EMR 데이터 등의 생명정보 데이터에 대한 전처리와 특징추출, 모델링이 가능함
- 품질 확보 전략 : ㈜바이오브레인은 Bioinformatics, Biosignal Processing, Biomedical Imaging 관련 연구솔루션을 다년간 개발제조하여 제공하여온 기술집약형 연구개발서비스 기업이다.
국내 유수 연구기관 및 연구자가 필요로 하는 다양한 연구 시스템(하드웨어/소프트웨어)을 맞춤형으로 제공하여 관련도메인의 데이터가공 및 생산 과업시에 높은 성과를 산출하도록 On
-Offline의 안정된 기술서비스를 통합 제공해왔으며, 데이터바우처 지원사업의 공급업체로 참여하여 빅데이터, 인공지능, 메타버스 시대에 필요한 학습데이터 수요자들의 니즈에 부응할 수 있도록 하고자 합니다. - 유지보수 전략 : * 출시된 제품은 대부분 생체신호계측 시스템(하드웨어 및 소프트웨어)과 기계학습기반 인공지능 모델링 솔루션이며, 대학, 연구소, 기업연구소 등의 연구기관 등에서 애용되고 있습니다.* 고객 연구기관들의 니즈 (1차적 욕구)에 부응할 수 있도록 기술서비스를 국내 최상 수준으로 유지하고 있습니다.* 고객 연구기관들의 원츠 (2차적 욕구)에 부응할 수 있도록 연구성과의 제품화를 위한 기술적 자문과 협의도 함께 수행하고 있습니다.
- 카테고리 구분 : 분석
- 실적 :
- 기업 개요 및 핵심역량 : ㈜바이오브레인은 생체신호계측 시스템 개발기술, 바이오 의료영상시스템 개발기술, 생물정보 분석시스템 개발기술에 이르기까지, 바이오와 관련된 넓은 범위의 기반기술을 보유하고 있고 최신 트렌드 AICBM (AI, IoT, Cloud, Big data, Mobile)와 기반보유기술과의 융합을 통하여 보다 광대한 비즈니스를 준비하고 생체신호 또는 신경생리신호를 계측하고 이를 응용한 진단기기를 연구 개발하여 제조판매를 하고 있습니다.
- 활용 사례 : ○시정 AI 기반 CCTV 시정계 (www.sijung.com)ㅇ 루시드바이오 AI 기반 신항원 예측 시스템 (www.luseedbio.com)ㅇ ETRI 아동행동패턴 분류를 위한 관성센서기반 Logger Instrumentation과 CNN 인공지능 모델 연구
(주)인공지능팩토리 소개
- (주)인공지능팩토리은 2020-01-15에 설립되었습니다.
- 주소 : 대전 서구 만년로68번길 15-20 5층 504호
- 주요 서비스 : 1.
AIFActory 플랫폼 서비스
-인공지능 기술의 개발이 가속화되면서 연구의 효율성을 위한 인공지능 플랫폼 구축에도 관심이 집중되고있는 상황에 AI Factory의 플랫폼은교육부터 경진대회, 클라우드 서비스 제공 기능까지 갖추고 있음.2.
AIFActory 플랫폼 구성[Competition]
– 자사 자체적인 경진대회 뿐만 아니라 MS 등 기술지원사에서 진행하는 경진대회도 플랫폼 내에 리스트업되어 추천 가능[Training]
– AI factory에서 운영하는 Training 사이트를 통해 유입되는 학습자들이 수업을 이수하며 어느 정도 수준에도달할 시 참여 가능한 대회 및 관련콘텐츠 연동하여 추천 가능
– 이후 다양한 Training 사이트 확보 예정[learning]
-기존에 진행되었던 Keras Learning Day, Daejeon Learning Day 와 같은 현업 종사자들의 강연 및 인공지능관련 교육 자료 제공으로 위 콘텐츠들과 유기적으로 연결 가능 - 보유 솔루션 : 1.
보유 장비시설·장비명규격수량워크스테이션1CPU: 32CoreRAM: 256GBStorage: 2TBGPU: 4×RTX 3090VRAM: 96GB1워크스테이션(클라우드)CPU: 16CoreRAM: 120GBStorage: 2TBGPU: 2×Tesla V100VRAM: 64GB1워크스테이션2CPU: 16CoreRAM: 128GBStorage: 2TBGPU: 2×RTX 3090VRAM: 48GB1평가서버1CPU: 8CoreRAM: 32GBStorage: 2TBGPU: NoneVRAM: None1평가서버2(클라우드)CPU: 16CoreRAM: 42GBStorage: 2TBGPU: NoneVRAM: None1WAS서버1CPU: 8CoreRAM: 32GBStorage: 1TBGPU: NoneVRAM: None1 2.
SW 저작권
-인공지능 경진대회 플랫폼3.업무파트너(협력기업 등)현황 및 역량 NO파트너명주요역량주요 협력사항1경희대학교인공지능(AI: Artificial Intelligence) 교육 및 연구 등을 통한 기술 보유인공지능 모델 개발2크라우드웍스크라우드 소싱 기반의 AI 데이터 가공 플랫폼 기술 보유AI 데이터 가공 기수 - 품질 확보 전략 : ㈜인공지능팩토리는 현재 MS의 기술지원을 받고 있음.
개발기술과 MS의 지원 기술을 develop 시켜 기존 서비스와 차별을 둘 수 있으며, 인공지능 모델을 운영하기 위해 필수적인 데이터셋 변동과 평가척도 변경에 따른 태스크 관리, 모델 모니터링 및 최적화, 모델을 서비스하기 위한 별도의 클라우드 시스템 구축과 같은 자사의 플랫폼과 본 과제의 개발기술은 기존 경진대회 개최기관 및 인공지능 플랫폼과의 차별성이 있습니다.
또한 연계되어있는 교육 콘텐츠 또한 현직에 몸담고 있는 현업 종사자들로 구성되어 있어 경진대회만 진행하는 타 플랫폼과 차별을 둘 수 있습니다. - 유지보수 전략 : 1.
AIFactory 콘텐츠 서비스
– 당사가 별도 페이지를 필요에 따라 지속적으로 생성 및 관리하여, 페이지별로 다양한 콘텐츠가 쌓여왔음.
이를 앞서 언급한대로 많은 이들이 활용할 수 있도록 통합 플랫폼 차원에서의 서비스를 지원함.
– 정리된 콘텐츠는 인공지능에 관심 있는 초심자부터 전문가 레벨까지 다양한 유저를 플랫폼 서비스를 활용할 수 있음.또한, 콘텐츠를 정리하는 기준을 활용하여 향후에도 계속 당사 데이터베이스에 쌓일 콘텐츠에도 적용하여 기준에 대한 별도의 지속적인 유지보수 및 고도화를 원활히 진행하도록 함.
– 정리된 콘텐츠의 메타데이터는 당사의 콘텐츠 큐레이션의 핵심 기술인 추천 알고리즘에 학습 데이터로 활용함.2.
회원 피드백 서비스
– 경진대회를 운영하면서 당사는 경진대회를 맡기고자 하는 B2B 고객을 보유하고 있을 뿐만 아니라, 크라우드 소싱을 활용하여 모델을 개발하고 있으므로 B2C 차원에서도 다수의 이용자를 확보하고 있음.
– 현재 약 2,000명의 회원을 보유하였으며 회원 수는 당사 비즈니스를 확장시킴에 따라 꾸준히 증가 중임.
따라서 본 플랫폼은 B2B뿐만 아니라 B2C를 고려한 플랫폼이며, B2C로 유입되는 유저의 의견과 피드백을 반영하여 플랫폼 서비스가 가능함.
– 당사는 문의 메일과 경진대회별 태스크 Q&A를 통해 대회 혹은 플랫폼과 관련된 문의를 받아왔으며, 이는 B2C 관점에서도 플랫폼을 고도화할 때 필요한 의견으로 내부 및 고객의 의견과 더불어 내용을 개선점으로 반영할 수 있음.
– 특히, 콘텐츠 큐레이션을 위한 추천 알고리즘과 더불어 개인 페이지를 강화함으로써, 결국은 B2B로 유입된 고객도 충분히 B2C로 전환되어 당사의 플랫폼을 활용할 가능성이 높음.
이를 위해 개인이 쉽게 페이지를 개설하여 콘텐츠를 쌓을 수 있도록 커스텀 형식의 템플릿 기능의 서비스를 지원함. - 카테고리 구분 : 전처리,품질,코딩,정보추출또는조합,태깅또는라벨링,분석
- 실적 : NO사업명사업기간계약금액(천원)발주처12020년 데이터바우처 지원사업(2차)
-수요기업:동서울대학교
-20.09
-20.1270,000한국데이터산업진흥원22020년 데이터바우처 지원사업(2차)
-수요기업:이지다이아텍
-20.09
-20.1285,250한국데이터산업진흥원32020년 인공지능 그랜드 챌린지 본선대회 데이터셋 제작 및 온라인 평가환경 구축20.09
-20.12222,900정보통신기획평가원42020년 인공지능 기술혁신 개방형 경진대회 운영 용역20.05
-20.12178,020/593,400정보통신산업진흥원52020년도 AI 문제해결 공모전 운영 용역20.06
-20.12190,476/732,600정보통신산업진흥원62021년 AI바우처 지원사업
-수요기업:휴먼플래닛
-21.04
-21.10375,000정보통신산업진흥원72022년 데이터바우처 지원사업
-수요기업:경일대학교
-22.06
-22.11.3045,000한국데이터산업진흥원 - 기업 개요 및 핵심역량 : 기업개요
– 인공지능 및 데이터 기술 전문가 집단으로 구성되어 있으며 인공지능뿐만 아니라 데이터 구조 및 성능 컨설팅, 교육 및 운영기술지원,인공지능 모델 개발 및 데이터 가공 플랫폼 통합 설계 및 구축 등의 영역까지 연계된 토털 인공지능/빅데이터 서비스 제공핵심역량
– ㈜인공지능팩토리는 AI 알고리즘 기술을 기반으로 컨설팅부터 플랫폼 구축, 크라우드 소싱 기반 AI 모델 개발, 인공지능 모델 유지 관리 등 토탈 인공지능 플랫폼 서비스를 제공하는 기업임.
-코로나 19 팬데믹으로 인한 비대면 서비스 수요 증가와 인공지능 활용 등의 수요 증가로 세계 전반에 인공지능의 영향력이 확대되고 있는 가운데에 자사는 자체 AI 플랫폼과 허브를 보유하고 있음.
– 데이터 다운로드, 모델 학습에 필요한 개발 환경, 알고리즘 검증,리더보드 운영 등 온라인 경진대회 운영에 필요한 기능뿐만 아니라 교육 콘텐츠 및 유관 콘텐츠도 함께 다루고 있음. - 활용 사례 : 1.AI Factory의 플랫폼 내 교육부터 경진대회, 클라우드 서비스 제공 운영https://kdata.or.kr/datavoucher/is/selectPortalSearch.do
주식회사 진원시스템 소개
- 주식회사 진원시스템은 2009-11-10에 설립되었습니다.
- 주소 : 대전 서구 청사로 228 503호
- 주요 서비스 : o 가공업무 상세 소개
– 데이터 가공 프로세스
– 데이터 가공 프로세스별 세부 활동구분서비스 내용상담수요기업의 데이터 가공 대상 정의업무협약체결업무협의상세 업무 협의 수행수요기업의 요구사항정의 및 분석가공 데이터 요건 정의서비스 상세 설계 수행데이터 가공수요기업 요구에 따른 데이터 가공 수행데이터 전처리, 데이터 품질 진단 등 요구 업무에 따른 데이터 가공 수행데이터 검수가공 데이터에 대한 검수데이터 제공검수 완료된 데이터의 수요기업 인도사후관리수요기업의 서비스 개발에 대한 기술지원
– 데이터 가공 업무의 상세 내용업무구분규모, 형태가공업무데이터 가공 변환 (개방형표준문서(ODF) 변환자동화 작업(ODF변환 Tool)데이터 식별,정체, 추출, 변환 등 전처리데이터 품질 확인데이터 DB화, 시각화 작업수작업(코딩 작업)데이터 분석 및 가공데이터 표준화모델링, 그래프 다양한 시각화처리데이터 라벨링수작업데이터를 AI학습하기 위한 라벨링작업데이터학습 기반AI을 활용한 데이터 분석자동화 작업(텐서플로우 AI학습시스템)데이터 학습텐서플로우를 활용한 데이터분석 2.
판매 데이터(또는 가공서비스)의 상세정보 1.
데이터 가공 솔루션/SW 소개 o ODF변환 솔루션 오픈소스를 활용해서 ODF변환을 위한 솔루션으로 다양한 포맷(html, doc, hwp 등)을 가진 문서를 일괄변환 방법으로 변환을 시커주며, 사용이 편리하도록 UI을 구성하였습니다.
– 주요 기능 HTML5 기반으로 다양한 브라우저 동작 가능(chrome, IE11이상) 한글과의 높은 호환성 보장 주요 기능, 단축키를 가장 유사하게 제공 복사/ 붙이기 시 문서 호환성 유지 한글 컨트롤 API와 유사, 최소한의 작업으로 교체 가능 지원 포맷: HTML, DOC, HWP, HWPX, PDF, - 보유 솔루션 : 1.
보유한 데이터 가공 솔루션의 특징 소개
– ODF변환 솔루션 오픈소스를 활용해서 ODF변환을 위한 솔루션으로 다양한 포맷(html, doc, hwp 등)을 가진 문서를 일괄변환 방법으로 변환을 시커주며, 사용이 편리하도록 UI을 구성하였습니다.
– 변환 솔루션 특징솔루션의 특징내용인공지능 알고리즘 정형화 및 내·외부 연계 인터페이스 Tensorflow를 활용한 API간 연계 개발도출된 핵심 기능(인공지능 알고리즘)을 활용한 사용자 UI 로그인, 메뉴, 권한, 도움말 기능 등 개발분석대상 자료를 고려한 데이터베이스 구축 및 정규화 방법 개발분석 대상을 일시적으로 저장할 테이블 구축 및 파일 시스템 개발 주요 화면 [메인화면][데이터시각화] [데이터 처리] - 품질 확보 전략 : o 데이터 품질의 의미 데이터 품질은 비즈니스 성과를 결정한다.
데이터가 잘못 되어 있으면 올바른 의사결정을 내릴 수 없다.
디지털화가 진행될수록 데이터의 중요성은 커지고 있다.
데이터에 기반한 의사결정이 확대될 뿐만 아니라 데이터가 자원으로서 새로운 비즈니스를 창출하기 때문이다.
따라서 많은 기업과 기관이 데이터 품질을 목표 수준으로 확보하기 위한 투자를 늘려가고 있다.
한 가지 중요한 관점은 데이터 품질의 개념이 바뀌고 있다는 점이다.
과거의 데이터는 주로 거래의 결과로 생성되었다.
빅데이터 시대를 거쳐서 데이터 경제 시대의 데이터는 다양한 형태로 발생하고 있고, 데이터 활용 방식도 바뀌고 있다.
o 데이터 품질 전략
– 빅데이터 품질관리는 기존 데이터 품질 요소인 정확성, 완전성, 적시성, 일관성 측면에서 다른 방식의 품질 전략이 필요
– 정확성, 완전성, 적시성, 일관성에 대한 품질 전략은 데이터의 사용목적, 데이터의 재사용 여부, 일관성 유지 여부에 따라 수립 <; 빅데이터 품질 요소와 품질 전략 >데이터 품질 요소데이터 품질 전략정확성(Accuracy)데이터 사용 목적에 따라 데이터 정확성의 기준을 다르게 적용 ex) 사용자가 접속한 사이트와 이동 지점을 분석하는 클릭스트림 분석과 부정이나 사기를 탐지하는 경우 데이터의 품질 수준은 다름완전성(completeness)필요한 데이터의 완전한 확보 보다는 필요한 데이터를 식별하는 수준으로 적용 가능적시성(Timeliness)소멸성이 강한 데이터에 대해 어느 정도의 품질 기준을 적용할 것인지 결정 ex) 웹 로그 데이터, 트윗 데이터, 위치 데이터 등은 하루, 몇 시간, 몇 분 동안만 타당성을 가짐일관성(Consistency)동일한 데이터라 할지라도 사용 목적에 따라 달라지는 데이터 수집 기준 때문에 데이터 의미가 달라질 수 있음※ Data Quality for Big Data : Principles Remain, But Tactics Change, 가트너, 2011의 내용을 - 유지보수 전략 : o 데이터바우처 사업에 가공기업으로 참여 시 외부 수요 증가에 따른 대응계획
– 스마트공장에 주력함으로, 공장에 대한 컨설팅 고급인력을 확보하고 빅데이터 교육 수료생을 대상으로 데이터 가공 및 분석 업무에 대한 부족 인력을 보완한다.
– 현재 동국대에서 진행 중인 혁신성장 청년인재 집중양성 사업과, 데이터산업진흥원 빅데이터 청년인재 일자리 연계 사업에서 양성된 빅데이터 분야의 청년인재 수료생을 대상으로 고용을 유도 하여 외부 수요 증가에 따른 데이터 가공 업무를 청년 인재 채용을 통하여 보완 o 유지보수, 고객관리 및 고객응대 부문 대응 계획
– 상품 증가에 따른 가공 서비스는 전문성이 요구되므로 사업 분야 별 전문가를 충원하여 유지보수 및 대응체계를 마련하고, 필요 시 전문 책임자 별로 팀을 만들어 빅데이터 교육 수료생을 팀원으로 충원하여, 고객 대응 계획을 수립 o 협업 체계 및 데이터 가공 상담, 컨설팅 제공 계획
– 센서를 탑재한 웨어러블 디바이스, IoE 디바이스 등과 센싱 정보를 수집하여 Low
-level 상황인지 및 자율재구성을 수행하는 스마트 폰 등의 스마트 디바이스
– 사용자 의도, 주변 상황을 포함한 지식베이스 모델링 및 KSB 인공지능 플랫폼과의 연계를 통한 기계학습 기반의 High
-level 상황인지 응용 서비스 플랫폼
– 병원, 119, 보호자 등에게 긴급 상황정보 제공 및 대처/대응/지원을 위한 Assistant 서비스 단말로 구성
– 주변사물 및 IoE 센서의 가상화 : 주변의 IoE 센서 및 사물을 추상화 및 센싱 범위를 확장하여 내 손안의 센서처럼 활용
– 실시간 동작 인식 : 3축 가속도 센서를 이용하여 동작별 SVM(Signal Vector Magnitude)의 극댓값 (Local Maximum Value) 추출로 실시간 동작/행위 인식 가능(신뢰도 : 93.4~99.2%) - 카테고리 구분 : 전처리,품질,코딩,시각화,분석
- 실적 : 사업명사업 기간발주처대전광역시 일자리데이터 DB화 및 AI분석2020.05~2020.08대전경제통산진흥원AI와 Mobile기술을 활용한 빅데이터 분석 솔루션 개발2019.03~2019.11아이오티봇환경빅데이터 플랫폼 구축2021.04~2021.12현성
- 기업 개요 및 핵심역량 : o 기업 개요 : 구분내용회사명주식회사 진원시스템 (영문: Jinwon System Co,.
Ltd)대표이사류제필소재지대전 서구 청사로 228, 503호(둔산동)연락처TEL) 042
-719
-1110.
FAX)0505
-476
-1110회사 설립일2009년 11월 10일 사업분야소프트웨어 개발시스템 통합 구축(SI)데이터 가공 - 활용 사례 : o 사업 개요 : 기업의 주요 사업 개요 및 전문분야 소개
– 빅데이터산업은 크게 데이터의 생성, 가공, 활용 세분야를 이루고 있습니다.
진원시스템은 데이터의 가공 및 활용분야에 초점을 맞추어 사업영역을 진행하고 있습니다.
데이터의 생성은 데이터가 생성할 수 있는 기반을 갖춘, 공공기관, 통신사, 언론사 등의 각자 분야별로 고유영역을 확보하고 있으며, 이를 바탕으로 가공 및 활용 기업이 존재하여 시장을 이루고 있습니다
– 이에 따라 진원시스템은 가공, 활용분야 중 데이터 가공 변환(개방형표준문서) 변환, 데이터 DB화작업 및 시각화작업, 데이터 라벨링, AI을 활용한 데이터 분석의 사업을 영유하고 있습니다.
주식회사 글래스돔코리아 소개
- 주식회사 글래스돔코리아은 2020-11-03에 설립되었습니다.
- 주소 : 대전 서구 한밭대로 755 (삼성생명) 22층
- 주요 서비스 : 데이터 수집: 모든 설비/계측기/센서 데이터를, 단순 Plug & Play 중앙수집이 가능한 무선 HW 기술데이터 연동: REST API, Developer API 등 기존 MES/SCM Oracle, MySQL, MSSQL 시계열 연계데이터 통합관리 솔루션: No
-Code 기반의 Drag & Drop 손쉬운 기능 구성데이타분석 & AI : 품질기준 최적화및 제어, 제조환경 예측, 설비이상감지 - 보유 솔루션 : (분석) 최적화 솔루션제조현장 공정, 품질 데이터의 상관관계를 탐색적분석을 통한 품질 기준 최적화(조건) 및 제어 솔루션(분석) 예측 솔루션공정내 중요한 환경정보(온습도, 차압)등의 수치해석 및 모델링을 통한 제조 환경 예측 솔루션(행동 및 기타) 감지 솔루션연속적 데이터의 정렬 및 지속적 강화학습을 통한 설비 이상 감지 솔루션
- 품질 확보 전략 : 시스템 구축 계획글래스돔에서 보유하고 있는 정형 데이터 수집 및 전처리 솔루션, 데이터 품질 관리 시스템, 생산조건 최적화 서비스 시스템을 바탕으로 공정 특성을 반영한 기능과 작업 연결을 추가 개발.글래스돔의 AI 엔진을 기반으로 최적의 AI 모델을 개발하여 구축한 서비스 시스템 탑재현장 적용 및 공정 특성을 반영한 서비스 시스템 커스터마이징 개발 적용테스트 계획가) 개발 단위 테스트 실시나) 통합 테스트 및 시범운영 실시다) 현장 적용과 모델 검증, 피드백을 통해 AI 성능을 강화검증 방법: 학습된 모델의 정확도를 준비한 테스트 셋을 이용하여 검증함.
취득된 데이터의 일정비율을 테스트 셋으로 이용하는 hold
-out 검증 방법과 취득된 데이터를 K개의 셋으로 나눈 후 그중한개의 세트를 테스트 셋으로 나머지 K
-1세트를 학습 세트로 사용하여 K번의 테스트를 수행한 후평균을 구하는 K
-fold cross validation 검증 방법을 사용할 수 있음.교육 및 이관계획시스템 사용자 및 관리자를 대상으로 적기에 가장 효율적인 방법으로 사용법을 숙지시켜 효율적인시스템 활용과 운영을 위한 것으로, 사용자 운영매뉴얼을 기본으로 실시(사용자 운영매뉴얼을 기본으로 하여 업무별 사용자 교육훈련 16시간 실시)교육범위는 시스템 전반에 관한 것으로 사용자 관점의 교육은 업무 기능별 입력 및 조회 방법 등각 업무기능별로 사용자를 대상으로 실시하고, 시스템 운영 관리자는 서버운영, DB관리, 시스템 관리등 시스템 관리를 위한 기초교육을 교육대상 범위로 하여 시스템의 기능 및 특이사항을 사용자측면에서 교육한다. - 유지보수 전략 : 글래스돔의 유지보수는 무상 유지보수와 유상 유지보수로 구분되어 시행되며, 시스템을 구성하는 요소에 대한 유지보수는 문제 발생 원인에 대한 지원 또는 재해결 방식으로 수행 및 유지보수를 위한 조직적, 기술적, 환경적 특성을 충분히 이해하고 이를 바탕으로 유지보수 조직을 통합 One
-call 서비스 체계로 구축1.
유지보수 구분구 분정 의무상유지보수무상은 하자보수로 정의하며, 단순 오류수정을 범위로 함시스템 메뉴의 기능 업그레이드시스템 설계내역과 개발 시스템이 상이하거나 하자가 있는 것은 무상 하자보수를 원칙으로 함무상기간은 최종 검수완료 시점부터 12개월로 하며, 무상 하자보수 기간 중 사용자의 고의, 과실 및 천재지변에 의한 사항에 대해서는 책임을 지지 않음무상 하자보수 기간 중 발생된 변경요구에 대한 사항은 이를 검토하고 무상 하자 보수 범위 포함여부를 판단하여 상호 별도 협의유상유지보수유상 유지보수 대상은 무상 하자보수 범위를 넘어서는 것과 무상 하자보수 기간 만료 후의 유지보수 활동으로 함세부 내용은 샇오 협의하여 결정(별도 계약)2.
무상 유지보수 세부사항구분내용무상보수대상공급한 목적물에 하자가 있는 경우 무상 유지보수 실시 함프로젝트 종료 후 3개월 이내에 발생하는 기능 상의 하자에 대한 무상 유지보수내용에러수정, 기능 자체의 문제점으로 인한 수정/보완, 목적물의 수정운영시스템 최적화 및 안정화 지원, 정상운영을 위한 기술지원유지보수대상프로젝트 범위 내 공급한 목적물 대상으로 유상 유지보수 실시 함시스템지원시스템 패치 및 업데이트 [수정/보완]운영시스템 최적화 및 안정화 지원AI 모델 튜닝 및 커스터마이징기술 지원(온/오프라인) 일상지원 및 기술문의 대응(온/오프라인) 정상운영을 위한 기술지원 (장애처리 및 장애내역 점검)(온/오프라인) 정기 예방점검 및 정기 성능 - 카테고리 구분 : 전처리,품질,코딩,시각화,정보추출또는조합,태깅또는라벨링,분석,기타
- 실적 : No업종과제내용1제약공정대웅제약 GMP공정 AI를 통한 온습도최적화를 통한 냉난방 제어, 에너지 사용량최소화 프로젝트2제지공정아시아 제지 생산속도 예지모델을 통한생산성 향상 프로젝트3식음료 공정오리온제과 AI를 통한 품질보증, 제조계획데이터 기반의 의사결정 시스템 구축
- 기업 개요 및 핵심역량 : 기업개요 : 글래스돔은 산업회사의 디지털 전환을 위한 소프트웨어 수직 통한 솔루션을 제공합니다.
제조 현장 PLC 및 센서등의 설비 데이터로부터, ERP 및 MES와 같은 상위레벨 IT 시스템을 하나의 유기적인 시스템을 통해 관림함으로써, 산업별 특화된 솔루션 제공핵심역량 : 기존환경에 제약 조건 없이, 설비 가동 중단 없이 Cloud 데이터 수집 가능데이터 수집을 위한 공사 및 서버 등 하드웨이 도입 및 관리 불필요다양한 데이터 수집 및 분석, 가공 경험 유 - 활용 사례 : [최적화 솔루션]사례1.
식품공정 적용사례표준화된 품질 범위를 선정하고, 영향을 주는 인자를 나열원료 공급과 제조 공정의 데이터별 상관관계를 탐색적으로 분석하여, 맛, 색감 등 저품질의 제조에 영향을 미치는 요인 최적화사례2.
화장품공정 적용사례CGMP 기반 아날로그로 관리하던 문서 및 데이터들을 Cloud 디지털화하여 관리하고 분석 가능한 시스템 구축원료, 제조 및 품질검사 업무를 로직화한 표준 프로세스를 정립하고, 실시간 데이터 기준으로 AI 최적화 실현[예측 솔루션]사례1.
화장품공정 적용사례공기 조화기, 열교환기, 가습기 및 송풍기 데이터 수집 및 빅데이터 분석AI 기반, 차압/온도 예측으로 공기 중 미립자에 따른 청정공기 순환량 조절 및 필터 교체시기 알람 등 신속조치로 이탈방지사례2.
제약공정 적용사례공기조화기 열/유체역학 기반 수치해석 모델링 및 Cloud 디지털트윈 구축AI 기반, 온도/습도 예측으로 GMP 이슈 신속조치 및 이탈방지설비 운용 데이터 기반 모델예측 제어를 통해 동적 상태 추정 가능 모델 개발오프라인 및 온라인 강화학습을 통한 에너지 수송 계통 손실요인 및 데이터 분석으로 에너지 절감 최적화 달성[감지 솔루션]사례1.
제지공정 적용사례실시간 설비 데이터 및 운영 데이터 시계열 분석으로 데이터 기반 다운타임 원인 분석 및 주요 인자 도출AI 기반 생산속도 예측 모델 구축 및 고도화로 특정 운영 조건에서 생산속도 절감에 대한 사전조치사례2.
석유화학공정 적용사례기존 DCS로는 파악이 불가능했던 공정의 상태 혹은 변화파악 가능파악한 데이터들을 바탕으로 알람시스템을 만들어 공정 Trouble 대응배관에서의 미세한 가스 누출 및 노후화 설비의 전기누전을 실시간으로 탐지 가능한 카메라 설치Cloud 기반 데이터 수집 및 AI 분석으로 관제시스템 이상징후 감지

데이터바우처 사업관리 가공기업 정보
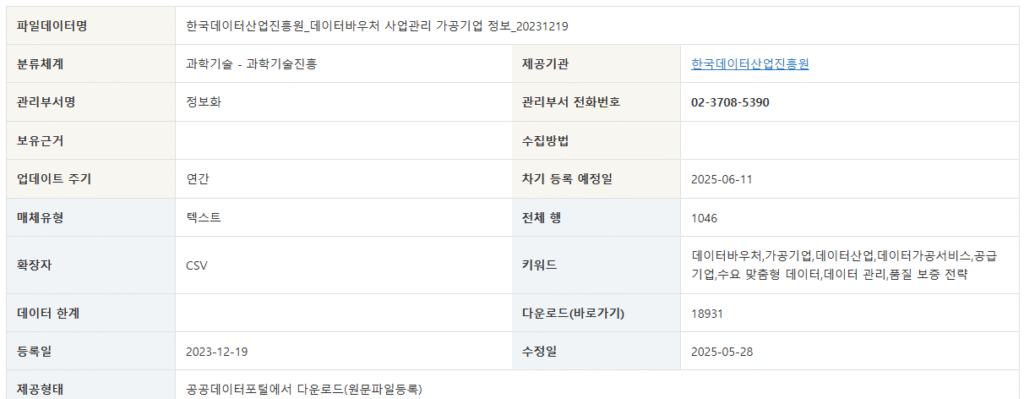
한국데이터산업진흥원 데이터바우처 사업을 통해 지정된 공급기업 중 데이터 가공기업 정보를 제공하고 있습니다. 본 데이터는 데이터바우처 지원사업에 참여하는 기업들의 정보를 포괄적으로 다룹니다. 특히, 수요기업이 필요로 하는 다양한 형태의 데이터 가공 서비스에 대한 정보를 제공함으로써, 데이터 활용의 범위를 넓히고, 기업의 데이터 기반 의사결정을 지원하는 역할을 합니다. 이 데이터가 보유한 컬럼은 다음과 같습니다.
기업한글명(문자형) : 해당 기업의 한글 이름
설립일자(날짜형) : 기업이 설립된 날짜
기본주소(문자형) : 기업의 본사 주소
상세주소(문자형) : 기업의 주소에 대한 추가 정보
주요서비스 상세정보(문자형) : 데이터 가공기업이 제공하는 구체적인 서비스 내용
보유솔루션(문자형) : 기업이 보유한 해결책 및 시스템에 관한 상세 정보
품질확보전략(문자형) : 데이터 품질 확보를 위한 기업의 전략
유지보수전략(문자형) : 데이터 가공 서비스 후속 지원 계획
카테고리구분(문자형) : 제공하는 데이터 가공 서비스의 카테고리 분류
등록일(날짜형) : 데이터가 등록된 날짜
실적(문자형) : 기업의 성과와 실적
기업개요 및 핵심역량(문자형) : 기업의 전반적인 설명과 주요 전문성
활용사례(문자형) : 데이터 및 서비스를 활용한 실제 사례
링크(URL) : 데이터에 대한 추가 정보 및 접근 링크
파일 다운받기
주요서비스 상세정보(요약), 보유솔루션(요약), 품질확보전략(요약), 유지보수(후속지원), 전략(요약), 실적(요약) 등의 일부 데이터 값은 데이터 미집계로 인해 공란이 있습니다.