
서울 강남구 데이터바우처 사업관리 가공기업
서울 강남구 에는 (주)마크로밀엠브레인, (주) 와이드코어, 티벨 외 125개의 가공기업이 있습니다.
(주)엔키스 소개
- (주)엔키스은 2021-04-12에 설립되었습니다.
- 주소 : 서울 강남구 영동대로 312 (엘앤티렉서스(주)LEXUS전시장) 7층 엔키스
- 주요 서비스 : ■분석 및 기획ㅇ 수요기업의 요구사항 맞춤형 컨설팅 및 기획 서비스
-국내IT대기업에서 인공지능과 빅데이터 분석을 기반으로Master Planning및ISP기획을 담당한 전문가들이 사전 컨설팅을 진행
-수요기업의 시스템 및 데이터 현황분석,인공지능 모델링을 데이터 가공서비스 방향성 도출, Digital Transformation전략수립 등 목표 설정
-국내 대기업,중소중견기업에서 인공지능,빅데이터 분석 경험4년 이상의 전문가들이 수요기관 맞춤형 데이터 가공 서비스를 제공■데이터 전처리ㅇ 데이터 수집 기관 및 데이터 정제 기관과의 긴밀환 업무 협조 체계 구축 및 경험 활용
-㈜엔키스는 스마트 팩토리와 자율주행 영역에서 직접 데이터 수집을 수행해온 경험을 확보하였음
-고객 요구에 따른 데이터 수집 및 정제의 역할 수행뿐만 아니라 데이터 가공 분야에 전문성을 보유ㅇ 표준 데이터 모델 설계 및 가공 서비스
-데이터를 효과적으로 활용하기 위해서는 수집된 데이터를 통한AI모델에 대한 전문지식은 필수적임
-특히 자율주행 기술 및 선진국가에서 선도하는 기술의 경우,글로벌 데이터 표준에 대한 지식이 중요
-정제된 데이터로부터 인공지능 모델에 활용할 수 있는 데이터로의 가공 업무에 많은 지식 보유
-외부 데이터 가공업체의 데이터를 표준 데이터로 변환하는 기술 보유 및 다수의Open API보유■데이터 분석ㅇ 데이터 특성 분석 및 인공지능 모델 선정 서비스 제공
-가공된 데이터세트로부터 데이터 분포 및 군집의 특성 분석 서비스 제공(차원 축소 및 요인 추출)
-지도학습,비지도학습,준지도학습, Teachable Machine등 다양한AI모델 추천 서비스 제공
-자율주행에서 다루는 다양한AI응용 서비스의 기술 축적 및 활용 경험 보유(특히KITTI표준)ㅇ 가공된 데이터세트의 인공지능 적용에 적합성에 관한 유효성 검증 서비스 제공
-적용 가능한 인공지능 모델의 선정 및 벤치마킹 서비스 제공
-수요기관과 합의하여 수립한 품질 지표에 따라 인공지능 모델별 도출 가능한 품질 수준 측정
– Confusion matrix - 보유 솔루션 : ㅇ 데이터를 수집하고 보관하고 정제하고 제공할 수 있는 데이터 기반 플랫폼ㅇ 인공지능 모델을 쉽게 설치하고 운영(모델 실행)할 수 있는 인공지능 서비스 운영 플랫폼ㅇIoT기기와 같은 저사양H/W스펙에서 운영할 수 있는 인공지능 서비스 운영 플랫폼ㅇ 기업내 존재하는 다양한 데이터 수집 및 연계서비스를 제공하는 플랫폼
- 품질 확보 전략 : ■품질 확보 전략ㅇ품질 전담 인력 구성
-데이터 가공 서비스 전문 조직 구성 및 품질 관리 역할 병행
-인공지능 유효성 검증을 위해 기업부설연구소의 데이터 과학자와AI개발팀과 기술지원체계 구축
-데이터 분석 및 가공 서비스 운영 및 전문적인 기술지원을 위한 기술 역량 훈련 프로그램 운영(전담 인력들의 전문성,서비스 품질향상에 관한 정기 교육 시행)
-수요기관에㈜엔키스의 품질확보 프로세스 공유 및 서비스 공급 체계 정립을 통한 서비스 제공
-수요기업의 요구사항을 수렴할 수 있는 온라인RFC운영 및 데이터 배포 서비스UX편의성 개선
-외부 전문가 네트워크를 활용한 데이터 검증 및 활용 방안에 대한 지식 공유 및 확보
-국내TTA및 공인 인증기관과의 교류 및AI데이터 품질인증의 공인 기관으로의 역할 추진ㅇ㈜엔키스의 품질확보 프로세스 - 유지보수 전략 : ㅇ 클라우드 플랫폼 기반SaaS형 서비스와DevOps운영으로24시간 원격으로 유지보수 서비스를 제공함ㅇ 사업 완료 후 수요기업에 유지보수를 위한 유지보수 책임자를 지정하여,하자보수 및 장애 발생에대하여 신속하게 대응할 것이며 당사 유지보수 지원체계에 따라 신속하게 진행함구분내용유지보수 대상ㅇ 공급한 목적물을 구성요소를 대상으로 한다.무상하자보수 기간ㅇ 사업 완료 후6개월간 지원한다.유지보수내용하자보수ㅇ 검수 완료 후6개월 이내에 발생하는 데이터 결함에 대한 유지보수ㅇ 기본 점검,장애 발생 시 원격 지원품질개선ㅇ장애 발생 시 수요기업이 재공급을 요구할 경우,상호 협의로(유/무상)제공하여 업무 차질을 최소화함유지보수범위예방점검ㅇ 무상 유지보수 계약기간 동안 예방정비 주기를 설정,반복적 운영관리ㅇ 예방정비 활동 중 정기 점검 실행무상하자보수ㅇ 공급한 목적물에 하자가 있는 경우는 무상하자보수를 원칙으로 함무상유지보수ㅇ 무상 유지보수 기간 중 발생하는 유지보수 활동유상유지보수ㅇ 고객의 실수 또는 천재지변에 의한 장애에 대해서는 책임을 지지 아니함ㅇ무상하자보수 기간 중 신규기능을 추가하고 기존의 시스템을 개선하는경우상호 협의 하여 실비 제공함을 원칙으로 함ㅇ 유지보수 인력 이외의 인력이 수행한 시스템 개조,첨가,조정 및 수리 등으로 시스템에 중대한 영향을 끼쳤을 때는 유상 처리함
- 카테고리 구분 : 전처리,품질,코딩,시각화,태깅또는라벨링,분석
- 실적 : 번호프로젝트내용기간1AI학습용 데이터 유효성 검증2D및3D Annotation학습 데이터 세트에 대한 인공지능 인식 성능 유효성 검증21.06.01~21.12.312자율주행 데이터 구축용 인공지능 서비스 개발(라벨링)LiDAR도로주행 데이터 기반Cuboid라벨링,데이터세트 검색에 관한 서비스21.08.18~21.12.313Smart Factory강화학습 프로젝트 수행SmartFactory강화학습21.06.01~21.19.174광주 자동차 부품산업 고도화를 위한 지능형 자동차 스마트 팩토리 통합 솔루션 개발데이터 레이크 및 인공지능 운영플랫폼 개발21.06.01~22.02.285지능형 원격자산관리 시스템(RAMS)구축원격지 자산관리를 위한Data Lake Platform적용21.06.01~21.12.31
- 기업 개요 및 핵심역량 : ㈜엔키스는 스마트팩토리,자율주행,스마트시티 등에서 발생하는 빅데이터를 분석한 딥러닝을 기반으로,Anomaly Detection, Predictive Maintenance등이 가능한AI모델링과AI모델 운영 및 관리를 위한 클라우드 서비스 플랫폼을 개발,운영하고 있습니다.이를 기반으로 스마트 바이오,스마트 발전,스마트시티,스마트 자산/자원/에너지 관리 등4차 산업 분야전반에 걸쳐 트렌드를 선도하고 관련 분야 선두 기업으로 성장할 수 있도록 비즈니스를 확대하고 있습니다.㈜엔키스는“인재 제일(人材第一)”과“구동존리(求同存異)”의 덕목으로 서로 유기적인 협력 체계를 통해 인간의 삶에 도움이 되는 인공지능 기술과 서비스를 고객 및 파트너사에 제공하고자 하며, 4차 산업혁명의시대를대비하여 디지털 변혁(Digital Transformation)을 하려는 기업들의 촉매자(Facilitator)역할을 통하여표준화된 플랫폼과 인공지능 영역을 확장해 나갈 것입니다.ㅁ 데이터 공급 역량ㅇ㈜엔키스는 지능정보산업협회 임원사 및 성균관대 스마트팩토리융합학과UNIC협약체결 등 산ㆍ학ㆍ연 등 다양한 기관과 연구개발,인공지능 컨설팅 및 자문역할로서의 네트워크를 구축함ㅇ 현재 스마트팩토리,자율주행 분야의 데이터Annotation솔루션을 보유하고 있으며,라벨링 자동화, Dataset생성 및 검수,메타데이터 동기화 검수 및Data Lake Platform운영 경험을 가진 전문가13명을 보유ㅇ㈜엔키스는 다수의수요기관의 데이터기반Digital Transformation혁신을 수행하였으며 다수의AI·빅데이터 분석을 통한 품질 예측 및 데이터 관리체계 수립경험을 보유함ㅇ 사용자가 데이터의 크기,유형(정형/반정형/비정형),속도가 다양한 빅데이터를 더욱 쉽게 통합하고,원하는 형태로 데이터를 변환하고 시각화 분석이 가능하도록 서비스를 제공하고 있음ㅇ특히 배치,스트림 데이터의 처리를 빠르고 유연하게 수행하여 데이터를 통합,데이터 사일로(Silo)가 제거되어 저장공간의 효율화,데이터 관리 및 거버넌스 작업 간소화가
- 활용 사례 : ㅇ 자율주행차량AI학습용 데이터 구축사업
– AI학습용Data Lake Platform을 적용한 라벨링 데이터세트 유효성 검증
– AI학습데이터Annotation솔루션 적용
(주)창업인 소개
- (주)창업인은 2020-03-27에 설립되었습니다.
- 주소 : 서울 강남구 영동대로75길 9 (수암빌딩) 3층
- 주요 서비스 : □ 디지털 상권화 가공서비스[데이터 가공 프로세스 및 상품예시]·창업인 자체 수집 및 협업 확보데이터, 수요기업의 데이터를 원본으로 창업인의 자체 보유 시스템을 통해 데이터를 추출 전처리를 통해 표준화하여 저장, 분석 가공 시행· 창업인 2.0 솔루션에 의해 커스터 마이징을 한 후 수요기업에게 필요한 출점전략 및 성과관리를 할 수 있는 시각화 분석 리포트를 제공하고자 함
□서비스 제공 목표 및 계획[데이터 바우처 사업을 통한 서비스 제공 계획]
– RAW데이터를 바탕으로 데이터 분석 및 창업인 시스템 엔진에 대한 커스터마이징을 통한 데이터분석 결과 및 인사이트 제공,창업인 플러스 시스템 사용 제공
-후속 지원 목표:사업 선정 후 완료 시점 기준1년 이내
-데이터 바우처 사업 가공지원 사업에 준하는 상품 서비스를 월단위/회수(필요시)로 나누어 할인된가격(30%이상)에 동일 수준의 서비스를 지속 제공
□수요 증가에 따른 가공 서비스 제공 방안[데이터바우처 사업을 통해 다수 수요기업의 데이터 및 요구사항 확보,요구사항 형태별 표준안 구축]
-프랜차이즈 본사가 내부적으로 출점전략 및 성과관리를 할 수 있는 시각화 분석 리포트 표준화
-창업인 플러스 플랫폼 서비스의 형태가SaaS(Software as a Service)이기 수요 증가에 따른 서비스 적용및 확장에 유리함
– 내부 전담조직 구성 및 운영전담 인력 구성을 통해 최소 인력,최소 비용으로 수요 증가에 대응 - 보유 솔루션 : □ 창업인 플랫폼 현재 구현현황
– 창업인 서비스 플랫폼은 창업전 직접 운영하는 가맹본사를 통하여 누적데이터를 확보하는데 약 1년이라는 시간을 준비했으며, 정량적인 검증 및 사업성 판단을 거쳐 2020년 4월 정식 법입을 설립함 * 2020년 4월: 창업 커뮤니티 서비스를 우선적으로 서비스 오픈 * 2020년 5월: 가맹본사와 예비창업자 매칭을 지원하는 새롭게 고도화 * 2020년 6월: 지도 기반의 상권데이터 베타 서비스를 오픈(상권분석 데이터 수집)
– 서비스 베타 테스트를 통해 2020년 7월 정식 서비스를 런칭함
– 코로나사태 이후 예비창업자와 가맹본사간의 매칭 성사률이 5% 미만으로 떨어지면서, 현재는 F&B시장에 첫 비대면 채팅 견적 서비스를오픈하는 등 다양한 부가 서비스를 제공하여 ,BM 확장과 서비스 고도화를 진행중에 있음
– 현재 통신사, 카드사 등과 상권분석 데이터 협의를 통해 빅데이터 기반 모델링 작업 고도화 중 [향후 개발 방안]
-전문 AI가공 업체와 협업하여 올 12월을 1차 목표로 예비창업자에게 적합한 입지 및 프랜차이즈 브랜드 추천을 위한 AI 알고리즘 개발 중
– 향후 창업인 서비스는 부동산, 상가, 프랜차이즈 대출 등 다양한 서비스 확장을 준비하고 있음
– 특히 본 데이터 바우처 사업을 통해 창업인 온라인 상권관련 테이터를 판매할 예정이며, 이를 바탕으로2022년 중 앱/웹 기반 B2B 기업들이 온라인 데이터를 분석하고 트렌드를 모니터일 및 활용할 수 있는서비스를 런칭할 계획임(가칭 B2B 전용 디지털화 관리 시스템) - 품질 확보 전략 : □ 판매 데이터의 품질확보 전략[데이터 수집, 생산 단계]
1) 개인정보 활용 동의 기반 데이터 수집
2) 비식별 조치 가이드라인 준수
– 판매하는 모든 데이터 상품은 행정안전부가 제시한 ‘개인정보 비식별 조치 가이드라인“을 준수하고 있음 3) 활용 데이터
– 데이터 상품 생성 시 활용하는 데이터는 자체 및 서비스 협업을 통한 가입자정보, 신호정보, 이용정보, 의견정보화 공공 데이터 및 구매 데이터를 활용
– 공공 데이터는 건출물대장, 새주소 DB, 통계청 사업체 DB등을 활용
– 외부 데이터는 카드 소비데이터, 상권유형 데이터 등을 활용
– 이 외에 상품을 생성하기 위한 텍스트 정제 솔루션 등을 필요 시 활용 4) 외부 협력사 협업 5) 데이터 상품 업데이트
– 데이터의 품질은 지속적인 모니터링을 통해 이상치, 결측치 등 발생시 원인파악 후 조치
– 시스템 및 분석 솔루션에 대한 업데이트 작업 이후 데이터 결함여부 지속 확인 - 유지보수 전략 : □ 수요기업 유지보수계획
1) 무상 유지 보수서비스
– 사업 완료 판매 데이터 및 제공내용, 사전협의 사항 오류에 대한 무상 서비스 제공
– 납품된 데이터 이상 발생시 고객과 충분한 협의를 통해 문제 확인 후 A/S 처리
– 필요시 데이터 인프라, 원천 데이터 품질 및 로직단에서의 오류 검증시행
– 고객과 데이터 보정에 대한 완료 접수 후 종료 처리
2) 유상 유지 보수
– 수요기업 별로 별도 계약을 통해 유상으로 사후 유지 보수 제공
– 창업인 플랫폼 서비스 이용 회원사들을 대상으로 데이터 바우처 사업을 통한 유지보수 대상자들은 할인율 적용하여유상 유지보수 진행 - 카테고리 구분 : 전처리,코딩,시각화,정보추출또는조합,태깅또는라벨링,분석,기타
- 실적 : □ 최근 3년 실적관련 성과 · 창업인 플랫폼은 현재 약 500여개의 프랜차이즈 고객사를 두고 있으며, 2021년 10월 서비스를 정식 런칭함 · 데이터 기반 컨설팅, 판매, 마케팅 등의 수익 등 유사 사업 매출을 꾸준히 창출힘 (데이터 관련 사업 실적: 20년 총 19건, 5천 3백만원 / 21년, 약 20건 9천 만원 / 22년 총 8건, 1억 8천 6백만원)
- 기업 개요 및 핵심역량 : 1.
기업소개[빅 데이터기반F&B본사
-가맹 예비창업자 매칭 플랫폼] · 예비창업자들이 적합한 프랜차이즈 기업의 정보를 확인할 수 있게 정보제공 ·빅데이터 기반 데이터 분석을 통해 창업에 필요한 정보제공을 실시하고 프랜차이즈 본사와 예비창업자 서로에게 최적의 파트너를 찾아주는 서비스 · 프랜차이즈 정보공개서 분석, 가맹점 모집정보, 브랜드 소개 인터뷰 등 정보제공 · 통신사 기반 유동인구 특성을 보여주는 상권분석 앱 서비스 제공(빅데이터 기반) · B2B 본사에게 데이터 분석을 통해 경영현황 파악 및 개선을 도와주는 마케팅 인사이트 제공 (AI기술기반 소셜 모니터링 마케팅 트렌트분석 자료 제공) · 창업관련 질의응답 및 창업정보를 교류할 수 있는 앱 기반 창업커뮤니티 서비스 제공 2.
핵심 기능[빅데이터 분석을 통한 실제 필요한 상권분석 데이터 제공] · 예비창업자들이 창업하고자 하는 상권을 중심으로 배후지의 유동인구, 카드소비 데이터 기반 매출 정보, 소비자 이동동선, 개폐업 정보 등필요한 실제 정보 제공 [검증된 프랜차이즈 브랜드 핵심정보 제공] · 창업에 필요한 매장수, 창업비용, 단위면적당 매출액 등을 쉽게 비교 가능하게 제공 ·통계청, 홈택스, 공정거래위반 사례 데이터 등을 분석하여 검증된 브랜드 정보 소개 [자체 보유중인 기술을 기반으로 과학적 알고리즘에 의한 적합한 브랜드 추천] · 프랜차이즈 정보공개서 분석, 가맹점 모집정보, 브랜드 소개 인터뷰 등에 기반한 자체 데이터 보유 및 브랜드 검증기술 보유 · 통신사 기반 유동인구 데이터 등 빅데이터에 기반한 적합 상권 및 브랜드 추천 - 활용 사례 : □ 해당 데이터상품 예상 수요[예시 상품1:온라인 상권 소비자특성 분석 데이터]
1) 제조업/유통업
– B2C판매 제조업체,유통업체 대상으로 판매상품(애견샴푸)의 검색광고 타겟 및 상품기획 시 주소비자 층 분석,판매사이트 선정하여데이터 활용
2)교육/보험 서비스업
-교육컨텐츠의 지역별 관심고객군을 알고싶어 하는 업체를 대상으로 신규 콘텐츠 반응,경쟁사의관심도를 비교시 데이터 활용 3) 소상공인
-신규 상품 출시시 소비자들의 관심사 확인 및 비교를 통한A/B테스 [예시상품 2: 온라인 키워드 모니터링 트렌드 분석 데이터]
1) 커머스/유통업
– 커머스, 유통업 대상으로 자사 사이트 및 경쟁사 사이트의 주요 타겟 고객 군 비교 분석을 통해맞춤형 마케팅 전략 방향 수립
– 자사 사이트의 월별 주요 타겟 군의 변화 추이를 통해 브랜딩 전략 및 신규 상품 출시 등에 활용
2)교육/보험 서비스업
– 교육 컨텐츠 사이트 주 이용 고객군의 주/야간 상주지 분석을 통해 교육 컨텐츠 맞춤형 마케팅 및주 고객군 거주지 근방 지역의 오프라인 마케팅과 연계 시 활용
(주)아울네스트 소개
- (주)아울네스트은 2012-09-14에 설립되었습니다.
- 주소 : 서울 강남구 자곡로 174-10 강남에이스타워 318호
- 주요 서비스 : 1) 자율주행 시뮬레이션 데이터 가공서비스 보유데이터 현황
– 센서, 인프라, SW(인지, 판단 등), 모니터링으로부터 발생하는 데이터와 활용 사례의 조사 분석
– 자율주행 AI 학습을 위한 고품질 raw 데이터 수집 방안으로써 자율주행 학습용 raw 데이터 수집은 단순 영상 데이터뿐만 아니라 GPS, 차량 CAN 데이터도 동기를 맞춰서 수집해야 함
– 수집 영상 센서의 캘리브레이션(intrisic, extrinsic) 파라미터 값을 함께 제공: 차량 기준 영상 픽셀의 상대좌표 확인 및 실제 자율주행에 학습 결과 추론시 타 센서 퓨전을 위해서 필요
– 영상데이터는 대용량 데이터이므로 고속 무손실 영상 압축 기술을 적용하여야 단시간에 보다 많은 데이터를 수집할 수 있음(수집 용량 및 복사 시간 등 절약)
– GPS 데이터는 수집 데이터 지역 확인, 중복 데이터 제거, Mapping용도로 활용
– CAN 데이터는 음영 지역에서 위치 추정용으로 활용하기 위하여 필요, 또한 향후 확장 적용을 위하여 자율주행 End
-to
-End learning을 위해서도 필요하며, 주행 중 긴급한 돌발 행동(엑셀, 브레이크, 조향)에 대한 상황 확인용으로 활용
– 영상 데이터에 포함되어 있는 사람 얼굴, 자동차 번호판은 비식별화 처리 필수(반자동화 도구 활용) 학습데이터 생성
– 센터 시스템 내부의 데이터 가공(Bound Labeling 등) SW를 통해 학습 데이터 생성
– 생성 학습데이터 유효성 검증 방안① 1단계: 수동검증 및 기계 학습° 생성된 학습데이터를 샘플링하여(ex) 1만장) 육안 검사 진행° 샘플링 데이터는 다양한 환경/시간/지역 별로 고르게 분포될수 있도록 추출° 저품질 데이터는 수정 보안° 고품질 데이터를 이용하여 기존 인식기에 학습 수행하여 신규 인식기 생성② 2단계: 자동검증° 신규 인식기에 원본영 상데이터를 입력으로 인식 결과와 학습데이터 자동 비교 분석(IOU: Intersection of Union)(자동화 도구)° 정의된 threshold 기준 값 이하인 데이터는 저 - 보유 솔루션 : 보유 솔루션솔루션명용도설명crawlmob수집배치/실시간 수집 및 수집 대상의 유연한 확장이 가능한 지능형 데이터 수집 솔루션nlpmonster전처리정형 비정형(자연어 포함) 데이터 대상 전처리 솔루션bismarckturm분석50여 종 이상 고전 분석 기법 및 머신러닝 기법 등을 GUI 기반으로 최적화 및 적용 가능한 데이터 분석 솔루션dbcluster데이터베이스하둡 기반의 대용량 데이터 저장 및 대량 관계형 데이터베이스 서비스를 동시에 제공하는 솔루션aicluster머신러닝테슬라 및 RTX 계열의 서버용 GPU 기반의 인공지능(머신러닝) 모델 도출 및 적용 솔루션 텍스트 데이터 기반 AI 프레임 워크 적용 기술
– 텍스트 데이터를 대상으로 AI 프레임워크를 적용하고 이를 활용하여 텍스트 분석추론 및 생성 기능 제공° 텍스트 데이터 대상 AI 프레임워크 구축 및 적용° 텍스트 학습데이터 파라미터 튜닝° 텍스트 기반 분석추론° 학습데이터 기반 텍스트 생성적용 비정형 데이터 처리(NLP
-Mainframe) 기술
– 텍스트 데이터 전처리를 위한 자연어 처리 통합 솔루션의 토크나이징 엔진을 이용해 데이터 분석의 속도와 정확성 제고° 자동 띄어쓰기 및 오탈자 교정° 형태소 분석/구문분석° 개체명 인식° 기계학습/감성분석 인터페이스 리스크 모니터링
– 비정형·대용량 데이터 처리기술을 이용한 감성분석 결과를 기반으로 내외부데이터 대상 리스크 발현의 선행여부 판별° 데이터정제 자연어처리 및 분류° 감성분석 결과 기반 리스크 추출° 감성메시지 군집별 게시채널, 작성자 분류° 감성메시지 전파 경로 분석 토픽 레이블러
– 토픽 레이블이 부착된 의미 클러스터 단위로 주제 분석 및 문서 할당, 주요 키워드 및 연관어 추출° 토픽별 주요 키워드 자동 추출° 토픽 키워드별 통계적 연관키워드 자동 추출° 토픽 클러스터링° 토픽 레이블링 텍소노미 자동분류 시스템
– 도메인 관련 분야 텍스트를 선별 적재 및 분석하기 위해 텍소노미 자동분류 시스템 제공° 텍소노미 클래스 별 Eviden - 품질 확보 전략 : 품질 확보를 위한 전략 : 중점 추진 전략
– 4대 추진전략을 기반으로 데이터바우처 지원사업 공급기업 산출물 품질확보 방안과 기존의 공통프레임워크 품질 점검 시스템 활용 방안에 대한 종합 실행계획을 제시
– 전략1: 제안사의 데이터 품질점검 관련 노하우를 활용하고 구축 경험을 반영하여 현실성 있는 세부 추진 방안 수립
– 전략2: 다채널 소통체계 마련으로 일반 행정 및 기술 문의 대응을 통해 원활한 품질점검 수행
– 전략3: 관련 컨설팅 겯력 인력 투입 및 제안사 인원 품질점검 교육으로 효율적인 인력 운용 계획 수립
– 전략4: 제안사가 기보유하고 있는 공통 프레임워크의 품질점검 시스템을 활용하여 신속하고 정확한 품질점검 시행 품질 확보를 위한 전략 1 : 품질확보 관련 경험 활용
– 제안사의 품질확보 관련 경험을 적극적으로 활용하여 최적의 공급기업 산출물 품질확보 환경 구축 전략 및 세부 계획 수립① 旣구축한 빅데이터 플랫폼의 산출물 및 품질관리 경험을 적극 활용
– 한국정보화진흥원 빅데이터 플랫폼 및 센터 표준화/품질관리, 신한금융지주 빅데이터 플랫폼 구축 및 데이터 표준화/품질관리 등의 경험을 적극 활용
– 기술감시, 통합DB구축, 데이터 표준화 및 품질관리 등의 시스템 구축 및 컨설팅 경험② 경험을 통해 도출된 데이터바우처 품질점검 이슈 보완
– 표준화된 산출물 리스트 부재
– 품질 및 수량에 대한 기준이 없어 작업 비효율성 증가
– 문의 응대 인력의 부족으로 문의 진행 어려움
– 감리업체에 의존성이 높은 점검은 데이터 품질수준 보증이 어려움③ 제안사의 품질점검 프레임워크 활용 및 적용
– 제안사가 보유한 품질점검 프레임워크를 데이터바우처 지원사업 공급기업 품질점검 사업에 적절하게 커스터마이징 품질 확보를 위한 전략 2 : 품질점검 소통체계 구축
– 과거 관련 컨설팅 수행 시 관련기관과 지속적인 소통의 중요성을 파악하여 본 사업의 성공적 수행을 위한 기반으로 다채널 소통채널 개설, 공급기업 및 발주기관과의 지속적인 소통체계 구축 품질 확보를 위한 전략 3 : 전문 인력 - 유지보수 전략 : 유지보수 및 관리
– 시스템 자원의 효율적인 관린와 지속적 성능 향상을 통해 시스템의 안정적 운영 도모를 통한 시스템 장애 발생 시 신속 대처를 위한 안정적인 유지보수 및 관리 체계 구축
– 안정적인 유지보수 체계 구축° 무상 유지보수 보증기간 동안 운영 지원을 위한 지원조직 구성° 장애 발생 시 지원을 위한 비상 연락체계 구축° 구축과정에서의 하자로 인한 시스템의 수정 등 지원
– 신속하고 정확한 문제 해결° 하자보수 기간 내 신속한 지원 체계 구성° SW 공급업체와 지속적인 지원 체계 유지° 제안사 전사조직 활용
– 최적의 유지관리 환경 유지° 안정적 시스템 운영 및 효율적 관리를 위한 유지관리° 조직체계의 최적화° 필요시 비정기 점검
– 유지보수 계획 수립사업관리소프트웨어 관리
– 프로젝트 하자보수 관리
– 문제점/개선사항 확인
– 하자보수 인력구성 및 일정관리
– 시스템 운영 안정화 인력 구성
– 응용프로그램 하자보수
– 신규 개발된 응용 소프트웨어 운영 모니터링
– 소프트웨어 버전 관리
– 성능 관리시스템 관리운영 관리
– 하드웨어의 통합적인 구성 및 설정 지원
– 필요시 납품업체 지원 요청
– 시스템 소스트웨어에 대한 최적화
– 기타 시스템 정상 운영을 위한 지원
– 시스템 운영지원, 장애점검
– 장애이력관리
– 시스템 운영 안정화 활동 - 카테고리 구분 : 전처리,품질,코딩,시각화,정보추출또는조합,태깅또는라벨링,분석,기타
- 실적 : 데이터바우처 사업 수행 이력사업참여 구분사업명사업 목표수요/공급기업AI가공공급기업(202
2)입법과정에서의 국민참여 제고를 위한 AI저널리즘 모델 구축국회 회의록, 의안 정보, 국민참여입법센터 등 국회 및 입법 관련 데이터 및 뉴스, 커뮤니티,SNS를 수집·분석해 시의적절한 기사 아이템을 발굴·선정한 후, 기사 아이템 관련 데이터 해석을 통해 기사 자동 생성㈜공감신문반려동물 CCTV 플랫폼 서비스용 기초 데이터 학습CCTV를 통해 구축될 영상 기반의 데이터 활용을 위해 웹크롤링을 통한 다양한 반려동물 이미지를 취득하여 플랫폼 서비스용 기초 데이터를 학습하여 서비스 개발 추진㈜메타몬자율주행 차량 이상상태 분석판단 시스템 (데이터 : 차량 검지 데이터, 시뮬레이터 산출)자율주행 시뮬레이터 제작 기술 확보 및 고도화, 비정형 주행환경 대응 자율주행 시뮬레이터를 통해 이상상태상황 인지 적용 알고리즘 기능 요구사항 분석 및 설계에이아이티스토리실버세대 생활건강 위험 진단을 위한 AI기반 말뭉치 데이터 분석 모델 구축실버세대 생활 말뭉치 데이터에서 문장 분리 후 형태소 분석 및 복합명사/유의어/불용어 처리 후 학습해 이를 기반으로 말뭉치 내 키워드를 바탕으로 위험군 자동 추출주식회사 D35AI기반 임대차 관련 데이터 분류 및 조정 솔루션 개발을 위한 데이터부동산 관련 계약서 분석을 위한 OCR데이터 수집 및 인공지능 적용을 위한 가공서비스를 통해 계약서상 기재된 다수의 항목/텍스트 자동 인식주식회사 아이엔가공기업(2019)약품정보 전처리 인덱스 가공 사업이원화된 약품데이터 대상 전처리 가공을 통해 시스템간 약품정보를 유기적으로 연계약품데이터 인덱스 가공을 통해 데이터AI 기반의 차세대 헬스케어 산업 대상 지원비트컴퓨터건강보험 행위분류 데이터 가공 사업건강보험 행위분류 원천 데이터 분류코드별 추출, 분류코드별 한글명 가공, 한글 정규화 명칭(인덱스) 가공, 한글 이형태 명칭(인텍스) 가공 등에프에스수요기업(2019)주식시장 테마주 알리미주식투자관련 뉴스 사건정보 데이터베 - 기업 개요 및 핵심역량 : 1) 기업조직도㈜아울네스트는 이사회를 필두로 영업네트워크, 기술사업팀, 경영지원팀, 분석사업팀 4개 조직으로 구성
– (영업네트워크) 에프엔가이드 및 삼성SDS와 금융데이터, IBM과 삼성SDS와 제조데이터 부문에서 협력네트워크를 구성, 방송통신부문 에서는 미디어미래연구소, 소프트웨어 공급 부문에서는 엑스큐어넷과 네트워크를 유지, 그 외 공공사업 및 IT 인프라사업 등과 관련 다양한 영업네트워크 구성
– (기술사업팀) Technical Management Unit (TMU), Software Development Unit (SDU), Core Technology Unit (CTU), Research and Development Unit (RDU) 등의 하부조직으로 기술사업팀 구성
– (경영지원팀) 영업기획관리, 경영지원, 인사관리, 기술지원 및 마케팅/홍보, 대외업무 등을 관장
– (분석사업팀) 수집된 데이터 분석을 위한 Statistical Analytics Unit (SAU) 및 데이터 기반의 비즈니스 지원을 위한 Business Service Unit (BSU) 두 개 조직으로 구성
2) 사업분야 및 제품/서비스㈜아울네스트의 사업분야는 비즈니스 부문과 산업 부문으로 구성
– (비즈니스) Core Technology Unit (CTU), Integrated Business Unit(ITU), 비즈니스 컨설팅 (GBS), IT 통합서비스, 연구도 (R&D) 5개 부문으로 구성
– (산업) 자율주행자동차, 금융데이터, 제조데이터, 방송통신, 소프트웨어, 공공산업 부문 산업 영역 전개㈜아울네스트의 제품·서비스는 5가지 대표영역으로 정의 가능
– (빅데이터 분석) 빅데이터 분석을 활용, 소비자 행동 패턴 분석을 통한 고객 맞춤형 제품 및 서비스 제공
– (소프트웨어) 데이터 분석 핵심 모듈 기반, 플랫폼 구성에 용이한 통합 엔터프라이드급 컴퓨팅 기술 및 서비스 제공
– (조직 내 데이터 분석) 데이터 비즈니스를 활용, 조직 내 협업 및 커뮤니티의 정량화를 통한 마케팅 - 활용 사례 : ㈜아울네스트의 데이터 관련 사업 수행 이력 활용 영역
– (스팸데이터) 스팸 대응을 위해 기 구축된 시스템과 연계하여 효율적으로 스팸을 분석차단할 수 있도록 시스템 구축하는 동시에 다양한 분야의 활용을 위하여 스팸 데이터를 유관기관에 제공할 수 있는 AI 학습 데이터 및 공유 시스템 환경 구축
– (불법금융광고데이터) 인터넷상 수집된 금융광고 중 불법행위가 의심되는 게시글을 분석하여 불법성 여부 판별을 지원하는 AI시스템을 구축
– (민원데이터) OCR*(광학문자인식) 및 문서텍스트변환 솔루션을 도입하여 민원신청·처리 관련 첨부파일**을 텍스트로 변환하고 DB를 구축
– (다종데이터) 다분야 선행 사업 수행 이력을 토대로 수집된 다분야 데이터를 활용, 데이터 바우처 사업 간 원활한 역할 수행
– (자율주행 데이터) 2020년 한국교통안전공단 도심도로 자율협력주행을 위한 동적정보 빅데이터 분석 기획 및 플랫폼 기획 및 세종테크노파크 자율주행 데이터 수집 관련 기술 및 데이터 요구사항 분석수립 사업 수행 이력 활용, 자율주행 관련 생산 데이터 및 노하우 데이터 바우처 사업 내 활용 가능
– (상품리뷰 데이터) 2019년 에뛰드하우스 Voice Mining Program 구축 기획 및 시행 데이터바우처 사업 수행 이력 활용, 상품리뷰 데이터 및 데이터 수집 체계에 국한된 것이 아닌 타분야 수집 대상 데이터의 특정을 통한 데이터 수집 체계 수집 체계 마련 가능
– (재난원인정보 데이터) 2017년 국립재난안전연구원 글로벌 재난안전 리스크 정보 탐색 및 모니터링 기술 개발, 2018년 국립재난안전연구원 재난안전 정보탐색 알고리즘 및 탐색영역 확대 기술개발, 2019년 국립내난안전연구원 기계확습 기술활용 재난안전 문서 자동분류 기술 개발 및 학습자료 구축, 2021년 국립재난안전연구원 재난원인 정보 자동추출 및 특성분석 기술 개발 사업 수행 이력 활용, 다년간 동일 기관 발주 사업 수주 시 추출된 데이터 활용 재난원인정보 데이터 및 관련 사건정보 데이터, 재난안전 현황 데이터
주식회사 히츠 소개
- 주식회사 히츠은 2020-05-18에 설립되었습니다.
- 주소 : 서울 강남구 테헤란로 124 902호
- 주요 서비스 : 서비스 개요본 서비스는 인공지능 및 시뮬레이션 기술을 이용하여 신약개발에 도움이 되는 데이터를 생산 및 가공하여 수요업체에 제공하는 서비스입니다.
수요업체에서 관심있는 질병의 타겟이 되는 단백질과 후보물질 리스트를 제공하면, 제공받은 분자의 타겟에 대한 결합구조, 결합에너지, 독성, 보고된 물질과 구조 유사성, 및 시각화 데이터를 인공지능과 시뮬레이션으로 계산하여 데이터를 수요업체에 전달합니다.
수요업체에서는 전달받은 데이터를 신약후보물질 개발에 사용할 수 있습니다.예를 들어
1) 후보물질의 약물가능성 우선순위를 정할 수 있고
2) 전달받은 1차 데이터를 가공하여 유용한 정보를 추출해낼 수 있으며 3) 약물의 작용기전을 파악할 수 있습니다.
이 외에도 수요기업의 타겟에 맞는 다양한 분석이 가능합니다.
기존 서비스와 다르게 정량적인 결과와 더불어 시각적으로 직관적인 결과 데이터를 제공하여 비전문가들도 쉽게 결과 데이터를 이해할 수 있습니다. - 보유 솔루션 : 서비스의 주요기술1.
docking을 이용한 약물
-단백질 결합구조 계산 및 시각화신약개발에서는 약물과 단백질의 결합구조를 아는 것이 중요합니다.약물
-단백질 결합구조를 통해서 약물의 작용 메커니즘 및 약물 구조 개선 방향 등을 알 수 있습니다.
docking계산을 통해서 약물 단백질 결합 후보구조를 생성할 수 있습니다.2차원의 약물구조를docking계산의input으로 넣어 약물
-단백질의3차원 결합구조를 생성합니다.이 서비스에서는 병렬 계산을 통해서 빠르고 정확하게 수 백 만개 분자들의docking계산을 수행할 수 있음.특히 실험에 비해 많은 분자의 결합구조를 빠르게 계산할 수 있기 때문에 초기 신약단계에 있어 큰 도움이 되는 기술입니다.2.
약물
-단백질 상호작용 예측 인공지능 기술인공지능을 이용하여 도킹으로 예측한 약물
-단백질 결합구조의 결합에너지를 예측합니다.결합에너지는 약물의 예측 효능과 직접적으로 관련되어있습니다.결합에너지가 크다는 것은 약물과 단백질이 강하게 결합하고 있다는 걸 의미하며,따라서 약물로서 효능을 나타낼 가능성이 높습니다.때문에 결합에너지 예측값은 약물 후보물질을 선택하는데 유용한 정보로 사용될 수 있습니다.또한 인공지능을 이용해서 약물
-단백질 상호작용 종류를 분석화 하고 시각화 할 수 있습니다.3.
시뮬레이션 기반 약물
-단백질 결합 매커니즘 분석 및 시각화약물은 단백질과 상호작용 하면서 시간에 따라 움직입니다.이러한 움직임은 매우 빠른 속도로 일어나기 때문에 실험으로 측정하기 힘듭니다.대신 시뮬레이션을 통해 이러한 움직임을 예측하여 약물의 작용 매커니즘을 분석할 수 있습니다.예를 들어 약물이 단백질에 결합하여 단백질에 어떠한 구조적 변화를 유도하는지 분석할 수 있습니다.또한 시간에 따른 약물의 움직임을 고려하기 때문에 예측 결과 역시 그렇지 않은 방법들에 비해서 정확합니다.클라우드를 이용해서 시뮬레이션에 필수적으로 동반되는 대규모 자원을 충당하기 때문에 빠르게 결과 데이터를 제공할 수 있습니다. - 품질 확보 전략 : 신약후보물질을 발굴하는 서비스는 고객사가 원하는 후보물질의 기준이 수치로 표시되며, 이 기준에 도달해야만 성공으로 인정 가공서비스 품질에 대한 판단 또한 고객이 요구한 기준에 부합하는 결과물을 산출하였는가에 따라 결정.
기계적으로 성공여부 판단이 가능하여 끊임없이 성공률을 높이기 위한 연구개발 역량강화 또한, AI신약개발이라는 서비스 특성상 계약기간 중 사업팀 연구담당자와 고객사 간에 지속적인 피드백과 소통이 필수적 이러한 면에서 HITS는 창사이래 다수의 제약사 및 바이오테크들과 협업하며 독보적인 성과를 쌓아왔음 서비스의 품질, 즉, 성공적인 결과물을 지속적으로 도출하기 위해 가장 중요한 것은 우수인재의 확보와 내부 연구역량의 강화 이를 위해 2023년 CADD 박사 및 의약화학자를 포함하여연구인력을 추가채용할 계획 - 유지보수 전략 : 서비스 제공계획 서비스 진행과정
– 수요기업과의 미팅: 서비스에 대한 상세설명
– 수요기업과 서비스 계약 체결
– 수요기업에서 기초 정보 전달
– 서비스 수행
– 서비스 결과물 수요기업 측에 전달
– 수요기업에서 결과물 확인 및 피드백
– 서비스 종료 가공과정
– 수요기업으로부터 단백질 구조, 결합위치 및 분자 2D 구조 전달 받음
– 전달 받은 분자들의 3차원 구조 생성
– 3차원 구조를 활용하여 분자들 전처리 과정 수행
– docking 계산을 수행하여 약물
-단백질 결합 구조 생성
– 계산된 약물
-단백질 사이 상호작용 분석
– 인공지능을 이용한 약물
-단백질 결합에너지 계산
– 초정밀 시뮬레이션 계산 수행 ㅇ 데이터가공서비스 제공 목표
– HITS의 고객은 신약개발을 연구하는 제약사, 바이오테크, 병원, 연구소, 대학 등 모든 참여주체
– 2023년 한해 동안 50건 이상의 서비스 제공을 목표로 함 ㅇ 수요 증가시 대응방안
– 현재 HITS는 자체개발한 AI플랫폼을 이용하여 연구원의 생산성을 극대화하고 있음
– 또한, HITS는 22년 연말에 개발을 완료한 신약개발 웹플랫폼인 ONE플랫폼을 보유
– HITS 플랫폼이 완전자동화에 가까워질수록 1명의 연구원이 처리할 수 있는 프로젝트의 수는 늘어나게 되며,고객사와 보다 활발한 커뮤니케이션이 가능 - 카테고리 구분 : 전처리,품질,코딩,시각화,정보추출또는조합,태깅또는라벨링,분석
- 실적 : 2020년 05월 회사 설립 2020년 09월 종근당, 일동제약, 보령제약, HK이노엔 플랫폼서비스 협약 2020년 10월 LG화학 공동신약개발 협약 2020년 10월 중소벤처기업부 TIPS 과제 선정 2020년 11월 테라젠바이오 공동신약개발 협약 2021년 02월 University of South Florida 공동신약개발 협약 2021년 03월 티씨노바이오 플랫폼서비스 협약 2021년 04월 사이러스테라퓨틱스 플랫폼서비스 협약 2021년 05월 SK바이오팜 플랫폼서비스 협약 2021년 07월 노바셀테크놀로지 공동신약개발 협약 2021년 08월 베노바이오 공동신약개발 협약 2021년 08월 보령제약 플랫폼서비스 협약 2021년 08월 한국파스퇴르연구소(IPK) 공동신약개발 협약 2021년 10월 대웅제약 플랫폼서비스 협약 2021년 10월 베노바이오 플랫폼서비스 협약 2021년 11월 베노바이오 공동신약개발 협약 2021년 11월 K
-스타트업 2021 특허청장상 수상 - 기업 개요 및 핵심역량 : (주)히츠는 인공지능, 클라우드 등 첨단 디지털 기술을 활용해 기존의 비효율적인 신약개발 패러다임을 혁신하고자 함.
이를 위해 AI 기반 약물
-단백질상호작용 예측, 약물 구조 설계, 분자 시뮬레이션 기술 등을자체 개발하였으며, 상기 기술을 활용한 사업 모델로는 SaaS 형태의AI 신약개발 플랫폼(ONE플랫폼), AI 기술 서비스, 공동 신약개발이 있음.
현재 국내외 제약사, 연구 기관 등과 협업을 지속하며 다수의 성과를거두고 있음.
HITS의 핵심경쟁력
– 차별화된 기술력과 우수한 연구진 1.
물리
-딥러닝 융합 hit discovery 기술(논문투고 완료)
– 단시간 내 광범위한 탐색이 가능한 인공지능과 정교한 검증이 가능한 물리화학법칙, 그리고 생물학적 상태를 반영한 정확한 생명과학의 3요소를 결합하여 hit 발굴 성공률을 향상시키고 신약개발에 소요되는 시간 및 비용을 절감
– 물리
-딥러닝 융합으로 약물
-단백질 간 상호작용을 예측하는 독자 모델 개발
– 물리법칙 도입을 통한 딥러닝 방법의 약점인 과적합 문제를 해결하였으며, 물리적으로 해석이 가능한 예측을 통해 의약화학자와 합동연구가 용이한 장점
– 국내 유수제약사 및 바이오테크와의 협업을 통해 검증이 완료 2.
합성 및 특허가능성이 높은 Hit to Lead 기술(특허등록완료)
– 분자골격기반 화합물디자인과 원자단위를 넘어선 작용기 단위의 분자디자인 기술, 여기에 합성가능성 높은 정교한 가상라이브러리 디자인을 결합하여 Lead 발굴 성공률 향상
– 국내 대기업과의 협업을 통해 Lead 발굴 성공한 바 있으며, 국내 제약사가 제공한 scaffold를 바탕으로 분자를 설계하여 특허성있는 신규 신약후보물질 발굴 3.
물리
-딥러닝 융합 열역학적 성질 예측(특허등록 완료)
– 물리화학적 의미를 반영한 특징을 추출하고 물리기반 분자
-환경 상호작용을 분석, 대량의 학습데이터를 이용한 Multi
-task learning으로 Lead발굴 성공률 향상 - 활용 사례 : 서비스 활용 예시 및 성과현재까지 2년 반 동안 이 서비스를 15개 회사에 제공하였습니다.
이를 통해 약 5억원의 매출을 올렸습니다.
15개 과제 중 현재까지 7개의 과제에 대해서 후보물질 발굴 실험결과가 나왔으며, 저희 데이터 가공 및 분석 방법을 통해 7개 모든 과제에서 성공적으로 유효물질을 발굴 할 수 있었습니다.
신기술 도입에 보수적인 제약업계의 분위기를 고려하면 매우 빠르게 성장하고 있는 서비스입니다.
서비스 예상 수요국내에는 이 서비스와 직접적으로 연관된 신약개발 프로젝트 500개를 포함하여 1500개 이상의 신약개발 프로젝트가 진행되고 있습니다.
신약개발 회사는 1000곳 이상입니다.
이러한 상황을 고려하였을 때 데이터 바우처 사업을 통해서 50건 이상의 서비스 요구가 있을 것으로 예상됩니다.
한국신용데이터 소개
- 한국신용데이터은 2016-06-01에 설립되었습니다.
- 주소 : 서울 강남구 테헤란로 127 4층
- 주요 서비스 : ○ 수요 기업 니즈에 맞는 데이터 가공 서비스 제공
– 수요기업 니즈에 맞는 당사 수집 데이터 커스터마이징 서비스 (이상치 처리 및 AI 학습용 데이터 구축 등)
– 수요기업의 니즈에 따른 맞춤형 컬럼 기준으로 기초 통계량 산출, 분포 및 변수 간의 관계 분석 서비스
– 상권 분석 및 시장 동향 파악에 필요한 소상공인 데이터와 공공 및 기타 데이터 융합 서비스
– 시각화 가공을 통해 분석 가능한 형태로 변환해 정보화 및 시각화(그래프, 라벨링, heat map, 주관식 설문 응답 데이터 기반 text cloud 등) 처리 진행
– #전처리#품질#AI학습용 데이터 구축#분석#시각화#정보추출#코딩#기타 - 보유 솔루션 : ○ 안정적인 데이터 가공 시스템 환경 구축
– 당사의 데이터플랫폼은 AWS의 데이터 인프라와 내부 개발된 데이터 관리 시스템의 통합 플랫폼으로, 데이터 수집 과정을 자동화·모니터링하여, 데이터의 품질 및 장애에 대응하도록 구축
– 수집된 데이터는 S3에 저장되어 대용량 저장, 파일 손상의 이슈를 해결하고 있으며, 여러 데이터 수요처의 요청에 대응하여 다양한 환경을 제공하기 위하여 데이터를 API로 제공할 경우 ECS를 활용
– 저장된 데이터 처리 시에는 대용량 분산처리 도구인 Spark를 통해 가공하고 있으며, 관련한 파이프라인은 내부 개발 프로그램을 통해 중앙 통제 및 이력 관리 되고 있음
– 가공된 통계 데이터는 RDS 상에서 외부 파트너사 제공에 이용되며, 수요기업의 환경에 맞추어 파일/API 등의 다양한 인터페이스로 제공 가능한 시스템 환경을 갖추고 있음 - 품질 확보 전략 : ○ 정확하고 시의성 높은 소상공인 데이터 제공
– KCD의 데이터는 매일 업데이트 되고 있어, 가장 최신의 시장 동향을 파악할 수 있도록 도울 수 있습니다.
– 특히, KCD의 카드 매출 데이터는 특정 카드사의 정보만을 제공하는 것이 아니라 9개 전체 카드사(롯데,BC,삼성,신한,하나,현대,KB,농협,우리) 매출 데이터를 기반으로 정보를 제공하여 정확도 높은 매출 정보 제공이 가능한 것이 특징입니다.
– 데이터 관리 플랫폼을 통해 수집/처리 단계에서의 데이터 흐름을 자동화/모니터링하여 데이터 품질 및 장애에 대응하도록 구축되어 있어, 품질 위험 요소를 차단하고 있습니다.○ 서비스 제공 단계별 고객 대응 체계 구축
– 데이터 판매/가공 서비스 제안 단계부터 고객의 니즈에 맞는 상품을 설계 제안하여 사전 협의를 진행,사업을 통해 수요기업이 얻고자 하는 핵심 요소를 도출하도록 도와드립니다.
– 협의한 데이터는 정확성,완전성,적시성,일관성 등 데이터 품질 요소 점검 과정을 거쳐 수요기업에게 제공됩니다.
– 데이터 제공 이후 이상 발생 시 데이터 수집 인프라 및 가공 로직 단계부터 오류 검증을 시행하여 재발을 방지하고 있으며, 수요기업과 충분한 협의를 통해 오류 사항을 보완하여 드리는 유지관리 체계를 구축하고 있습니다. - 유지보수 전략 : ○ 유지 보수 체계
-데이터 컬럼의 누락, 데이터 유효성 결함과 같이 사전 협의된 요구사항의 미충족 사항 등 공급한 목적물에 하자가 있는 경우, 무상 하자 보수를 원칙으로 하며,협약 기간 및 협약 종료 후 6개월 이내 발생하는 데이터 결함에 대해 유지 보수를 지원해드립니다.
– (단,천재지변에 의한 장애 또는 데이터 제공 이후 요구사항 변경 요청에 대해서는 책임을 지지 아니하며 이로 인한 데이터 오류의 수정은 유상 유지보수 원칙을 따름)
– 사전 협의된 데이터 외 추가 데이터 요구(신규데이터 추가 또는 데이터 구성 변경 등)시에는 수요기업과의 협의에 따라 추가 데이터를 제공하며,실비 제공을 원칙으로 하고 있습니다.
– 수요기업이 요구하는 유지보수 내용이 사전 협의한 업무 범위를 벗어나는 경우에는 별도 계약을 체결하는 프로세스로 진행됩니다. - 카테고리 구분 : 전처리,품질,코딩,시각화,정보추출또는조합,태깅또는라벨링,분석,기타
- 실적 : 기관명수행연도사업내용지원기관한국신용데이터2021
-2023빅데이터 플랫폼·센터 지원사업(빅데이터 기반 소상공인 데이터센터 구축)NIA(한국지능정보사회진흥원)2021본인신용관리업(마이데이터)라이선스 획득금융위원회2020
-2023데이터바우처 공급기업 등록 및 운영Kdata(한국데이터산업진흥원)2019마이데이터 실증서비스과학기술정보통신부(한국데이터산업진흥원)2017데이터 활용 사업화 지원사업(DB
-Stars)(소상공인을 위한 매출 관리 서비스)과학기술정보통신부(한국데이터산업진흥원)2016
-2018민간투자주도형 기술창업지원사업(TIPS)수행(금융거래 데이터 기반소상공인 상환능력 자동분석)중소벤처기업부(한국엔젤투자협회) - 기업 개요 및 핵심역량 : ○ 전국 120만 소상공인의 데이터를 보유한 데이터 비즈니스 기업
– 한국신용데이터(KCD)는 소상공인 경영 관리 서비스 ‘캐시노트’를 통해 전국 120만여 소상공인의 매출, 매입, 배달 매출 등 경영 정보를 확보, ‘데이터’를 ‘연결’하여 다양한 사업자를 돕고자 하는 비전을 가지고 있습니다.
– 소상공인 동향 파악, 코로나
-19로 인한 소득 감소 피해 상황 입증, 창업 지원을 위한 상권 분석, 자영업자 대상 초개인화 마케팅 및 서비스 고도화 등 다양한 영역에 있어 필요한 폭넓은 데이터를 제공합니다.
– 실제 정부 기관 및 관계 부처에서도 소상공인 대상 지원 정책 효과 파악 등에 활용하고 있으며 언론사의 보도 기초자료, 창업지원을 위한 상권 분석을 위해서도 KCD 데이터가 활용되고 있습니다.
– 이러한 서비스 제공을 통해 갖춘 데이터 가공 및 분석 역량은 국내 최고 수준이며, 특히 한국신용데이터의 가공 서비스는 단순 가공을 넘어 고객사 니즈가 있는 경우 당사가 보유하고 있는 소상공인 경영 데이터와 융합 가능한 형태로 서비스할 예정입니다.
– 수요기업에서 소상공인 관련 시장 전반에 걸친 인사이트 발굴을 지원, 비즈니스 의사결정에 더 나은 답이 나올 수 있도록 돕고자 합니다. - 활용 사례 : ○ 당사 보유 데이터를 활용한 가공 서비스 제공
– 당사에서 보유한 소상공인 매출액 데이터를 매출 발생 시간대별로 가공하여 손님 없는 시간 예측을 위한 AI 학습용 데이터셋 구축 사업 수행
– 수요기업이 보유한 정성 데이터(설문 데이터값)와 당사 소상공인 면적 단위당 카드 매출액 데이터 융합 프로젝트 수행으로 새로운 인사이트를 확보하고 수요기업 시스템 고도화 달성
(주)다래전략사업화센터 소개
- (주)다래전략사업화센터은 2015-10-01에 설립되었습니다.
- 주소 : 서울 강남구 테헤란로 132 11층, (역삼동, 한독약품빌딩)
- 주요 서비스 : 당사의 IP 가공서비스 상품은
1) 선행기술조사,
2) 무효자료조사, 3) 침해자료조사, 4) 특허동향조사, 5) 맞춤형 특허맵, 6) IP
-R&D, 7) 기술가치평가, 8) 기술거래, 9) R&D 기획으로 구성되고, 수요기업의 R&D기획, R&D개발 및 사업화 단계까지 전반적인 기술사업화 방향을 설정하는데 활용할 수 있음 <; 주요 가공서비스 상세 정보 >활용안서비스 목록서비스 내용유사기술여부 조사선행기술조사·조사대상이 되는 기술내용(기술요소)를 명확히 하고, 각 기술요소에 관련된 특허를 조사하여 특허성(신규성, 진보성)여부 조사IP리스크 사전 방지무효자료조사·R&D 기술과 유사한 타사 등록 특허권을 무효화하기 위한 조사 침해자료조사·R&D 기술과 동일, 유사한 기술이 형성되어 있는 타사의 등록 특허권 조사연구개발 방향성 설정특허동향조사·R&D 기술에 대한 국내외 기술동향조사 :R&D 기술과 연관된 특허 분석을 통해 R&D기술의 현황(국가별·연도별·권리자별 등)정보, 기술선도 기업 파악, 핵심특허 도출 및 경쟁력 분석 등 R&D추진을 위한 방향성 조사IP리스크 사전 방지/ 연구개발 방향성 설정맞춤형 특허맵·R&D 기술과 관련된 수요기업 니즈에 대응한 맞춤형 특허분석 :경쟁기업 기술개발동향 분석 :문제기술 해결을 위한 분석 :특허리스트 예방을 위한 분석유망 IP창출/연구개발 방향성 설정/신기술사업 발굴IP
-R&D·R&D 기술과 관련하여 경쟁사 특허 포트폴리오 분석, 관련 기술 분야의 공백기술 분석, 문제특허 대응, 신규 IP 창출 등을 수행하여 IP에 기반한 R&D전략 수립 :R&D 사업 기획 :R&D 방향 설정 :R&D 고도화 :신사업 발굴 방향 설정 기술거래/투자유치 등기술가치평가·R&D 기술에 대한 가치를 평가 :IP에 기반하여 R&D 기술의 우수성, 독창성, 차 - 보유 솔루션 : 당사는 특허 및 시장분석을 위한 유료 DB를 보유하고 있으며, 수요기업의 니즈에 따라 미국, 유럽, 일본, 중국을 포함하는 전 세계 특허 데이터를 조사 및 분석하여 제공할 수 있도록 담당자별 개별 아이디를 배정하여 원활하고 신속한 업무 수행이 가능하도록 함 <; 보유 DB 현황 >구 분DB명DB내용보유현황특허검색데이터베이스WIPS
-ON 미국, 유럽, 일본, 중국 등 전 세계 90개국 이상의 특허통합 DB를 동일 Site에 구축하여 Web상에서 검색 가능한 특허검색엔진유료계정 50개 보유(담당자별 아이디 배정)바이오시장정보 데이터베이스Datamonitor healthcare글로벌 제약·바이오 시장정보 데이터 베이스유료계정보유 - 품질 확보 전략 : IP 가공서비스의 품질확보를 위한 단계로,
1)정기적인 내부 진도 점검을 진행하고, 그 결과를 수요기업에 송부하여 피드백을 받고 수정·보완을 진행하며,
2)맞춤형 전담 책임자가 IP 가공서비스를 완료하면 총괄책임자가 크로스 체크하고, 3)품질관리 전담인력이 최종 검수하여 지속적인 품질확보 체계를 구축함
1) 정기적인 내부 진도 점검 및 수요기업 피드백 반영 정기적 진도 점검은 IP 가공서비스를 담당하는 총괄 책임자, 전담 책임자, 지원인력으로 구성되어 기업 니즈에 부합하는 데이터 수집 및 가공이 적합하게 이루어지고 있는지 점검하고, 해당 결과를 수요기업에 송부하여 피드백을 받고 수정이나 보완을 진행하여 완성도 높은 IP 가공서비스 품질을 확보함
2) 이중 크로스 체크 IP 가공서비스별 전담 책임자는 본인 과제에 대한 엄격한 검수가 어렵기에 총괄 책임자가 크로스 검수를 진행하고, 이후 품질관리 전담인력이 최종 검수하여 완성도 높은 IP 가공서비스 품질을 확보함 <; 품질 확보 전략 >1단계정기적 내부 진도 점검 수요기업 니즈에 맞는 데이터 수집 및 가공 방향 점검2단계정기적 외부 피드백 보완 수요기업의 정기적 피드백에 따른 데이터 보완3단계이중 크로스 체크 과제 책임자 + 품질관리 책임자가 IP 가공서비스 최종결과물에 대한 이중 크로스 체크 - 유지보수 전략 : ㈜다래전략사업화센터는 R&D사업기획, R&D방향설정 등의 R&D전략지원, IP컨설팅, IP조사분석 등의 IP전략지원, 기술가치평가, IP금융 직접투자, 기술사업화·마케팅 등의 Biz전략지원을 수행하고 있어 이와 관련된 다양한 연계 지원 사업에 대한 컨설팅이 가능하고, 관련 네트워크를 보유하고 있어 기업의 사업 경쟁력 확보 및 지속적 성장을 위한 후속 연계 지원이 가능함 (과제연계 지원) 수요기업 보유 기술의 R&D 단계, 사업화 단계 등을 고려하여 관련된 지원 사업을 소개하여 R&D 기술의 완성도 및 사업화 촉진을 이룰 수 있도록 지원함 (역량강화 지원) 당사의 자체 사업화 관련 교육 프로그램 참여 등을 통해 수요기업의 역량강화를 지원함 (성장 지원) 스타기업, 선도기업, 아기 유니콘, 글로벌 강소기업, 월드클래스 플러스, IPO 지원 등 기업 단계별 맞춤형 성장 및 역량강화를 지원함
- 카테고리 구분 : 전처리,시각화,정보추출또는조합,분석
- 실적 : < 주요 사업 실적 > 구분주요 사업명 발주처IP컨설팅 지원IP
-R&D전략지원 사업 WC300 R&D 전주기 IP전략수립IP나래 지원사업특허기술동향조사 사업국제 지재권 분쟁 대응전략 지원 사업 등한국특허전략개발원지역지식재산센터 등R&D기획 및 사업화 지원R&D기획 지원사업 중소기업 네트워크형 기술개발사업스타/선도기업 육성사업 컨설팅 사업사업화연계기술개발사업(R&BD) 청년창업기업 사업화컨설팅 지원사업 등중소기업기술정보진흥원지역지식재산센터 한국보건산업진흥원 등 - 기업 개요 및 핵심역량 : ㈜다래전략사업화센터는 기업의 R&D와 비즈니스를 지원하는 전문 컨설팅 회사로서, 창업지도사, 투자전문가, 석박사급 기술전문가, 변리사, 미국 변호사 등의 전문가들로 구성되어, 역량 있는 스타트업을 발굴하고 투자하며, R&D기획에서부터 IP(Intellectual Property(지식재산), 이하 IP)컨설팅, 기술가치평가, 기술거래, 기술사업화, M&A컨설팅까지 기업 생태계 전주기를 아우르는 Total Service를 제공하고 있음 특히, IP데이터 수집 및 분석을 통한 가공서비스 분야에서 수년간 정부R&D 특허동향조사사업 외 중소기업 맞춤형 특허맵, IP
-R&D특허전략 지원, IP활용전략 사업 등을 수행하며 다양한 노하우와 경험을 쌓아옴에 따라, 해당 사업을 수행할 수 있는 우수한 역량을 갖추고 있을 뿐만 아니라 정부기관으로부터 인증을 통해 전문성을 확보하고 있음 <; 주요 지정 내용 >주요기관지정 내용산업통상자원부사업화 전문회사 지정산업통상자원부기술거래기관 지정중소벤처기업부R&D 기획기관 선정중소벤처기업부엑셀러레이터 등록중소벤처기업부팁스(TIPS) 협력사(공동운영) 지정특허청산업재산권진단기관 지정한국특허전략개발원IP
-R&D특허전략지원, 특허기술동향조사 수행기관지역지식재산센터IP나래, 맞춤형 특허맵 수행기관한국거래소M&A 중개 협력기관 지정 또한, ‘2019년도 하반기 KISTA
-협력기관 협의회 정기회의’에서 민간부문 우수상, ‘21년 지식재산바우처 사업 IP서비스 우수기관 수상, ‘22년 지식재산바우처 사업 IP서비스 최우수기관을 수상하여 대외적으로 IP분석 분야의 First Mover 자리를 굳건하게 유지하면서 분석업무 품질의 신뢰성을 획득하고 있음 * 22년 스타트업 지식재산바우처 사업 ‘IP서비스 최우수기관’ 선정 * 21년 스타트업 지식재산바우처 사업 ‘IP서비스 우수기관’ 선정 * 19년 한국특허전략개발원 우수 - 활용 사례 : 당사의 IP 가공서비스를 통해 수요기업의 아이템 발굴을 위한 R&D 기획 단계부터 고도화 단계까지 IP기반의 기술사업화 전략에 활용할 수 있음 신기술의 특허성 판단, 경쟁사 특허의 무효화 전략이나 문제 IP회피를 위한 선행기술조사·무효자료·경쟁사동향 조사로 IP리스크를 사전 방지하고, 보유 IP의 유지관리를 위해 권리성· 시장성·기술성을 평가하여 IP활용방안 재고 및 IP포트폴리오 작성 등에 활용할 수 있음 수요기업의 맞춤형 특허맵, 특허기술 로드맵 제공을 통한 연구개발의 방향성 설정 및 신기술사업 발굴에 활용할 수 있음
플리토 소개
- 플리토은 2012-08-24에 설립되었습니다.
- 주소 : 서울 강남구 테헤란로 211 9층, 주식회사 플리토
- 주요 서비스 : 데이터 가공 서비스 소개플리토는 수요기업이 보유한 언어데이터(텍스트, 음성, 이미지 데이터) 또는 당사가 보유한 데이터를 수요기업 요구사항에 맞게 가공서비스를 제공합니다.
자체 플랫폼내 크라우드소싱을 활용한 인공지능 학습용 데이터의 수집, 가공, 검증과정은 보상 지급을 통하여 플랫폼 내에서 활동하는 수많은 유저들의 자발적인 참여를 통해 이루어지며유저들은 플랫폼 내에서 자신들의 언어 실력에 대해 자체 테스트를 통한 검증과정을 거쳐 레벨을 부여받고 활동할 수 있기 때문에 양질의 데이터수집 및 가공이 가능합니다.또한, 플랫폼 내에서 유저 레벨에 따라 검증 권한을 가지고 있는 각 언어의 일정 레벨이상 실력자들이 수집된 데이터들을 3~8회 추가 검증 후 다시 사내 전문인력을 통한 재검수 과정을 거쳐 정확도 높은 고품질의 학습용 언어데이터를 생성합니다.가공서비스의 상세정보플리토는 텍스트 데이터, 음성데이터, 이미지 데이터의 가공서비스를 제공합니다.세가지 가공서비스는 대부분 플리토 집단지성 플랫폼을 통해 이루어지기 때문에 단시간에 저렴한 비용으로 가공이 가능하며, 앞서 설명한 3~8회 집단지성 검수 및 사내 전문 인력의 추가 검수 과정을 거치기 때문에 정확도 높은 데이터를 납품할 수 있습니다.
1) 텍스트 데이터 가공데이터 가공 종류채팅데이터 생성 (멀티턴,주제, 페르소나등 커스터마이징된 대화문 생성 가능)다국어 번역을 통한 병렬코퍼스 생성도메인태깅Named
-entity recognition (개체명인식) Text classification(텍스트분류)Intent recognition (의도인식)Sentiment Analysis (감정분석)
2) 음성 데이터 가공데이터 가공 종류음성 녹음 (상황, 연령, 성별, 주제 등 메타 데이터별 데이터 수집)음성 전사(Audio Transcription) 및 번역파일 분할분할 전사Disfluency tagging 3) 이미지 데이터 가공데이터 가공 종류이미지 데이터 수집 (메뉴판, 안내판, 손글씨 등 다 - 보유 솔루션 : Flitto STT (음성 인식 엔진)Flitto NMT (자동 번역 엔진)Flitto OCR (이미지내 텍스트 추출 엔진)
- 품질 확보 전략 : 플리토 데이터 소개 영상 :https://kdata.or.kr/datavoucher/is/selectPortalSearch.do
- 유지보수 전략 : 데이터 바우처 전담팀 운영을 통해 수요기업 맞춤형 데이터 컨설팅 지원데이터바우처 사업 지원 및 운영 프로세스 전반 컨설팅 지원사업종료 후 6개월 이내 부적합 데이터 발견시 재검수를 통한 수정데이터 납품
- 카테고리 구분 : 전처리,품질,정보추출또는조합,태깅또는라벨링
- 실적 :
- 기업 개요 및 핵심역량 : 회사명 : 주식회사 플리토플리토 데이터랩 공식영상 :https://kdata.or.kr/datavoucher/is/selectPortalSearch.do
- 활용 사례 : 텍스트데이터 활용 분야NMT기반 인공지능 자동번역기 개발 기초 데이터
– 기업이나 기관에서의 자동통번역기 개발을 위한 기초 학습데이터로 활용.번역기 개발용 데이터
– 자동번역기 개발을 위한 병렬 코퍼스
– 특화번역기 개발을 위한 증분학습하여, 특정 분야에특화된 번역기 개발에 활용챗봇 개발을 위한 데이터
– AI기반의 챗봇 엔진을 위한 학습용 데이터나,룰베이스 기반의 챗봇 시스템의 데이터베이스로 활용NLP기반 텍스트 자동완성 엔진 학습
– NLP기반의 텍스트 자동 완성 엔진의 학습용 데이터로 활용음성 데이터 활용 분야STT(Speech
-to
-Text), TTS(Text
-to
-Speech) 엔진 개발STT(Speech
-to
-Text), TTS(Text
-to
-Speech)등 기업이나 기관에서의 음성인식엔진 또는 칩 개발을 위한 기초학습데이터 및 다양한 상황에서의 음성인식률 향상을 위한 증분 학습용 데이터로 활용음성 번역 엔진 개발음성 다국어 번역을 통해 음성 번역 엔진 개발을 위한 데이터로 활용Auto Transcription Engine (자동 전사 엔진 개발)다양한 발화자의 음성 학습을 통한 영상 및 오디오의 자동 전사 엔진 개발을 위한 데이터로 활용이미지 데이터 활용 분야Computer vision, OCR엔진 개발손글씨,문서,상품등의OCR인식률 개발 및 인식률 향상을 위한 데이터로 활용이미지, 메뉴번역 서비스 개발이미지 다국어 번역, 메뉴번역 등 다양한 다국어 이미지 서비스 개발
아이디비 주식회사 소개
- 아이디비 주식회사은 2020-03-25에 설립되었습니다.
- 주소 : 서울 강남구 테헤란로 216 신웅타워 12층 112호
- 주요 서비스 : 1.
데이터 가공 서비스■기업 주요 서비스 및 제품 ● 실시간 설비 모니터링 ● 실시간 공정 품질 관리 모니터링● 실시간 제조 환경 모니터링 ● 실시간 에너지 모니터링 ● 적정 재고 관리 시스템 ● 설비 예지보전● 최적 설비 운전 조건 모니터링 ● 최적의 레시피 예측 ● 수요 예측 및 최적 재고 운영 ● 고객 분석 및 맞춤형 제품 추천 ● 지능형 화재, 안전, 보안 모니터링 ● 불량 이미지, 텍스트 분석 및 품질 판별■ 서비스 주요 기술● 서비스 기능기능 목록대중소설명데이터가공 및 시각화 데이터 수집 및 저장데이터수집 ·IoT, 설비, IT 시스템 DB와 연계하여 분석을 위한 유관 인자를 추출하여 수집하는 인터페이스 제공데이터 저장·원천 데이터, 전처리 데이터, 학습 데이터, 검증 데이터, 예측 데이터 등 데이터 처리 과정 별 데이터 마트 구성 데이터 처리데이터 품질 개선 처리·데이터 품질 수준의 향상을 위한 데이터 오류 처리로 값 누락, 이상치, 원소개수, 데이터 잡음, 시계열 데이터 변환 등의 처리시계열데이터맵핑 ·종속변수에 영향을 주는 독립변수의 기준 시간대별 시계열 데이터 맵핑 처리 배치단위 처리·IoT, 설비 연관 데이터 추출하는 스케쥴링 기능과 데이터 맵핑 기능 제공타 시스템 연동 인터페이스·IoT, 설비의 공정 데이터, 원료 정보가 수집된 타 시스템 및 디지털 트윈 시스템과 연동하는 인터페이스 제공시각화통합관제·전체 현황, 단위현황, 세부 상세현황별 모니터링 시스템 구현알람 상황 관제·실시간 데이터를 모니터링하고 이상 시 알람 발생2.
AI 가공 서비스■ AI 가공서비스 상품성● IoT 및 설비 상태 예측, 최적 공정 예측, 설비 예지보전, 이상패턴 분석, 레시피 예측을통한 생산성, 설비 가동성, 품질 능력 향상● 고객 구매 성향에 따른 제품 추천 마케팅 애플리케이션 연동 기능 제공 ● 제품 판매, 구매 데이터에 따른 수요 예측, 적정 재고율 관리 ● 제품 공정의 불량 이미지 판정, 인쇄오류 판단, 인쇄물 및 게이지의 데이터 값 - 보유 솔루션 : ■ 기업 핵심역량 ● 제조현장에서 발생하는 IoT 데이터의 수집, 분석 및 시각화하는 융합 기술 ○ IoT 기술 ·제조설비의 데이터를 IoT 통신 하드웨어로부터 데이터를 수집하고 IoT 표준 통신 프로토콜을 통해 데이터 전송, 수집 및 처리하는 기술 보유 ○ AI 제조 분석 기술 ·설비로부터 수집된 센서 데이터, 설비 Tag 데이터를 시계열 데이터 베이스로부터 수집하고 전처리한 후 분석하여 AI 모델링하는 기술 · IoT 센서로부터 수집된 데이터를 AI Edge computing 과 클라우드 학습단을 활용한지능형 IoT 센서 기술 ·설비의 비정상 상태 예측, 이상패턴 분석, 최적 설비 공정 조건 도출, 레시피 추천 모델링과 같은 설비의 최적 운영을 위한 AI 분석 기술 ○ 시각화 기술 ·실시간 기반의 데이터 모니터링 시스템 ·지도맵, 제조현장의 가상공간상에 IoT 설비 데이터를 맵핑하여 직관적인 데이터 인사이트제공 기술 ·데이터 결과와 원인을 인과관계, 상관관계에 대한 계층으로 맵화하여 상위
-하위 맵 구성한 데이터 시각화 기술■ 주 사용 언어언어활용 기능 파이썬·딥 러닝에서는 모든 현행 라이브러리(텐서플로우, 파이토치, 체이너, 아파치MX넷, 테아노 등) 프로젝트가 사실상 파이썬을 가장 우선해 개발됐기에예제로 활용할 많은 소스코드가 있어 활용 중·Tensorflow를 활용해 활용도 높은 Python으로 프로그래밍·파이썬의 수학 및 통계 라이브러리 활용·광범위하게 사용되는 넘파이(NumPy)는 텐서 연산에서 표준 API 사용.
·판다스(Pandas)를 통해 R의 강력하고 유연한 데이터 프레임을 파이썬에서 사용·자연어 처리(NLP)에는 유명한 NLTK와 빠른 속도를 자랑하는스페이시(SpaCy)를 통해 고객의 긍정, 부정, 피드백 분석·머신러닝의 경우 실전에서 검증된 사이킷
-런(Scikit
-learn) 활용 텐서플로우·현재 가장 범용적으로 사용되는 딥 러닝 프레임워크로 사용 중 ·프로그램을 개발하기에 Python언어로 제공되는 유용한 기능들도 많고네이티브 AP - 품질 확보 전략 : 1.
품질 보증 내용가.
전사적 품질관리지원조직 필요나.체계적인 품질관리계획 수립다.
내/외부 전문가를 통한 품질관리라.
사업수행 이후의 품질관리 정책마.
체계적인 진도관리 및 변경관리2.
품질 보증 전략가.
품질관리 전문가 투입나.
제안사의 품질관리 방법론을 바탕으로 체계적인 품질보증 활동 수행다.
전사 품질관리지원조직 활용리.
사후 품질보증 지원활동 수행마.
품질관리교육을 통한 팀원 공유3.
품질 도출 전략가.
품질관리 프로세스 준수나.
품질관리실의 적극적인 활용다.
품질보증활동 등 사후지원4.
소프트웨어 엔지니어링 활동 검토품질보증 계획이 수립되면 소프트웨어를 생산하는 개발활동에 대한 검토를 실시한다.
이과정을 통하여 산출물을 생산하기 위해 프로세스를 어떻게 운용하였는가와 프로젝트 수행상의 애로사항들을 파악해 낼 수 있다.
이는 다음단계의 품질 측정 및 평가를 위하여 매우 중요한 활동5.
데이터 품질 지수가.
완전성(Completeness) : 필수항목에 누락이 없어야 한다.나.
유일성(Uniqueness) : 데이터 항목은 유일해야 하며 중복되어 서는 안된다.다.유효성(Validity) : 데이터 항목은 정해진 데이터 유효범위 및 도메인을 충족해야 한다.라.
일관성(Consistency) : 데이터가 지켜야 할 구조, 값, 표현되는 형태가 일관되게 정의되고, 서로 일치해야 한다.마.
정확성(Accuracy) : 실제 존재하는 객체의 표현 값이 정확히 반영이 되어야 한다 - 유지보수 전략 : 1.
무중단의 신뢰성있는 서비스 제공가.
최적의 시스템 운영 환경 유지나.
무중단 안정적인 시스템다.
경험있는 인력중심 유지보수라.
콜센터 및 원격으로 안정화 지원마.
예방점검 서비스바.
One
-Call 서비스2.
하자보수가.
체계적이 유지 보수 절차에 따라 진행나.
하자보수 사항에 대한 신속한 파악 및 대응다.도입 시스템에 대한 완벽한 유지보수 실시3.
장애복구가.
갑작스런 시스템의 장애 발생시 발생한 장애 유형에 따른 신속한 복구 조치4.
운영지원시스템의 안정적인 운영 지원향후 발전에 대한 기술 자문을 포함한 기술 지원 - 카테고리 구분 : 전처리,품질,코딩,시각화,정보추출또는조합,태깅또는라벨링,분석
- 실적 : NO용역기간용역명주요내용1‘20.11.01~’21.08.06관제 모니터링 시스템 제작 부품가공 및 데이터 분석 및 실시간 모니터링 관제 시스템 구축 용역데모 공장 구축 (3D 공장 가상화, OPC
-UA 설비 데이터 분석 및 모니터링 시스템 구축)2‘20.11.01~’21.08.03무인원격 Visibility 구성데모 공장 구축(3D 공장 가상화, OPC
-UA 설비 데이터 분석 및 모니터링 시스템)3‘20.07.31~’20.11.302020 대중소상생형 (현대자동차그룹)스마트공장 구축(유형 1
-B)MES, 설비 데이터 수집 및 분석 데이터 시각화 4‘21.06.01~’21.07.07석유화학 예지보전 솔루션 프로젝트 석유화학공정의 설비예지보전 분석(위험도, 리스크 스코어, 주요인 분석 등) 데이터 분석, 시각화 5‘21.05.01~’21.05.31제조현장 환경모니터링 (모바일 모니터링 App)IoT 공기질 모니터링 시스템 6‘21.06.29~’21.11.30농업용 자동차 제조사 통합모니터링 구축 프로젝트 라인, 설비 데이터 분석 및 모니터링 시스템 7‘21.04.01~’21.12.30AI지역특화 솔루션 실증(바이오헬스산업)제조 공정 이상 패턴 예측 및 탐지 모니터링 시스템 8‘21.08.01~’21.10.31반도체 후공정 모니터링 시스템 AI기반 부적합 이상판정 및 모니터링 시스템 9‘21.09.01~’21.09.30AI 기반 에너지 이상 진단 시스템 환경센싱 이상 패턴 모니터링 시스템 10‘21.09.01~’21.10.29열화상 이미지센서를 이용한 AI 에너지 관리 시스템열화상 및 영상 데이터 분석을 통한 설비 및 에너지 시스템 이상 모니터링 시스템11‘21.06.01~’22.02.28AI기반 제조설비의 이상진단과 비대면 챗봇 대응 시스템설비 및 IoT 데이터의 AI 엣지 컴퓨팅 분석 및 모니터링 시스템 12‘21.11.01~’22.04.07AI기반 설비예지보전 및 공정 분석 시스템세라믹 센터 설비예지보전, 공정분석, CPS 구축13‘21.10.01~’ - 기업 개요 및 핵심역량 : 아이디비(주)는 IoT, AI 분석, 시각화 기술을 융합하여 새로운 패러다임을 주도하는 소프트웨어 기업입니다.아이디비(주)는 스마트 팩토리, 시티, 홈, 빌딩 및 인프라 산업에 적용될 수 있는 IoT 임베디드 시스템, 애플리케이션 및 IoT 데이터로 부터 수집된 데이터를 기반으로한 데이터 분석과 시각화 기술을 통해 통합 모니터링 구축 사업을 하고 있습니다.IoT, AI, Data Visualization 융합 기술을 활용하여 기업의 디지털 트랜스포메이션을 현실적으로 적용 할 수 있는 제안뿐만 아니라 고객의 문제를 해결하고자 하는 실제적인 AI 모니터링 시스템을 구축 하고 있습니다.
- 활용 사례 : 1.
데이터 가공 및 시각화■ 활용 예시 ● 실시간 IoT 센서 모니터링 ● 실시간 설비 모니터링 ● 실시간 공정 품질 관리 모니터링 ● 실시간 제조 환경 모니터링 ● 실시간 에너지 모니터링● 적정 재고 관리 시스템■ 성과 활용 예시도입효과실시간 IoT 센서 모니터링·실시간 IoT 센서 데이터를 모니터링 ·임계치 설정 대비 초과시 알람 발생실시간 설비 모니터링·실시간 설비 상태 진단·설비 가동률을 증가시켜 생산성 향상, 설비수명 개선·설비 관리비용 및 생산원가를 절감실시간 공정 품질 관리 모니터링·실시간 생산 중 공정 품질관리·불량을 조기에 발견·생산 품질 향상 및 품질관리 비용 절감실시간 제조 환경 모니터링·신속한 생산, 작업 환경변화 대응·돌발변수를 최소화하여 사고 및 불량 저하 실시간 에너지 모니터링·에너지 사용량을 모니터링·사용량과 환경에 따른 에너지 소비현황 조회 적정 재고 관리 시스템·재고 창고 Rack 별 현황, 유효기간, 고객 납품 대비 출하에 대한 관리 효율화 2.
AI 가공 서비스■ 활용 예시 ● 설비 예지보전 ● 최적 설비 운전 조건 모니터링 ● 최적의 레시피 예측 ● 수요 예측 및 최적 재고 운영 ● 고객 분석 및 맞춤형 제품 추천 ● 지능형 화재, 안전, 보안 모니터링● 불량 이미지, 텍스트 분석 및 품질 판별■성과활용 예시도입효과설비 예지보전·설비에 영향을 주는 요인을 분석하여 최상의 서비 조건으로 운영하고 특정시점에 설비 고장 이상을 사전 예측하여 알람최적 설비 운전 조건 모니터링·제품별 설비 운전조건 데이터를 통해서 최적의 운전조건을 제시하고 모니터링 하는 시스템 최적의 레시피 예측 ·제품별, 설비별 투입되는 원료의 배합비를 산출하여 제시하는 분석 시스템 수요 예측 및 최적 재고 운영·고객별, 시기별, 제품별 계절성 주기와 특성 요인에 따라 수요를 예측하고 적정 재고 모니터링 시스템과 연동고객 분석 및 맞춤형 제품 추천·소비자 구매성향에 기반한 고객 맞춤형 제품 추천·고객 선호 제품에 대한 시장, 고객 분석 통
주식회사 닥터웍스 소개
- 주식회사 닥터웍스은 2020-11-11에 설립되었습니다.
- 주소 : 서울 강남구 테헤란로 242 1407호
- 주요 서비스 : 개인정보 보안 기준에 맞춘 데이터 전처리(정제), 인공지능 이해도와 임상지식을 보유한 의료진의 데이터 가공/검수, 전문적이고 체계적인 품질검증, 의료 AI 개발 경험이 풍부한 의료진의 컨설팅 으로 압도적인 의료데이터 퀄리티를 보장합니다.
- 보유 솔루션 : 닥터웍스는 VPN과 보안 의료 가공 플랫폼, 자체 서버와 NAS, 그리고 전문의 대상 교육을 통해, 의료데이터 구축 시 가장 중요한 보안 이슈를 사전에 방지합니다.
- 품질 확보 전략 : 품질 확보 전략은 다음과 같습니다.1.
닥터웍스는 의료데이터에 특화된 “닥터웍스 보안 의료 가공 플랫폼”을 개발하였고, 고객사 요구사항에 맞춰 커스터마이징이 가능하게 설계되었습니다.
다만, 3D 레이블링과 사용자 편의기능을 더 보강하기 위해 차세대 플랫폼을 개발 중입니다.2.
국내 의료데이터 구축이 더 세분화 됨에 따라, 세부전공에 따른 전문의들이 부족한 실정입니다.
예를 들면 치과 전문의만 보더라도, 구강악안면외과, 구강내과, 구강병리과, 소아치과, 예방치과, 영상치의학과, 치과교정과, 치아보존과, 치아보철과, 통합치의학과 로 총 11개의 세부전공이 존재합니다.
같은 치과 전문의더라도 세부 전공에 따라 소견이 다르기 때문에 세부전공은 중요합니다.3.
인공지능 이해도가 높은 PM과, 임상간호사 출신의 PM을 채용 및 상시 교육을 통해, 보다 높은 프로젝트 매니징이 가능합니다. - 유지보수 전략 : 닥터웍스는 기본적으로 데이터바우처의 유지보수 정책을 준수합니다.
그리고 별도 협의를 통해 유지보수 및 후속지원의 자원을 아끼지 않습니다. - 카테고리 구분 : 전처리,품질,태깅또는라벨링,분석,기타
- 실적 : 닥터웍스는,1.
주요 기업고객으로는, 네이버, 삼성, SK, KT, 롯데, 셀바스AI, 웨이센, 스탠다임, 패스트레인, 마인즈앤컴퍼니 등이 있습니다.
2.
주요 병원고객으로는, 서울대병원, 분당서울대병원, 서울성모병원, 경희의료원, 이화여자대학교의료원, 순천향대학교중앙의료원, 아주대학교의료원, 한림대학교의료원, 가천대길병원, 인하대병원, 부산대병원, 전남대학교병원, 충남대학교병원 이 있습니다.3.
주요 정부고객으로는, 과학기술정보통신부와 국방부가 있습니다.4.
2022년도 JAPAN IT Week 전시회를 통해, 2023년도 일본 의료데이터 구축 시장으로 진입합니다. - 기업 개요 및 핵심역량 : 미래 의료AI시장에 핵심은 단연코 고품질 의료데이터 입니다.
이를 위해 닥터웍스는,1.
닥터웍스 보안 의료 가공 플랫폼을 자체 개발하였고, 2021년도에는 의료 가공 플랫폼 벤처기업 1호로 선정되었습니다.2.
닥터웍스 자문의로 등록되어 있는 26개 분과 1100명의 전문의들과 협업하며, 병원에서 생산되는 모든 의료데이터를 수집, 정제, 가공, 검수, 품질검증,AI 컨설팅을 진행하고 있습니다.3.
이를 바탕으로 설립일로부터 지금까지, 데이터 수집, 정제, 가공, 검수, 품질검증 데이터 수량이 누적 100만 건을 돌파하였습니다.이처럼 고품질 의료데이터를 위해 갖춰야 하는 모든 요소들을 갖춘 기업입니다.닥터웍스의 서비스 오버뷰 그림은 아래와 같습니다. - 활용 사례 : 과학기술정보통신부가 주관하고 한국지능정보사회진흥원(NIA)이 추진하는 2022년 인공지능 학습용 데이터 구축사업에서, 닥터웍스는 아주대의료원과 함께 하는데, 악성종양데이터 구축으로, 폐암예후예측 융합데이터, 악성림프종 예후예측 융합데이터, 암환자 치료 데이터셋 구축을 진행합니다.관련 참고기사는 아래와 같습니다.https://kdata.or.kr/datavoucher/is/selectPortalSearch.do

데이터바우처 사업관리 가공기업 정보
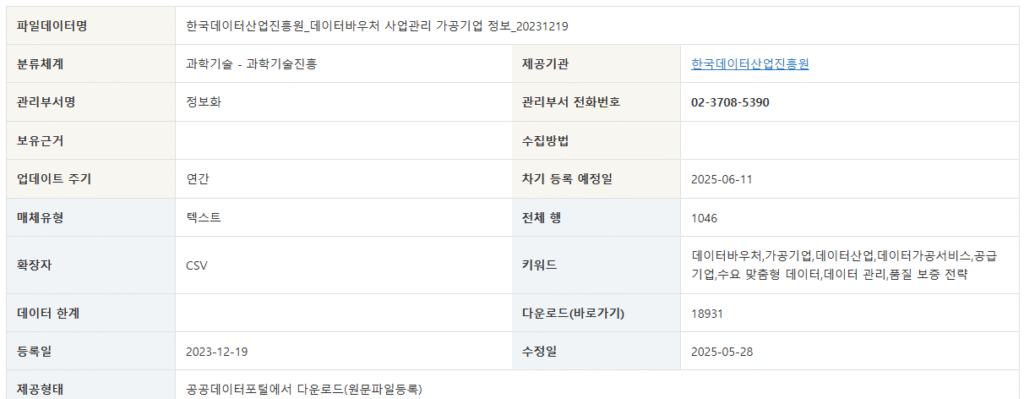
한국데이터산업진흥원 데이터바우처 사업을 통해 지정된 공급기업 중 데이터 가공기업 정보를 제공하고 있습니다. 본 데이터는 데이터바우처 지원사업에 참여하는 기업들의 정보를 포괄적으로 다룹니다. 특히, 수요기업이 필요로 하는 다양한 형태의 데이터 가공 서비스에 대한 정보를 제공함으로써, 데이터 활용의 범위를 넓히고, 기업의 데이터 기반 의사결정을 지원하는 역할을 합니다. 이 데이터가 보유한 컬럼은 다음과 같습니다.
기업한글명(문자형) : 해당 기업의 한글 이름
설립일자(날짜형) : 기업이 설립된 날짜
기본주소(문자형) : 기업의 본사 주소
상세주소(문자형) : 기업의 주소에 대한 추가 정보
주요서비스 상세정보(문자형) : 데이터 가공기업이 제공하는 구체적인 서비스 내용
보유솔루션(문자형) : 기업이 보유한 해결책 및 시스템에 관한 상세 정보
품질확보전략(문자형) : 데이터 품질 확보를 위한 기업의 전략
유지보수전략(문자형) : 데이터 가공 서비스 후속 지원 계획
카테고리구분(문자형) : 제공하는 데이터 가공 서비스의 카테고리 분류
등록일(날짜형) : 데이터가 등록된 날짜
실적(문자형) : 기업의 성과와 실적
기업개요 및 핵심역량(문자형) : 기업의 전반적인 설명과 주요 전문성
활용사례(문자형) : 데이터 및 서비스를 활용한 실제 사례
링크(URL) : 데이터에 대한 추가 정보 및 접근 링크
파일 다운받기
주요서비스 상세정보(요약), 보유솔루션(요약), 품질확보전략(요약), 유지보수(후속지원), 전략(요약), 실적(요약) 등의 일부 데이터 값은 데이터 미집계로 인해 공란이 있습니다.