
대전 유성구2 데이터바우처 사업관리 가공기업
대전 유성구 에는 (주)엠투브, 엠브이엠테크놀로지, 주식회사 제이어스 외 23개의 가공기업이 있습니다.
주식회사 페블러스 소개
- 주식회사 페블러스은 2021-11-19에 설립되었습니다.
- 주소 : 대전 유성구 대학로 99 대전팁스타운 507호
- 주요 서비스 : 데이터 클리닉고객 컨설팅: 데이터 샘플 취득, 도메인 지식 취득, 고객 요구사항 청취고객의 데이터 제출: 보안 및 비공개 관련 법률적 검토 및 합의데이터 이미징: 전문가의 데이터 특성 파악 후 자동화된 컴퓨팅에 의해 데이터 이미지 생성데이터 진단: 고객 요구사항에 따른 데이터 평가지표 전문가의 평가지표 선정, 자동화된 컴퓨팅에 의한 데이터 진단 보고서 생성데이터 개선: 데이터 진단 보고서에 대한 고객 설명, 고객의 선택에 의한 데이터 개선 방법 선정, 자동화된 데이터 개선 프로세스 진행.결과물 납품 및 검수계약에 따른 유지보수입력고객의 샘플 데이터, 고객의 전체 데이터데이터 진단 항목 선정, 데이터 개선 항목 선정결과물데이터 이미지, 데이터 진단 보고서, 개선된 데이터합성 데이터 생성<;가상 데이터 생성>은 상기 <;데이터 클리닉>에 의한 <;데이터 개선>의 특수한 경우일 수 있음.
또는 데이터 클리닉과 관련 없이 독립된 가상 데이터 생성일 수 있음.
고객 컨설팅: 데이터 샘플 취득, 도메인 지식 취득, 고객 요구사항 청취 모델링: 상기에서 도출된 지식을 바탕으로 당사의 모델링 방법론에 따라 시뮬레이터를 모델링 하고 구현함.
시뮬레이션: 상기 구현된 모델을 시뮬레이션하여 가상 데이터를 생성함.
이때 시뮬레이션 제어 인수의 탐색 과정에서 <;데이터 클리닉>의 정밀 타게팅 방법을 적용할 수도 있고, 단순한 구간 인수를 적용할 수 있음.
품질 평가: 상기 모델링과 시뮬레이션에서 생성된 가상 데이터가 고객의 실제 데이터와 유사한지를 <;데이터 클리닉> 방법론에 기반하여 검증하고 고객에게 승인받음.
이 과정과 모델링과 시뮬레이션 과정은 반복될 수 있음.
– 출력물 납품 및 검수
– 계약에 따른 유지보수입력고객의 샘플 데이터, 고객의 전체 데이터데이터 생성 방법: 2세대 배치 생성, 3세대 정밀 타게팅 생성데이터 진단 항목 선정, 개선 항목 선정결과물 합성데이터데이터 진단 보고서데이터 시각화및 - 보유 솔루션 : 데이터 클리닉빅데이터 및 인공지능 개발용 데이터와 같은 비정형 대용량 데이터에 대한 평가 및 품질 향상을 위해서 데이터 이미징, 진단, 개선으로 구성된 데이터 클리닉 파이프라인(데이터 이미징) 데이터의 품질 측정을 위해서는 비정형 대용량 데이터를 객관적으로 관찰하는 과정이 선행되어야 함.
보통 선형적인 PCA나 비선형적인 UMAP을 적용하여 차원축소를 하는 것이 일반적이지만 가시화에 치중하다 보면 전역적인 왜곡이 발생하여 데이터의 전체적인 양상을 파악하기 어려움.
<;페블러스 데이터 클리닉>은 데이터의 내재적 특성을 파악하여 최적의 커스텀 방법을 적용함.
특히, 대용량 다차원 데이터에 대해서 샘플간 거리를 고려한 차원 축소.(데이터 진단) 데이터의 커버리지, 균질도, 밀도 등 데이터의 내재적 평가지표에 따른 데이터 진단 및 품질 평가.
자동화된 품질 리포트 작성.
작업 중심적인 평가도 가능.(데이터 개선) 데이터 진단에 따른 문제점 개선.
(예) 데이터 부족분을 가상데이터를 이용하여 추가함합성 데이터 생성컴퓨터 그래픽스, GAN과 같은 생성 모델 등을 이용하여 인공지능 개발용 학습 및 테스트 데이터를 생성함.수요기업의 적용 도메인에 대한 컨설팅을 통해 모델링과 시뮬레이션 파이프라인을 커스텀 개발하고 이를 통해 가상데이터를 생성함데이터 시각화및 상호작용 기술데이터의 내재적 성질에 대한 분석 및 시각화: 그래프, 차트, 도표, 등 - 품질 확보 전략 : 가.
서비스 품질보증 기준 수립프로젝트 전반의 품질 요구사항을 만족할 수 있는 현실적인 품질보증 활동을 수행하기 위한 단계별 품질 활동에 대한 목표를 수립하고, 품질기준 및 관리 방법론 적용 등 프로젝트 내·외 품질보증 역량을 집중하여 고객이 만족할 수 있는 최고 품질의 서비스를 구축함.가공서비스 품질보증을 위해 품질 평가 도구를 자체 개발하고자 하며, 이를 위해 전담 연구팀을 조직하고 ETRI 및 KAIST 협력 인력을 확보할 예정임나.
서비스 품질향상 방안 마련품질보증 측면의 핵심 실행목표 달성을 위하여 서비스별 특성을 고려한 가공 방법론 및 관련규정 등을 정제하여 적용한 개발활동을 수행하고, 서비스 품질에 대한 객관성 확보를 위해 다양한 품질 보증 활동을 체계적으로 수행하여 서비스의 신뢰성 및 안정성 등 서비스 품질특성을 충족하는 완성도 높은 서비스를 구축할 예정임인공지능데이터 전문기업, 정부출연연구소, 국내우수대학, 학회 등 인공지능 데이터 전문가들과의 정기적 자문 미팅을 통해 품질 평가 및 관리 방법 제고 예정고객으로 부터의 지속적인 서비스 품질 피드백 확보다.
품질관리 조직 운영최적의 서비스 구축을 위해 개발팀과는 별도로 품질보증 조직을 구성하여 품질보증활동을 수행하며, 개발팀은 품질보증활동에 대한 교육 및 실행을 통해 품질목표 등을 사전에 숙지하여 최적의 서비스를 구축가공서비스 품질 향상을 위한 작업 프로세스 관리 체계 마련 - 유지보수 전략 : 1.
서비스의 유지보수는 시스템의 운영 중에 발생하는 시스템 결함을 수정 또는 개선하여 품질을 보증하고, 시스템 안정성을 제고하는 운영지원 업무로 당사는 효율적인 유지/하자보수 지원 체계를 구축하고, 지속적인 관리를 통해 시스템이 안정적으로 운영될 수 있도록 지원 함2.
서비스의 제공 후 효율적인 유지보수 지원을 위하여 수요기업과 공조체계를 유지하고 비상연락망 구축으로 즉각적인 조치할 수 있도록 비상주 지원조직을 구성3.
서비스의 최적화와 안정적 운영을 위해 검사 완료 후 계약기간에 따른 무상하자보수를 실시하며, 서비스의 안정적인 운영보장을 위한 안정화기간 동안 개발에 참여한 인력이 참여.
또한 유상유지보수의 경우에는 무상하자보수기간 만료 전 수요기업과 사전 협의 후 별도 계약에 따라 지원 - 카테고리 구분 : 전처리,품질,코딩,시각화,정보추출또는조합,태깅또는라벨링,분석,기타
- 실적 : 데이터 클리닉<;정밀 타게팅 가상 데이터 생성> 요소기술을 고도화하기 위한 <;팁스> 과제 5억 수주.합성 데이터 생성2022년 데이터바우처 수요기업 4곳과 매칭되어 사업 추진하여 성공적으로 마무리하여 매출 2억 8천만원데이터 적용 사례 다수 : 물류환경에서 물체 인식, 알약 자동 조제를 위한 비젼 검수, 실내 무인 주행, 병리 영상 인식, 엑스레이 이미지 보안 검색, 얼굴 인식을 위한 헤어 데이터셋 등상기 데이터셋을 활용한 <;팁스> 과제 수주 지원메타버스 관련 코스닥 상장사 G사 특례상장 기술 자문가상 데이터 생성 기술에 대한 해외 수상.
이미지 데이터의 색상 변형데이터 시각화및 상호작용 기술2022년 광주과학관 인공지능과 미술 조형물 프로젝트 수주2021년 창업 아이디어 경진대회 수상
– 프로젝터 기반의 공간증강현실 기술을 이용한 물체 분류 작업 - 기업 개요 및 핵심역량 : – ㈜페블러스는 한국전자통신연구원(ETRI)에서 컴퓨터 그래픽스, 인공지능, 로보틱스, 의료영상분야에서 약 20년을 근무한 연구자 두 명이 공동창업자로 설립한 인공지능 데이터 기업이며, 법인 설립 전 2021년 9월 창업아이디어 경진대회에서 가상 데이터 활용에 관한 내용으로 1등을 수상하였음.
– 2016년 ETRI에서 수행하던 연구과제의 필요에 의해 가상학습셋 아이디어를 떠올렸고 2017년에 논문발표를 시작으로 2018년에는 첫 기술이전을 하였고, 2018년 ETRI 사업화 유망기술에도 선정됨.
– 창업자들은 수학 기반 모델링과 공학적 시뮬레이션에 이르는 넓은 학술적 지식과, 제조 산업, 의료 영상, 콘텐츠에 이르는 다양한 산업 프로젝트 경험을 보유하고 있어서 다양한 도메인에 가상 데이터 기술을 적용하는데 능숙함.
– 창업자들은 오랜 연구 활동을 통해 다양한 산학연 네트워크를 확보하고 있어서 개발 제품의 적용에 필요한 전문가 협력 네트워크 구축에 유리함. - 활용 사례 : 데이터 클리닉
– 딥러닝 적용을 위해서는 우수한 신경망의 구축 외에도 우수한 데이터의 확보가 중요하다.
– <;페블러스 데이터 클리닉>은 고객의 데이터에 대한 핵심적인 문제들을 해결하고자 한다.Q1.
우리 데이터는 양적으로 질적으로 충분한가(데이터 이미징) <;데이터를 위한 X
-Ray> 또는 MRI 같은 장치에 비유할 수 있는 이미징 기법을 통해 비정형 대용량 데이터를 객관적으로 관찰할 수 있게 함.Q2.
우리 데이터는 어떤 문제를 갖고 있는가(데이터 진단) 데이터 이미징에 기반하여 <;데이터 진단 리포트>를 발급함.
데이터에 대한 다양한 내재적 평가지표를 볼 수 있고, 개선 방안이 포함됨Q3.
우리 데이터를 어떻게 개선할 수 있을까(데이터 개선) 데이터 진단 리포트에 기반하여 <;데이터 치료> 방법을 제시하고 적용한다.
특히, 데이터의 균질도를 개선하며 부족한 데이터를 가상 데이터로 보충한다.가상 데이터 생성
– 가상 데이터는 두 가지 맥락에서 최근 딥러닝 인공지능에서 주목받고 있음.
Q1.
부족한 실제 데이터를 컴퓨터 그래픽스로 생성한 가상 데이터로 보충할 수 있을까 인공지능 적용도 크게 보면 <;디지털 트윈>적인 관점으로 보는 것이 유리함.
즉, 현실의 작업 프로세스에 대한 디지털 모델링과 시뮬레이션을 구축하고, 이를 통해 시뮬레이션 데이터를 생성하여 딥러닝으로 학습하고 이를 현실의 프로세스에 적용하는 것임.작업 프로세스의 디지털 모델링과 시뮬레이션을 위해서 고객과의 컨설팅을 통해 습득한 도메인 지식에 기반하여 커스텀 모델과 시뮬레이션을 구축함.
이 과정에서 당사의 전문가 역량이 크게 발휘됨.시뮬레이션을 통해 생성한 가상 데이터는 고객이 제공한 실제 데이터의 분포를 따르면서 양적 질적 부족분을 개선할 수 있도록 함.별도의 컨설팅 및 서비스를 통해 가상 데이터가 효과를 보일 수 있는 딥러닝 신경망 구축에 참여할 수 있음.Q2.
익명화 등 개인정보 보호를 위해 실제 데이터와 같은 분포를 갖는 가상 데
주식회사 노타 소개
- 주식회사 노타은 2015-06-01에 설립되었습니다.
- 주소 : 대전 유성구 문지로 193 창조관 2219호
- 주요 서비스 : [상품명 : 인공지능 모델 개발 및 컨설팅, 솔루션 개발 및 서비스] ㅇ 업무 프로세스·1차 수요기업 응대 : Business Development팀에서 1차 수요기업의 Needs 및 제반 환경(데이터 보유 여부, 최종 가공된 데이터에 대한 현장 적용 등)에 대한 확인·솔루션 및 서비스 가능 여부 검토 : 수요기업의 Needs에 대해 솔루션 적용 가능에 대한 내부 검토 및 협의·AI 솔루션 개발 : AI Research Team에서 데이터 수집, AI 모델 개발 및 검증 후 가공된 데이터 제공·데이터 제공 및 추가 대응 : Business Development팀에서 최종 가공 데이터 제공 및 수요기업 현장에서 필요로 하는 추가 사안, 즉, 새로운 데이터 가공, 현장에 맞는 솔루션 개발 등의 요구사항에 따라 대응 및 내부 개발/서비스 제공 ㅇ 수요기업 대응 계획·AI 및 데이터 가공 컨설팅
1) 수요기업의 Needs 및 요구사항 확인 후 AI 모델 및 데이터 가공에 대한 협의 진행
2) AI 개발 및 데이터 가공 관련한 서비스 상품에 대한 표준 매뉴얼 작성 및 배포3) 수요기업 요청 및 필요 시에 AI 모델 및 가공 데이터에 대한 산출물 혹은 서비스에 대한 컨설팅 및 교육 진행 ㅇ 역할 분담·AI 모델 개발 및 데이터 가공에는 학습 데이터 등 원천 데이터 확보가 중요하며 이는 1차적으로는 수요기업에 데이터 제공을 전제로 진행.수요 기업에서 원천 데이터 제공이 힘들 경우, 데이터 확보를 위한 기간 및 외부 제휴 협력사를 통해 데이터 확보 예정(유료 서비스)·확보된 원천 데이터를 기반으로 AI 모델 개발, 데이터 검증, 최종 산출물 제공은 수요기업과 협업을 통해 진행 - 보유 솔루션 : ㅇ 인프라 정보·AI기술 인력 및 사업 개발 인력 확장
1)전체 인원 약 90명의 70%이상이R&D직군이며 경량화된 인공지능 모델 개발,인공지능 모델 경량화 플랫폼 개발 전문 인력으로구성되어 있어 인공지능 기술 개발을 위한 기술 집약적인 사업 형태를 하고 있음
2)인공지능 개발자 이외에 온디바이스 인공지능 솔루션 및 서비스 상용화를 위한 모바일,임베디드HW,백엔드SW등 개발자의 추가 채용이예정되어 있으며사업 확대 및 성장에 따른 고용이 지속적으로 확대될 것으로 보임:연 평균20%이상 고용 창출이 기대됨ㅇ 향후 미래 기술 확보 계획·협력 기업과의 공동 상품 개발 및 자체 연구 과제 등을 통한 지적 재산권 확보
1)현재 파트너십을 맺고 있는Intel, Arm, Nvidia등의 글로벌 칩 벤더사 및AWS, Google Cloud Platform등의글로벌 클라우드 컴퓨팅사와의 지속적인 기술 파트너십을 통한 기술 확보 및 공동 솔루션 상품 개발 진행
2)공공 협력 과제를 통해 지적 재산권 확보 외에도 다양한 산업에 활용될 수 있는 기술 및 솔루션 개발3)유명 저널 및 컨퍼런스 등에 논문 투고를 통해 지적 재산권 확보 및㈜노타 회사 브랜드 인지도 향상4)특허,실시권,상표권 등 지적 재산권 확보를 통해 회사 기술 경쟁력 확보 (연 40건 이상 예정)5)인공지능 기반 자연어 처리,음성 인식 모델 솔루션 및 경량화 기술 추가 확보·대학교 및 기업과 공동 연구 협력 과제 발굴
1)대학 연구소,기업 등과의 연구 협력을 통해 최신AI기술에 대한 리서치 진행 및 이를 통해 다양한 산업에 활용될 수 있는 솔루션 개발
2)공동 연구 개발을 통해 획득한 기술 지식 등을 내재화 및 상용 솔루션 개발에 활용 - 품질 확보 전략 : ㅇ 품질 개선 및 확보 전략·에러 수정,기능 자체의 문제점으로 인한 수정/보완,목적물의 수정 가능·운용 중 장애 발생 시 수요기업이 재설치를 요구할 경우 무상 설치하여 업무 차질 최소화·제공한 모델의 정상 운영을 위한 기술 지원·제공한 모델의 운영 중 발생한 결함 및 장애 복구 기술 지원·전속 개발 지원 인력 배정 및 실시간 대응을 통한 고품질, 고성능 인공지능 서비스 지원
- 유지보수 전략 : ㅇ 하자보수·검수 완료 후 1년 이내에 발생하는 AI 모델 결함에 대한 유지보수·기본점검 및 설치 전 환경점검, 장애발생 시 온라인 지원/현장 지원 ㅇ 환경 적응·수요기업이 운영하고 있는 운영 체계, 응용 프로그램 등과 산출물인 AI SW 연동과 관련한 이슈 사항에 대해 양사가 협의한 방식으로 대응 및 기술 지원
- 카테고리 구분 : 전처리,코딩,태깅또는라벨링,분석,기타
- 실적 : ·UAE KUSTAR 딥러닝기반생체신호기반사용자건강상태모니터링AI Model 개발및제공·펫츠랩딥러닝기반실시간최적비문인식모델개발및제공·㈜데이콘데이터분석경진대회수상자결과물기술적평가컨설팅프로젝트수행·㈜펀다딥러닝기반자영업자대출심사모델고도화를위한AI Model 개발및제공·㈜더웨이브톡딥러닝기반On
-device박테리아수카운팅AI Model 개발및제공·㈜비스텍딥러닝기반On
-device 부품결함/OCR 인식솔루션개발및제공·㈜ATAM 딥러닝기반미디어콘텐츠내PPL 제품인식모델개발및제공·㈜비트센싱딥러닝기반On
-device 차량검출모델개발및제공·㈜핌아시아유통기한임박상품자산가치평가모델및유사상품추천모델개발·에스피테크놀러지(이마트) 재고 현황 파악 솔루션 및 경량화·애니랙티브 DMS 및 제스처 인식 모델 경량화·LG CNS CCTV 기반 물체 검출 및 추적 솔루션 경량화·몽딱뚝딱 AI Model SW 및 컨설팅 서비스·이편한자동화기술 중장비 기기에서의 물체검출 솔루션 경량화·한미헬스케어 물체 및 인물 인식 / 트래킹 솔루션 (Re
-ID)·삼성전자리서치 물체 검출 솔루션 경량화·(주)인바디 얼굴인식 솔루션 개발 및 커스터마이징·삼성에스디에스 Face Recognition Software OPERATION·평택시 스마트교차로 인공지능 신호제어솔루션 제공·(주)피타소프트 DMS 솔루션 제공·(주)라이브시큐 스마트CCTV 인공지능 솔루션 제공·현대에이치티주식회사 FR솔루션 제공·현대자동차 DMS 솔루션 PoC·대전광역시 스마트교차로 솔루션 제공·제주도 자율주행 모빌리티 시범사업 스마트교차로 솔루션 제공외 다수 - 기업 개요 및 핵심역량 : ㅇ 기업 개요· 인공지능을 활용해 편리한 세상을 만들어보자는 철학을 가진 주식회사 노타는 KAIST 학생 창업으로 시작했습니다.
저희 노타는 인공지능 원천기술인 딥러닝 모델 경량화 기술을 기반으로 인공지능 기술을 활용하여 생활의 불편함을 해소하는데에 적용될 다양한 인공지능 모델을 개발합니다.
· 인텔, 엔비디아, 삼성, LG, 현대차 그룹 등 다양한 사업 분야에 걸쳐 다수의 글로벌 기업들과 협업 및 파트너십을 맺고 사업, 기술 모두 빠르게 진보하고 있습니다.
글로벌 사업 진출 또한, 북미 지사 (Nota AI Inc.) 설립을 시작으로 순조로이 진행 중이고 2020년 4월에는 독일 베를린에 자회사 (Nota AI GmbH) 를 설립하여 글로벌 통신사와 실제 매출 프로젝트를 진행 중에 있습니다.
ㅇ 핵심 역량· 대부분의 딥러닝 모델은 복잡한 연산을 처리하기 위해 클라우드, 서버의 고성능 컴퓨팅 파워를 거치며, 이는 운영 비용 및 속도 부하, 더 나아가 개인정보를 다루는 환경에서는 프라이버시 침해 이슈까지 발생시킵니다.· 저희 노타는 자체 개발한 딥러닝 모델 경량화 원천 기술을 활용해 딥러닝 모델 사이즈를 줄이면서도 성능 저하를 최소화해 SOTA 모델을 스마트폰, 소형 IoT기기, 싱글보드 컴퓨터 등의 엣지 디바이스에서도 딥러닝 모델을 독립 구동할 수 있게끔 하고 서버, 클라우드 환경에서의 모델 구동으로 드는 운영 비용과 하드웨어 구매 비용을 획기적으로 줄여줄 수 있는 강점을 가진 기술을 가지고 있습니다. - 활용 사례 : ㅇ인공지능 모델 개발 및 컨설팅,솔루션 개발 및 서비스 사례·국내외로 실제 인공지능 솔루션 제작 및 납품, 상용화 레퍼런스 다수 보유 중
– 고객/파트너사 : Nvidia, Arm, LG전자, 삼성물산,NCSoft,삼성에스디에스, Deutsche telekom,대전광역시, 평택시, KAIST, GIST 외 다수ㅇ 본 사업 관련 사례·2020년, 2021, 2022년 데이터바우처 지원사업 공급 기업으로 참여
– 2022년 6개 기업 진행 → 아르고, 에이아이테크놀로지, 다인스, 비컨, 이편한자동화기술, 라이브시큐
주식회사 비전21테크 소개
- 주식회사 비전21테크은 2020-02-11에 설립되었습니다.
- 주소 : 대전 유성구 문지로 272-16 AI인공지능센터, 214호
- 주요 서비스 : 데이터 정제 : 데이터 정제를 위한 작업 프로세스
– 불필요한 데이터, 무의미한 데이터 정의 및 제거 방법
– 데이터 정제를 위한 SW 구조 및 GUI 형태
– 변수의 유형 관리 방법(연속형, 정수형, 범주형 등) <;데이터 정제 방법>항목상세 내용데이터획득·정제획득 목적에 맞는 영상만 선별공통참조기준 촬영 항목에서 어긋나는 사진 배제추적 대상 객체가 존재하는 경우만 선정화질이 불량하거나(흔들림, 초점 불일치 등).
렌즈 이물질 등으로 잘 보이지 않는 영상의 경우 배제데이터 추출 및메타 생성주어진 영상에서 초당 1프레임 수준 이미지 추출 및 메타 생성환경요소획득 영상(동적/정적) 이미지 시나리오에 맞는 성별/연령별 인지 확인해상도 기준고/중/저의 해상도의 경우 이미지 비율을 유지, 촬영하는 해상도 및 동영상 재생 조건에 맞춰 설정롱(1920px * 1080px) 파일로 구축15fps 이상을 원칙으로 획득저장 형태MP4 포맷 기본 외(기본적으로 H264, H265, MPEG4 코덱 등 일반적인 코덱) 추출획득시 고려사항획득 시고려사항설명비고획득 가능성획득이 불가능하거나 통제 불가능한 주기를 가지고 있다면 원시데이터의 정책에 의존하게 되므로 바람직하지 않음획득이 용이하더라도 서비스 활용 측면에서 데이터를 활용하기 위해 가공 처리에 많은 비용이 드는 데이터는 선정하기 어려움직접 산출이 어려운 경우 획득 난이도 측면에서 트래픽량과 저장 처리 장치의 용량 등이 고려 대상, 획득 대상의 대안 필요가능성 검토데이터 정확성가공 데이터에 대해서 세부 항목이 정확히 존재하는지의 검토 필요획득 목적에 맞는 데이터를 획득하기 위해서 사전, 사후 처리 방안 필요사업계획서 당시 정의한 구축요건에 맞춰 데이터를 획득, 정제함정확성 검토보안사항개인정보 및저작권데이터 저작권에 대한 라이센스 확보와 자체 데이터 제작 권장가공된 데이터의 라이선스에 대한 확약 및 협약서획득 데이터에 개인정보 획득 등 보안사항이 없는지 검토공개 데이터를 위한 필수사항데이터 균형개체 다양성성별 및 - 보유 솔루션 : Annotation 오픈 플랫폼(웹버전)
-서버에 저작도구 구축, 온라인 접속을 통해 작업 가능
-작업물 업로드, 작업물 관리, 작업물 배분, 작업자 관리, 작업비용 정산 등 다양한 기능 겸비라벨링 저작도구(labeling)
– labeling 저작도구는 작업자의 작업도구(PC, 노트북 등)에 직접 설치 가능하도록 실행파일로 되어 있으며, 인터넷 환경이 갖추어져 있지 않는 경우에도 데이터 가공 작업이 가능함
– 최종 단계인 데이터 최종 검수용으로 적합
– 본 labeling 저작도구는 오픈소스를 활용하여 작업에 적합하게 프로그램을 수정한 상태임
– 본 labeling 저작도구는 Bounding Box 라벨링이 가능함라벨미 저작도구(labelme)
– labelme 저작도구는 작업자의 작업도구(PC, 노트북 등)에 직접 설치 가능하도록 실행파일로 되어 있으며, 인터넷 환경이 갖추어져 있지 않는 경우에도 데이터 가공 작업이 가능함
– 최종 단계인 데이터 최종 검수용으로 적합
– 본 labelme 저작도구는 오픈소스를 활용하여 작업에 적합하게 프로그램을 수정한 상태임
– 본 labelme 저작도구는 폴리곤 라벨링이 가능함 K Pose Body, Face
– K Pose 저작도구는 작업자의 작업도구(PC, 노트북 등)에 직접 설치 가능하도록 실행파일로 되어 있으며, 인터넷 환경이 갖추어져 있지 않는 경우에도 데이터 가공 작업이 가능함.
-3D 어노테이션 라벨링 가능 보유장비 (단위:천원)시설 및 장비명규격단가수량영상학습서버ASUS ESC4000A
-E10 18,270 1GPU 서버NTEL코어i7
-10세대 10700KNVIDIA RTX 30807,0002개발 및 가공용 PC 및 모니터ASUS PRIME Z4 - 품질 확보 전략 : 품질관리 조직도
– 품질관리 총괄책임자 : 가공 데이터의 품질관리 총괄
– 품질관리 실무책임자 : 가공 데이터의 품질 관리 실무 총괄
– 품질관리 실무협의회 : 가공 데이터의 품질관리 주요 계획, 품질 현안 등의 협의 / 실무협의회는 데이터를 수집과 검수, 가공, 비식별화를 하는 기관으로 구성
– 구축 프로세스 품질관리 담당 학습 데이터의 준비성, 완전성, 유용성을 확보하기 위한 품질 관리 / 학습 데이터의 수집을 수행하는 기관이 담당
– 구축 데이터 품질관리 담당 : 학습 데이터 자체의 적합성, 정확성을 확보하기 위한 품질 관리 / 학습 데이터의 수집, 가공, 비식별화 긴관이 담당
– 학습 모델 품질관리 담당 : 학습 보델의 선정과 유효성 검증을 확보하기 위한 품질 관리 / 학습 데이터를 개발하는 기관이 담당 - 유지보수 전략 : 가공 서비스 제공 계획 및 제공 목표, 관리 계획
– 수요기업의 데이터 수집환경(수집도구, 클래스 등) 체크, 필요시 데이터 구축 계획 및 검증 프로세스에 대한 교육 실시
– 수요기업의 보유하고 있는 원천데이터의 상태를 확인하여 데이터 상태확인정보 제공
– 상태확인정보를 활용하여 수요기업에서 원천데이터로부터 사용할 수 없는 데이터를 제거할 수 있도록 지원서비스를 하거나, 또는 원천데이터로부터 사용할 수 없는 데이터를 직접 제거하는 서비스를 제공하여, 유의미한 데이터를 확보할 수 있도록 지원
– 유의미한 데이터에 대해서 가공 서비스 제공
-수요기업이 추가 데이터를 수집 및 가공해야 하는 경우 수집 전 데이터 구축 계획을 함께 작성할 수 있는 서비스 제공 수요증가에 따른 가공서비스 제공방안, 유지보수, 고객관리 및 고객응대계획
– 수요기업별로 프로젝트 생성
– 프로젝트별 담당 PM 및 담당 팀 생성, 모든 프로젝트는 팀별로 관리되도록 함
– 프로젝트를 관장하는 메인 관리자를 복수명으로 구성, 모든 프로젝트를 크로스로 관리하도록 함
– 가공 서비스가 이루어진 가공 데이터에 대해서는 서로 다른 팀이 검수하도록 함
– 가공 서비스 완료 후 수요기업으로부터 가공 데이터에 대한 보수요청이 있을 경우 가공 서비스 당시 팀을 재구축하여 데이터 보수가 즉각적으로 이루어지도록 지원함
– 데이터 가공 수요기업에 대해서는 정기적으로 수요기업에 필요한 데이터, 학습엔진, 데이터 활용서비스와 관련된 정보를 제공하고, 필요시 외부 전문가(또는 전문가 그룹)를 통해 컨설팅이 이루어지도록 지원함
– 수요기업이 보유하고 있는 데이터에 대해서 추가 수집 서비스 안내를 하고, 필요시 추가 수집 및 가공하여 데이터 제공 - 카테고리 구분 : 태깅또는라벨링
- 실적 :
- 기업 개요 및 핵심역량 : ○ 주식회사 비전21테크는 설립 이후 유아들의 자연교감 상태를 확인할 수 있는 데이터 수집도구인 스마트플랜테리어를 “스마트시티 혁신성장동력 프로젝트 스마트 어린이집 모델 개발 및 실증 사업” 중 2020년도에 시흥시청어린이집에 구축하여 어린이집 유아 데이터 수집을 지원하고 있으며, 본 사업은 2022년도에 종료됨.
본 사업에서 유아 데이터 수집 및 가공을 진행하고 있음.
데이터 가공은 바운드박스 라벨링, 동영상 라벨링, 세그멘테이션 라벨링 등 하나의 데이터를 대상으로 다양한 방식으로 진행되고 있음.
○ 2020년 AI 학습용 데이터 구축사업(NIA)의 참여기관으로, “시니어모니터링 데이터”를 수집하고 가공하는 작업을 수행함.
본 데이터의 가공은 포인트 라벨링 방식으로 진행됨.
또한 “시니어 얼굴표정 변화 및 뇌파 기반 이상행동 인지모델” 개발함.
○ 2021년 AI 학습용 데이터 구축사업(NIA)의 일부 용역을 맡아서 세그멘이터 라벨링 방식으로 데이터를 가공하였음.○ 2022년 AI 학습용데이터 구축사업(NIA)의 참여기관으로, “2
-044.
한국인 3D 스캐닝 데이터”, “2
-086.
멀티영상 동일 상황 및 객체 식별 데이터”, “2
-095.
상수원
-취수원 및 지하수 수질 데이터”를 가공하는 작업을 수행하고 있으며 본 사업은 2022년도에 종료됨.
데이터 가공은 3D 키 포인트 라벨링, 이미지/동영상 라벨링, 시계열 데이터 라벨링 방식으로 진행되고 있음. - 활용 사례 : 크라우드 소싱 등 외부인력 활용 전략
-보유하고 있는 네트워크를 적극 활용하여 인력 수급이 원활하게 진행되도록 함<;보유하고 있는 지역연계 네트워크 현황>구분단체명내용규모(명)다문화여성관련다:맘다국적 엄마들 모임100다:문화네트워크예술을 통한 다양한 문화의 교류80경력단절 및 보유여성관련따.또.가대전 지역의 기술보유여성 중심의 커뮤니티390글로벌여성ICT네트워크SW, ICT 경력단절여성 지원 단체150지역품앗이 한밭레츠지역화폐를 활용한 지역공동체300지역주민연계대화동 행정복지센터, 대화동 주민자치회지역주민 네트워크 연계 및 활성화 여성기업연계여성혁신연구회, 한국여성기업가정신연구회국내/국제 여성기업 네트워크 청년연계사회적협동조합 M042대전 지역 청년 네트워크를 형성하고 있으며 기술 교육 격차 해소를 위한 교육부 설립인가를 받은 사회적협동조합
-데이터 저작 플랫폼을 사용하여 언제 어디서든 누구나 작업을 진행할 수 있는 방식의 언택트 기반의 업무를 수행하고자 함
– 크라우드 소싱 방식의 데이터 구축 경험을 기반으로 축적된 노하우를 활용하여 데이터 구축 수행 계획
– 데이터 저작 플랫폼을 통해 불특정 다수의 접근이 가능하며, 데이터 구축 요건에 부합한다면 누구나 작업이 가능
– 참여가 간편하고 진행 가능한 작업의 종류가 다양하여 다수의 작업자 수집이 용이하고, 작업자들이 작업을 수행하기에 적합
– 작업 강도의 차등과 금액적 차등을 두어 프로젝트를 생성하여, 다양한 성향을 가진 불특정 다수가 모두 흥미를 갖고 작업에 참여할 수 있도록 독려 계획
– 업무 단계 및 난이도에 따라 환경(온라인 또는 오프라인)을 구분하여 작업수행웹 플랫폼 환경재택근무 환경오프라인 환경 개방형 크라우드 방식으로 누구나 프로젝트에 참여가능가공 영역에서 활용 단기 계약직을 채용하여 일정기간 지정된 프로젝트에 참여오프라인 교육 후 재택근무 환경에서 웹 플랫폼을 통해 업무 진행 보안 및 업무 복잡성 등을 고려하여 지정된 공간에서 업무 참여일용직 또는 단기 계약직을
플랜아이 소개
- 플랜아이은 2004-11-29에 설립되었습니다.
- 주소 : 대전 유성구 문지로 282-10 (주)플랜아이
- 주요 서비스 : 수요기업이 요청하는 웹 기반의 사용자 네비게이션 정보를 수집하는 것은 사용자가 활용하는 웹서버와 연계되는 수집 분석 시스템(AIVORY & VODA)을 활용함다수의 고객 사용자는 웹 사이트에 실시간으로 접속하여 이커머스 등 웹 서비스를 활용하며, 이를 위해 웹 사이트에 진입하고 최종 퇴장할때 까지 마우스를 중심으로 하는 많은 네비게이션 활동을 남김특정 사이트 사용자가 웹 서비스를 활용하면서 남기는 마우스 괴적, 마우스 클릭 콘텐트, 페이지 전환, 페이지 체류 시간 양 모든 로그 데이터는 웹 페이지의 효율성뿐만 아니라 사용자의 취향 등을 판단할 수 있는 중요 자료임이러한 데이터는 아마존 클라우드로 서비스하고 있는 제안사의 서비스 시스템에 빅데이터로 실시간 수집되고, 데이터 내용과 서비스 목적에 따라 정제 분석 과정을 거쳐 시각화 가능함제안사는 이러한 정보를 수집하고 분석하여 수요기업에게 유효한 사업적 통찰력을 제공할 수 있음분석되어 시각화되는 정보는 분석 대상 사이트의 특성뿐만 아니라 활용성 향상을 위한 방안, 사용자 네비게이션 특징 등을 포함함
- 보유 솔루션 : 인공지능을 활용한 사용자 맞춤형 상품추천 시스템 및 방법인공지능을 활용한 개인화 추천영역 선정 시스템 및 방법AIVORY
-Q(서비스)인공지능 기반의 예측을 활용하는 A/B테스팅 시스템 및 방법AI VORY & VODA 시스템(서비스)자연어 질의를 통한 문서 검색 및 응답 제공 시스템 및 방법머신러닝을 활용한 다중 사용자의 행태 데이터 시각화 시스템 및 방법자연어 질의에 대하여 시계열 정보를 제공하는 시스템 및 방법검색 결과별 가변적 사용자 인터페이스 제공 시스템 및 방법AIVORY v2.0AIVORY 챗봇 패키지AIVORY 지식그래프 패키지자연어 질의에 대한 전문가 답변을 제공하는 시스템자연어 질의에 대한 전문가 답변을 제공하는 방법 및 시스템독투에디터아이뷰어컨텐츠 네비게이터우르디지털 정보 제공 시스템 및 방법 - 품질 확보 전략 : 가.
객관적 품질 확보와 인증 전략외부 공인기관 및 특허와 지재권 등을 출원 등록하여 고객 데이터 수집 프로세스 및 분석 시각화 서비스의 품질을 객관적으로 확보AIVORY
-Q 상품추천 서비스에 관련해 프로그램 등록 및 특허 2건 출원데이터 가공에 필요한 VODA Studio 프로그램 등록과학기술정보통신부 데이터 사업자 신고 - 유지보수 전략 : 데이터 수요 기업과의 실무협의체를 구성하여 전체적인 프로세스에서 상호 협력 및 투명하고 빠른 일정 공유를 통해 계획된 일정에 맞게 프로젝트를 원만히 수행데이터 생산부터 학습, 활용까지 모든 일련의 과정을 논의하고 협의하는 것을 협의체의 목적으로 하며, 데이터 수집에서 필요한 데이터 요건을 정의하고 데이터 소재 파악 및 확보데이터 수집 부분이 제대로 수집 되는지 확인하고 데이터 수집 수, 품질 등의 이슈에 대해서 협력 및 함께 대응데이터 가공에서 오류 사항 점검 및 조치와 데이터 구조 및 특성 변경을 역할로 함데이터 가공 부분에서 툴/소프트웨어 사용에 대한 안정성과 편의성을 논의하여 개선점을 도출하고 이를 다시 작업자에게 피드백하여 작업 생산 속도 향상에 기여모델링 부분에서 인공지능 학습 데이터를 활용한 AI 학습 모델을 통해 학습이 정상적으로 이루어지고 있는지 확인하고, 발생 문제의 원인을 확인하여 문제를 해결활용 부분에서 수집된 인공지능 학습 데이터와 개발된 모델을 활용한 서비스 방안을 포함한 다양한 활용 방안 및 기술적 지원 방안에 대해 함께 논의
- 카테고리 구분 : 정보추출또는조합,분석
- 실적 : 연구수행 실적(과제명/개발기간/프로그램명/총사업비)1.옴니채널 고객 행동 데이터 기반 460도 고객 경험 뷰 인텔리전스 기술 개발/2022.04.01.~2023.03.31./지역특화산업육성(중기부/중고기업기술정보진흥원) / 267백만원2.웹 로그와 사용성 분석을 활용한 개인화 UX 큐레이션 인공지능 기술 개발과 사업화 /2021.09.16.~2022.09.15.
/연구개발특구육성(과기부/특구진흥재단) /250백만원3.초분광이미징과딥러닝을활용한불법복제품 판독시스템 구축 /2020.08.01.~2021.12.31 /AI융합 불법복제품 판독시스템(정보통신산업진흥원) / 600만원4.cctv 영상 AI 데이터 /2020.08.01.~2021.02.28 /인공지능학습용데이터구축(한국지능정보사회진흥원) / 1,425 백만원5.인공지능기반 UX분석 및 지식그래프 추천이가능한 웹서비스 최적화 솔루션 개발 /2020.09.01.~2021.08.31 /특구기술이전사업화사업(과기부/특구진흥재단) / 325백만원6.개념 그래프 기반 인공지능 콘텐츠 추천 챗봇 기술 개발 /2019.05.15.~ 2020.05.14.
/특구기술이전사업화사업(과기부/특구진흥재단) / 267백만원7.사용자 콘텐츠 소비 패턴 분석 기술 기반의 적응형 맞춤정보 제공 기술 /2016.09.01.~2018.08.31.
/기술혁신개발사업(중기부/중소기업청) / 770백만원유사사업 실적(사업명 / 계약금약 / 발주처 / 비고)1.대전지역 공동활용 연구장비 플랫폼 구축 용역 /174,454,545원/재단법인 대전테크노파크 /대전 23개 기관의 연구장비 데이터 수집 및 가공2.국민영양통계 공공데이터 및 보건산업 제약정보 통합 구축 사업 /290,454,545원 /한국보건산업진흥원 /국민영양통계 가공 및 분석 사업3.식생활교육 정보플랫폼 고도화 및 콘텐츠 확대 용역 /149,090,909원/농림수산식품교육문화정보원 /식생활교육 콘텐츠 수집 및 플랫폼 적용4.국민영양통계 공공데이터 및 보건산업 고객맞춤형 정보 개방 구축사 - 기업 개요 및 핵심역량 : 2022상품추천 솔루션 AIVORY
-Q 런칭인공지능 상품추천 분야 특허 2건 출원애터미아자 상품추천 AIVORY
-Q 납품2021SaaS형 웹 최적화 솔루션 AIVORY VODA 1.0 런칭GS인증 획득인공지능 분야 특허 2건 출원 및 등록대덕연구개발특구 기술사업화 후속고도화 과제 선정2020AI기반 지식 서비스 전문 기업 선포 원년AI바우처 지원사업 공급기업 선정AI 인큐베이팅 공간 ‘SPASE S’ 운영사업자 선정인공지능 분야 특허 2건, 프로그램 2건 등록너드팩토리 AI 전문기업 인덱스 등록2019대화형 콘텐츠 추천 인공지능 AIVORY 2.0 런칭’인공지능 분야 최초’ GS인증 획득‘인공지능분야 최초’ 조달청 벤처나라 등록인공지능 서비스 전문 브랜드 ‘너드팩토리’ 런칭인공지능 분야 특허 3건 출원 및 등록대덕연구개발특구 기술사업화 과제 선정2018디지털 정보 제공 시스템 및 방법 특허 등록PCT 출원 (KR 2018 003068)스마트 근태관리 서비스 i
-Checker 런칭인공지능 추천 검색 솔루션 AIVORY 런칭기초과학연구원 AIVORY 납품한국원자력연구원 납품2018년 산업 포장 수훈2017청년 친화 강소기업 선정(고용노동부)경제과학대상(벤처기업부문) 대전광역시중소벤처기업부 표창인공지능 솔루션(컨텐츠 네비게이터, 우르(Ur) 프로그램 창작등록Doc2Editor, i
-Viewer 프로그램 창작 등록특허 3건 출원, 등록 3건인공지능 및 빅데이터 전문 연구조직 미래연구소 설립신사옥 준공 및 직원 복지 재단 설립2016중소기업청 표창, 강소기업 인증, 병역특례업체 지정기업모니터링 및 성과추척관리 시스템 프로그램 창작 등록다이어그램(diagram) 프로그램 창작 등록인재육성형 중소기업 지정(중소기업청콘텐츠 소비 패턴 분석 특허 기술 출원중소벤처기업부 산업핵심기술개발 사업 선정2015인공지능 연구기획 및 연구시작업무 소통 및 협력서비스 제공 방법 및 장치 특허 출원대화형 정보제공 서비스 및 장치(ETRI 특허 인수)클라우드 기반 스타트업 지원 플랫폼 ‘Y - 활용 사례 : AIVORY
– AI지능형 상품 검색
– 카테고리 내 검색
– 키워드 자동 완성
– 인기/연관 검색
– 세그먼트 추천
– 장바구니 연관 상품
– 오탈자 보정VODA
– 사이트 이용 형태 분석
– 네비게이션 분석
– 브라우저 OS
– 유저수 통계(UV)
– 페이지뷰 수 통계(PV)
– 체류 시간 통계AIVORY
-Q
– 행동데이터 기반 고객 식별
– 상품 및 캠페인 관리
– 개인화 추천 상품
– 개인화 상품 배치 추천
주식회사에이리스 소개
- 주식회사에이리스은 2018-08-28에 설립되었습니다.
- 주소 : 대전 유성구 반석로12번안길 7 3층
- 주요 서비스 : [데이터 수집 및 정제]에이리스는 데이터 수집(촬영),정제,라벨링,검수 등 데이터 가공을 위한종합적인 수행체계가 구축되어 있습니다.다양한 영상데이터를 구축한 경험과 노하우를 토대로,수요기업에게 효율적인 데이터 가공 방안을 제시합니다.가이드라인을 교육자료로 활용하여 영상정제 경험 미보유자도,효과적으로 정제 업무를 수행할 수 있도록 합니다.라벨링불량 사례 소개 등 정제 품질 저하 및 재작업 최소화하며 고품질 정제 영상확보를 통해 학습데이터셋 생성 용이한 검수 툴 개발 및 활용합니다.라벨링된 영상 및 정보 관련Metadata로 인공지능 학습을 위한Dataset을 구축합니다.[데이터 가공작업]가공작업(레이블링)된 학습 데이터로 사용시 식별 가능하며 라벨링 품질에 따른AI추론 식별률이 변동됩니다.가공영상선정 및 데이터 수집,정제 인력 배치 및 데이터 배포,데이터 정제 실시,정제된 데이터 검수 단계의 작업이 필요합니다.개발 도구를 이용하여 정제 및 검수가 완료된 데이터는 파일은txt파일로 파일,이미지,마스킹 영역에 대한 정보를 포함하여 네이밍 규칙에 맞춰 각각PNG, JSON으로 포맷되어 저장됩니다.[데이터 검수]에이리스는정제 솔루션을 통해 정제된 이미지를 검수하기 위하여 자가 검증단계를 거치고 자가 검증이 완료된 데이터를 대상으로 원본 이미지와 대조하여 데이터를 최종 검증합니다.작업자의 어노테이션을 자가 검증 하는 단계로 아래의 데이터 스탠다드를 기반으로 작업자의 육안 검증을 완료합니다.자가 검증이 완료된 데이터를 대상으로 품목명과Annotation데이터를 (주)에이리스 자체 검수 프로그램 으로 원본 이미지와 대조하여 데이터를 최종 검증하여 수정합니다.
- 보유 솔루션 : [주요 기술 및 제품]효율적인 데이터 가공을 위해 에이리스는 데이터관리솔루션과 데이터가공솔루션을 보유하고 있습니다.또한, CT기기를 이용하여X
-Ray영상을 촬영하고,이를 다량의 영상데이터로 확장할 수 있는 기술을 한국전자통신연구원으로부터 이전받아 사용하고 있습니다.더불어X
-ray영상의 원천데이터 수집을 위한converter를 개발하였고,일반영상 촬영을 위한 초고속카메라 컨베이어 벨트 장비도 구축하였습니다.<;주요 제품>프로그램특징AIDM가공된 데이터의 관리 및AI학습 관리DoRRain Gray2D/3D영상DRR생성기술PRIM영상데이터 라벨링 프로그램XI
-ConverterX
-ray영상 원천데이터 수집 기기 - 품질 확보 전략 : [품질확보전략] 구축되는 데이터의 품질을 보증하기 위하여 제공되는 데이터가 유효하며 신뢰할 수 있는지, 데이터가 필요한 시점에서 손쉽게 활용 될 수 있는지에 따른 유효성과 활용성으로 구분하고 세부적 기준을 정의하여 품질보증 활동을 진행합니다.
인공지능 학습을 위한 영상Data와 정보Data정제 수요기업의 Data 현황을 분석하여, 정제 방안 및 소요인력 제시하며 정제된 영상 및 정보 Data로 인공지능 학습을 위한 Dataset을 구축학습용 X
-RAY 및 일반영상데이터 제작합니다.
[품질보증활동] 품질보증 활동의 주체 별 역할 및 품질 진단 절차를 통하여 성과물에 대한 품질적합성을 검증하고 부적합 산출물을 관리하여 수요기업에 제시한 품질목표를 달성합니다.
활동주체활동내용1차 가공 작업자
– DB구축 입력한 산출물에 대해 서로 교환하여 제품 품질의 결함 발견 제거, 시정조치 내역 기록
– 작업공정자 내부에 별도의 품질담당자를 선정하여 자체적으로 질을 평가2차 품질보증팀
– 1차적으로 작업 공정자 자체의 내부 품질평가에서 합격된 산출물 대상
– 품질보증팀에서 별도의 품질평가 체크리스트를 작성하여 해당 품질을 측정, 평가수요기업
– 1,2차의 품질평가에서 합격된 산출물 대상
– 주관기관의 품질 요구사항을 기준으로 해당 품질을 측정,평가
– 필요에 따라 체크리스트 작성 - 유지보수 전략 : [유지보수 방안]가공하여 공급한 데이터에문제가 발생하면 수요기업은 에이리스의 유지보수팀에 신고 접수합니다.유지보수팀은 유선 또는 방문을 통하여1차 조사를 실시하고 문제 발생 세부 원인을 면밀히 파악하여 문제를 해결[유지보수 절차]문제발생▶접수▶문제해결가공서비스 이슈사항데이터 품질문제 발생요구사항 접수상태확인조치여부판단일지기록Help deak 품질결함 발생시 에이리스 유지(하자)보수팀 이관추진조직주요역할조치완료가공데이터 유지보수팀
-조치계획 수립
-데이터보완 및 변경
-검수/테스트데이터 재전송수요기업 결과 통보조치내용 공지유지보수 이력관리본사유지보수팀
-조치계획 수립
-문제해결검수/테스트[협력체계 구축] 1회성으로 데이터를 구축하여 제공하는 것이 아닌 수요기업의 데이터 변화 등 데이터의 증축 또는 수정이 필요한 경우 적극적으로 협력하여 수요기업의 성공을 위해 함께 노력에이리스→협력←수요기업데이터 품질개선데이터 추가 가공기타지원데이터 증축추가 사업 공동 추진데이터 품질개선데이터 추가 가공기타지원 - 카테고리 구분 : 전처리,품질,코딩,시각화,정보추출또는조합,태깅또는라벨링,분석
- 실적 : [유사사업 참여내용과 성과 및 실적]
1)폐플라스틱 이미지 데이터 구축사업명인공지능 학습용 데이터 구축사업기간2021.06 ~ 2021.
12거래처 및 금액한국지능정보사회진흥원, 19억(5개기업 컨소시엄)사업내용폐플라스틱 이미지 데이터 구축사업성과4대 플라스틱(PET, PP, PS, PE)에 대한 이미지 데이터 약60만장 구축역할데이터 수집(촬영)및 정제
2) AI기반 컨테이너X
-Ray영상판독사업명스핑크스: X
-ray영상을 이용한 밀수 및 위험물 적발 기술사업기간2019.09 ~ 2020.09(2차), 2020.09 ~ 2021.09 (3차)거래처 및 금액국가과학기술연구회, 2차1.4억, 3차1.3억(민간출자)사업내용영상분석 기반 밀수품 은닉 적발기술 및 화물 내 은닉 폭발물 마약 탐지 기술 개발사업성과
– ETRI에서 개발한CT to DRR기술에 대해 기술이전 받음
-판독자 테스트 프로그램 개발 방향 수립3)인공지능X
-ray판독시스템사업명인공지능(AI) X
-ray판독시스템사업기간2021.07 ~ 2021.12거래처 및 금액경찰청, 43백만원사업내용위험물품 탐지를 위한AI기반 판독시스템 구축사업성과약110종의 위협물품에 대한 데이터와AI판독시스템 구축3)AIX
-ray판독시스템사업명AI X
-ray판독시스템 구축(1,2단계)사업기간2019.06.24 ~ 2020.02.19, 2020.05.27 ~ 2020.12.23거래처 및 금액관세청, 14.8억(단계), 16.4억(2단계)사업내용반입 불법물품 검출을 위한AI기반X
-ray판독 시스템 구축,빅데이터 분석사업성과1,2단계에 걸쳐 총54종의 불법물품에 대한 데이터 구축 및AI알고리즘 개발,기존 관세청 시스템과 연계 - 기업 개요 및 핵심역량 : 1.
기업 개요 및 핵심 역량 2018년에 설립한 ㈜에이리스는 X
-Ray 및 일반영상 판독을 위한 AI 솔루션 개발 전문업체입니다.
영상의 제작, 수집, 정제부터 AI학습까지 AI 솔루션 개발의 전 과정을 수행하고 있습니다.
2019년과 2020년 관세청 AI X
-ray 판독시스템 구축 사업에 참여하여 솔루션 AIXAC을 개발·배치하였으며, 2021년 NIA학습용데이터 구축사업을 통해 데이터수집, 정제, 가공작업을 직접 수행함으로써 영상데이터 가공 노하우을 체득하였고 관련 기술을 꾸준히 개발하고 있습니다.
데이터 가공팀과 AI 학습팀과의 협업으로 AI 학습에 최적화된 영상데이터을 제공할 수 있다고 자신합니다.
[사업연혁]날짜내용2022.06~2022.11K
-data 데이터바우처 과제 참여(공급)2022.05~2022.12NIPA AI솔루션 공급 바우처사업 2건2022.05~2022.09경찰청 이동형 AI X
-ray 납품(위협물품 110종)2021.05~2021.12NIA AI학습용데이터 구축사업 과제 참여2021.02AI 학습데이터 관리시스템 ‘AIDM’개발2020.12한국전자통신연구원으로부터 2D/3D X
-ray 이미지를 활용한 DRR 생성기술 이전2020.04X
-Ray 영상 AI 학습데이터 제작 솔루션 ‘PRIM’개발2019.06~2020.12관세청 AI X
-ray 판독시스템구축 (1단계,2단계) 사업수행 2019.09~2021.09X
-Ray 영상을 이용한 밀수 및 위험물 적발 기술 RnD 사업참여 (2년연속)2019.09기업부설연구소 설립2018.08주식회사 오픈이노베이션 창립[사업영역] (주)에이리스는 수요처가 제공하는 X
-Ray영상 및 일반영상을 가공하는 것뿐만 아니라, 직접 관련 이미지 영상을 제작가공하는 서비스를 제공합니다.
또한 수요처가 원할 경우 해당 가공데이터로 필요한 AI 알고리즘을 개발하여 공급합니다.
<;주요사업분야>AI 학습용 데이터 구축 분야AI 개발 분야X
-Ray 및 일반영상 제작AI 알고리즘 개발 - 활용 사례 : [보안분야 X
-Ray 영상시장]전통적인 수입 외에 전자상거래로 인해 세계적으로 화물 이동량이 폭증하고 있습니다.이에 따라 위해물품의 반입 빈도도 증가하고 있어 보안분야에서는 보다 효과적으로 위해물품을 차단하기 위해 AI X
-Ray 영상판독 기술을 활용[산업 및 의료분야 X
-Ray 영상시장]산업에서는 이물질 검사,품질 검사 등 여러 영역에X
-Ray영상을 활용하고 있습니다.또한,의료 분야에서는 진단 및 검사에서AI X
-Ray 영상판독 기술을 활용
(주)지오넷 소개
- (주)지오넷은 2016-08-25에 설립되었습니다.
- 주소 : 대전 유성구 북유성대로 219 207호
- 주요 서비스 : 아카이브솔루션, 데이터전처리, 아카이브홈페이지, 오픈API, 빅데이터플랫폼, 빅데이터 대시보드, 디지털시장실, 시정모니터링, 멀티미디어아카이브관리시스템, 빅데이터 분석, 빅데이터
- 보유 솔루션 : 1) 빅데이터 관리 전용 CMS : P
-CSM Ver 2.0아카이브
-씨엠에스Ver 1.0관리자시스템 화면 메뉴 관리(신규등록, 수정, 삭제 등)데이터 관리 (수정, 등록, 삭제)데이터 일괄 등록 관리데이터 정보관리 (데이터 출처, 유형, 갱신주기, 입력 방식 등)데이터 시각화 솔루션 표출을 위한 데이터 제공 등
2) 빅데이터 통합 플랫폼가공실적
– 논산 빅데이터 플랫폼 구축 사업, 아산시, 천안시, 용인시, 대전 유성구, 금산 빅데이터 플랫폼 구축 사업전자정부 표준프레임워크 CMS 기반 관리지자체, 공공기관의 보유 데이터를 활용한 빅데이터 플랫폼수집 표준화된 데이터 셋 정의 및 시각화대시보드를 통한 실시간 빅데이터 분석 자료 열람3)아카이브 플랫폼:아카이브
-씨엠에스Ver 1.0관리자시스템 화면 메뉴 관리(신규등록, 수정, 삭제 등)아카이브 사용자화면 링크서비스 관리사진/영상 자료의 원본 및 멀티(다중)데이터 파일 등록 기능등록된 데이터의 태그, 생성일, 촬영일, 지역, 설명 등의 메타데이터정보를 관리할 수 있으며, 공공누리 유형 표시 기능 제공사진/영상 자료의 카테고리 생성 및 추가 기능 제공등록된 사진/영상 자료의 카테고리 이동 및 개별 데이터 이동 기능등록된 사진/영상 자료의 다운로드 기능등록된 사진/영상 자료의 카테고리별, 시대별, 지역별 등의 일괄통계기능 제공아카이브 사용아카이브 사용자화면에서 태그, 키워드, 제목 내용 등의 다양한 조건 검색 기능 제공 - 품질 확보 전략 : ㅇ가공 플랫폼 대외적인 품질검증을 위한 GS 인증 획득 및 유지
– 공공시장 판매 및 대외적인 공신력유지를 위하여 가공플랫폼의 GS (GoodSoftware) 인증획득을 완료하였고, 지속적인 버전을 개선하고 GS인증이 유지 되도록 R&D 조직을 운영하도록 하겠습니다.ㅇ플랫폼의 안정적인 성능 향상을 위하여 운영환경 튜닝 및 DB 튜닝 지속화 및 개선
– 빅데이터 플랫폼 및 아카이브 플랫폼의 성능품질 유지 및 개선을 위하여 다양한 환경에 이식하여 운영환경별 조건에 따른 품질저하 구간 탐색 및 성능향상을 위한 최적의 조건을 검출하기 위하여 지속적인 테스트를 진행하겠습니다. - 유지보수 전략 : 1.
플랫폼 도입기업 (기관) 의 유지보수 또는 기술지원 요청시 요청사항을 고객지원 형상관리 툴을 통해 신청할 수 있고, 신청된 요구사항을 고객지원팀에서 업무분야별로 선별하여 대응처리 하겠습니다.
2.
수요기업의 체계적인 고객관리 및 유지보수 응대를 위해 고객요구사항을 통합관리 할 수 있는 요구사항 형상 관리 툴을 자체적으로 개발 운용하고 있으며, 요구사항 등록시 전담부서 담당자와 수요기업 담당자에게 실시간으로 요청사항 및 처리결과에 대한 내역이 e
-mail 및 moblie Phone으로 전달 되도록 하여 고객 대기시간이 줄어들고 응대율을 높이는 원스톱 처리체계를 갖추었습니다.
3.
아래 기본인력을 활용하여 납품된 소프트웨어의 유지관리와 추가사업에 대한 대비 진행하겠습니다.담당이름전문분야데이터 가공 업무신현민공공데이터 수집/가공/개방 업무데이터 가공 업무정은영공공데이터 수집/가공/개방 업무고객요구사항분석홍범균공공/행정기관 정보시스템 기획 업무안내 및 고객대응이범식공공/행정기관 정보시스템 기획 업무 - 카테고리 구분 : 전처리,품질,코딩,시각화,정보추출또는조합,태깅또는라벨링,분석,기타
- 실적 : 연번사업명사업내용수행기간발주처12022년 빅데이터 통합 플랫폼 고도화빅데이터 통합 플랫폼 2022.8 ~ 2023.1논산시청2유성형 데이터 통합 플랫폼 구축(진행중)2022.7 ~ 2023.2유성구청3금산군 빅데이터 통합 플랫폼 구축2022.4 ~2022.11금산군청4천안시 빅데이터 플랫폼 구축사업 2021.7.
~ 2022.2천안시청5아산시 통합 빅데이터 플랫폼구축(2단계)2021.6.
~ 2021.12.아산시청6아산시 통합 빅데이터 플랫폼 구축(1단계)2021.4.
~ 2021.6.아산시청7논산시 빅데이터 통합 플랫폼 구축2020.3 ~ 2020.10논산시청8충북 문화유산 아카이브 시스템 구축2022.03 ~ 2022.12충북문화재연구워9웅진백제문화 아카이브 DB 구축 활용아날로그 데이터 디지털화, 아카이브 시스템 구축, 아카이브 웹 서비스 구축, 오픈 API 구현 등 2022.8 ~ 2023.1공주박물관10안성시 디지털 아카이브 시스템 구축 용역 (구축/현재 유지보수 중)2020.5 ~ 2020.11안성시청11공연자료 디지털 아카이브시스템 구축 용역 (구축/현재 유지보수 중)2020.4 ~ 2020.10대전광역시(예술의전당)12충북의문화유산아카이브구축소프트웨어개발 (1,2차)(구축/현재 유지보수 중)2019.9 ~ 2019.122020.5 ~ 2020.12(재)충청북도문화재연구원2018.9 ~ 2020.03(재)충청남도역사문화연구원13역사문화자원아카이브자료관리시스템구축용역 (구축/현재 유지보수 중)2018.5 ~ 2018.12대전광역시14사진기록물아카이브시스템구축사업(구축/현재 유지보수 중)2018.2 ~ 2018.8함양군청15함양군멀티미디어아카이브관리시스템구축사업 (구축/현재 유지보수 중)2018.2 ~ 2018.5금산군청16금산군통합미디어센터및자료관리시스템구축 (구축/현재 유지보수 중) - 기업 개요 및 핵심역량 : ㈜지오넷은 지자체, 공공기관에 특화된 빅데이터 기반 정보화 서비스를 제공하는 ICT 기반 시스템 구축 전문기업입니다.
공공기관에 최적화된 GS 인증 통합콘텐츠관리시스템(CMS) 원천기술을 기반으로 정보화전략계획 컨설팅, 플랫폼 구축, 빅데이터 분석, 아카이브 시스템, 디지털 사이니지 대시보드 시스템 등을 주력 사업으로 서비스하고 있습니다.ㅇ주요 사업범위
– 빅데이터 통합 플랫폼 구축 사업
– 멀티미디어 자료 아카이브 관리 솔루션 구축 사업
– 공공데이터 개방 시스템 구축 사업 (오픈 API 구현)
– 데이터 전처리 및 데이터 디지털화 사업 - 활용 사례 : 1) 논산시 디지털 시장실 구성을 위한 빅데이터 플랫폼 구축 및 고도화(2019년 ~ 2022년)
– 2020 정부혁신 박람회 참여
– 전자정부 표준프레임워크 우수 활용사례 대상수상
2) (주)한국기업데이터 빅데이터 플랫폼 구축 및 고도화 (상황실 구축) (20202년)3) 아산시 빅데이터 플랫폼 구축 및 고도화 (2021~2022년)4) 천안시 빅데이터 플랫폼 구축 및 고도화(2021~2022년)5) 용인시 빅데이터 플랫폼 구축 (2021년 ~ 2022년)
조슈아파트너스 주식회사 소개
- 조슈아파트너스 주식회사은 2013-01-02에 설립되었습니다.
- 주소 : 대전 유성구 어은로51번길 44 대전광역시 유성구 어은로51번길44, B1층
- 주요 서비스 : 판매 데이터(또는 가공 서비스)의 상품성 1.
일반인이 포함된 불특정 다수의 작업자(크라우드 소싱 방식)가 레이블 또는 가공한 데이터는 대체로 품질관리가 어려워, 전문인력이 별도 검수를 통해 문제점 해결 2.
데이터의 양이 많아지고 검수에 투입되는 시간과 비용이 같이 상승하고 검수의 정확도가 떨어질 수 있어 데이터 품질 보장이 어려운 문제점이 있음 → 해당 문제는 검수 프로그램 반자동화를 통해, 검수 정확도를 높이고 시간과 단가 절감 가능 3.
고품질의 데이터를 생산 가공하여 적은 양으로도 고성능의 AI 엔진 또는 분석이 가능하도록 데이터 품질 지속적인 유지보수 및 관리 서비스 제공 4.
크라우드 소싱 플랫폼 구축을 통한 인력관리, 프로젝트 관리 가능(프로젝트 설계, 작업자 모집, 작업환경 제공, 데이터 품질 관리 기능 적용) - 보유 솔루션 : 1) 데이터 가공 서비스작업자를 모집하고 모집된 작업자가 데이터 가공이 업무를 할 수 있는 작업환경 제공
– 텍스트 가공 서비스 : 기사, 논문, 문헌 요약 및 키워드 분류/처리/취합
– 자연어 처리 서비스 : 챗봇 대화 및 말뭉치 수집
– 음성 처리 서비스 : 음성 전사, 음성 자막 생성 서비스 제공
– 이미지 라벨링 서비스 : 이미지 속 문자 찾기, 이미지 속 객체 구분 등의 이미지 라벨링 서비스 제공
– 센서 데이터 전처리 서비스 제공: 센서 데이터의 전처리(결측치 및 오류값 처리) 및 데이터 클렌징 서비스 제공
2) 데이터 검수 관리
– 데이터 정량화를 기반으로 생산된 데이터와 가공된 데이터의 검수와 데이터 작업자 관리가 가능한 검수 관리 시스템 제공
– 데이터 검수 인력 양성 (자체 교육 프로그램 운영을 통한 데이터 검수인력의 검수 품질 향상 및 검수 결과 수치화) 3) 데이터 증강 기술데이터의 특성과 레이블 유무, 전문성을 고려하여 유효 데이터의 부족한 양을 효과적으로 늘리는 동시에 증폭된 데이터 품질 유지정형 비정형 데이터, 영상 및 시계열 데이터 모두 증강 적용 가능 4) 데이터 가치 정량화데이터 분류를 통해 기존 정형 데이터 외 다양한 비정형 시계열 데이터에도 데이터 가치 정량화를 가능하도록 기술 고도화 5) 데이터 관제 시스템자사의 H/W 관리 역량을 활용하여 센서 데이터 등 H/W 기반의 시계열 데이터를 모니터링 가능한 데이터 관제 시스템 제공 - 품질 확보 전략 : ?
- 유지보수 전략 : ?
- 카테고리 구분 : 전처리,품질,시각화,정보추출또는조합,태깅또는라벨링,분석
- 실적 : 번호사업명역할1전력 빅데이터를 활용한 국내외 융합신서비스 사례 분석 용역참여 기업이 필요한 데이터를 제공하고 목적에 맞게 가공할 수 있는 솔루션 제공2우주과학기술기반 창업문화 확산 사업참여 기업의 사업계획서를 검토해주고 포함된 데이터 시각화 기술 제공32021 강소특구(안산,청주,청안아산) 액셀러레이팅 법인설립 특화프로그램 위탁용역 운영대행참여 기업이 필요한 데이터를 제공하고 목적에 맞게 가공할 수 있는 솔루션 제공4교통대/한밭대 하계 메이커톤참여 기업이 필요한 데이터를 제공하고 목적에 맞게 가공할 수 있는 솔루션 제공5스마트팩토리 분야 설문 컨설팅 및 현황분석 용역참여 기업이 필요한 데이터를 제공하고 목적에 맞게 가공할 수 있는 솔루션 제공62022학년도 충북북부권대학 연합창업캠프 프로그램 위탁운영참여 기업이 필요한 데이터를 제공하고 목적에 맞게 가공할 수 있는 솔루션 제공7충남지역혁신(소셜벤처) 창업기업육성지원사업 소셜벤처기업 기본심화교육 위탁운영참여 기업이 필요한 데이터를 제공하고 목적에 맞게 가공할 수 있는 솔루션 제공8업싸이클링 메이커톤참여 기업이 필요한 데이터를 제공하고 목적에 맞게 가공할 수 있는 솔루션 제공9ICT 디바이스 용인랩 운영 및 기술지원 용역참여 기업이 필요한 데이터를 제공하고 목적에 맞게 가공할 수 있는 솔루션 제공102020년 창업커뮤니티 네트워크 구축사업 프로그램 운영참여 기업이 필요한 데이터를 제공하고 목적에 맞게 가공할 수 있는 솔루션 제공112020년 지역기반 로컬크리에이터 활성화 지원(추경) 사업 교육멘토링 용역 계약참여 기업이 필요한 데이터를 제공하고 목적에 맞게 가공할 수 있는 솔루션 제공122020년 G
-스타트업챌린지참여 기업이 필요한 데이터를 제공하고 목적에 맞게 가공할 수 있는 솔루션 제공13스마트팩토리 메이커 캠퍼스톤 - 기업 개요 및 핵심역량 : 1.
기업 개요 및 핵심 역량 기업소개 기업명 : 주식회사 촉 주요 사업 분야 : 1.
사업모델창업교육아이디어창출시제품 제작 R&D인큐베이팅 Business 이론 교육 사업계획서 검토 사업 모델 데이터 수집 멘토링 데이터 고도화 사회경제적 가치창출 메이커스빌 운영 Pilot scale up 투자연계 및 IR 실무 글로벌 IP
-R&D
– 공급기업은 사업 초기 정부 창업 지원사업을 통해 창업자 및 예비창업자를 대상으로 사업에 필요한 데이터를 제공하며 창업 관련교육, 데이터 수집 컨설팅, 시제품 제작 서비스, 기타 액셀러레이팅 사업을 추진 (정부 지원사업을 통한 매출 기반 확보 및 브랜드 인지도 향상)
– 지속적인 매출성장을 위해 정부 지원사업의 매출 비중을 감소시킬 계획이며, 데이터 수요기업의 필요를 충족시켜줌으로써 고객으로부터의 직접적인 매출을 확보함2.
데이터 공급
– 특정분야의 데이터가 필요한 데이터 수요기업의 요청에 따라, 다양하고 깊은 수준의 데이터를 수집하고 보유한 기술로 필요에 맞게 가공 후 수요기업에 공급
– 각 수요기업에 전문 인력을 배치하여 정확하고 신속한 데이터 공급을 진행 3.
교육 서비스
– 창업 기초교육, 실무교육, 경영, 기타 창업 문화행사 등 스타트업 아이디어 발굴부터 기업경영에 이르는 전 주기적 교육 콘텐츠 데이터를 보유하고 있음
– 보유중인 교육 콘텐츠 데이터를 수요기업의 특성에 적합하게 분류 후 공급기업 전문인력 POOL을 활용하여 교육 내용의 전문성을 향상시킬 계획임 4.
스타트업 액셀러레이팅
– 공급기업의 관계사인 액트너랩, CNTTECH, K
-그라운드는 스타트업 액셀러레이터로 창업자들에게 필요한 데이터를 제공, 유망 스타트 업 발굴, 프로젝트를 통한 사업화 지원, 기술 전문가 멘토링, 직접투자 및 후속 투자유치 컨설팅, 해외시장 진출 업무를 진행 중에있음
– 따라서 수요기업 발굴 및 육성되는 우수 스타트업에 대하여 - 활용 사례 :
(주)신테카바이오 소개
- (주)신테카바이오은 2009-08-10에 설립되었습니다.
- 주소 : 대전 유성구 엑스포로 1 엑스포타워 1903호
- 주요 서비스 : 1.
DeepMatcher®
-Hit (AI 활용 합성신약
-단백질 상호작용 데이터 분석 서비스)DeepMatcher®는 물리학 이론과 딥러닝을 토대로단백질
-화합물 간 상호작용 가능성과 결합 에너지를 분석하는 서비스임.
단백질
-화합물 결합구조당 수천개에 달하는 다양한 결합자세를 시뮬레이션하고 분석함으로써분자 구조의 유연성 등을생체 내 현상에보다가깝게 모사하여 데이터를 가공, 분석함.DeepMatcher®로 가공된 데이터는 주어진 표적 단백질에 대한 유효물질 후보를 선정하는데 활용되며이 과정을 통하여실험적 탐색 방법인HTS(High throughput screening)수행없이도 유효물질 후보를도출할 수 있다는 점에서 비용 및 시간 절감효과를 제공함.2.NEO
-ARS™ (AI 활용 신생항원 데이터 예측, 분석 서비스)NEO
-ARS™는암환자 종양조직 및 혈액의 유전체 시퀀싱 원시데이터를 가공하여 종양 특이 변이를 발굴하고,종양특이변이가 포함된 펩타이드와 인간백혈구항원(human leukocyte antigen, HLA) 단백질의 결합력을물리학 이론과 딥러닝에 기반하여 분석하는 서비스임.이와 더불어 해당 결합체 상에서 T세포 수용체 방향으로 노출되어 있는 펩타이드 표면 면적까지 계산하여 면역원성 예측에 대한 정확도를 향상시켰음.
분석된 데이터는 환자 맞춤신생항원(neoantigen)후보를 선정하여 치료용 항암백신이나 T세포치료제를 개발하는데 활용 가능함. - 보유 솔루션 : ●당사는 자체 구축한 고성능 컴퓨팅 인프라를 이용하여 신약개발 데이터 가공 서비스를 운영하고 있음.1.
자체 고성능 컴퓨팅 인프라의 필요성당사의 DeepMatcher
-HIT 및 NEO
-ARS™ 가공 서비스는 공통적으로 단백질과 화합물 간 상호작용을 3차원 결합구조 시뮬레이션을 통해 수행함.
따라서 1, 2차원 데이터를 다루는 통상적인 데이터 가공 프로세스에 비해 보다 큰 규모의 컴퓨팅 인프라가 요구됨.
3차원 결합구조 시뮬레이션에 있어서도 단백질
-화합물 결합구조의 유연성을 고려하기 위해 각각의 결합구조 별 최대 2만 개의 결합자세(컨포머)를 시뮬레이션하여 데이터를 가공하므로 당사 데이터 가공에는 천문학적인 수의 연산 이 수행됨.
이에 따라 당사에서는 상용 클라우드 인프라 사용 대신 자체적으로 고성능 컴퓨팅 인프라를 구축하여 운영하고 있음.2.
하드웨어 구축 현황당사는 한국전자통신연구원(ETRI)로부터 생명정보 데이터 분석 전용 MAHA
-FsDx 슈퍼컴퓨팅 기술을 이전 받아 2014년부터 운영하고 있음.MAHA
-FsDx 슈퍼컴퓨터는 ▲실제 데이터를 분석하는 마하 컴퓨팅 시스템, ▲분석 결과 및 중간 생성물을 저장하는 마하 파일 시스템, ▲유전체 및 단백체 분석을 위한 분석 툴, ▲고성능 백업 시스템으로 구성되어 있음.100,000대 규모까지 관리할 수 있는 뛰어난 확장성을 보유한 시스템.
– 당사는 생명정보 분야에서는 국내 유일하게 자체 슈퍼컴퓨팅 센터를 운영하고 있음.구성요소 역할구성요소역할마하 컴퓨팅 시스템대규모의 데이터 분석을 위해 최대 100,000대 규모의계산용 노드(각 노드 당 1600 core, 12,8 TB Memory)를 사용하며, 이들을 관리하는 관리 노드로 이루어짐.마하 파일 시스템분석과정 중 생성되는 대용량 데이터에 대한 저장공간을 제공함.Bio ToolBox데이터 가공에 필요한 분석 알고리즘, 파이프라인들을 모듈화한 저장소백업 시스템원본 데이터, 분석 결과 데이터,연구용 데이터 등 백업이 필요한 항목을 백업해 두 - 품질 확보 전략 : ●당사는 데이터 가공 프로세스의 품질 확보를 위하여 아래와 같은 전략을 구사하고 있음.후향적 데이터를 기반으로 데이터 가공 품질 검증 및 알고리즘 업데이트데이터 가공 프로세스의 결과물을 전향적인 실험 검증을 통하여 품질 확인안정적인 데이터 분석 및 AI 적용을 위한 데이터 보안 및 하드웨어 시스템 안정화 체계 확립각각은 전담 부서를 통해 운영되고 있으며 품질 검증 및 제고를 위해 각 부서 담당 인력들이 유기적으로 협력하고 있음.특히, 전담 부서 중 AI 신약 연구기획 및 관리팀의 경우는 품질 검증을 데이터 기반에서 전향적 실험을 통한 검증으로까지 확대하기 위해 2019년 하반기 신설된 부서로, 치료제 비임상 연구 전문 인력으로 구성되어 있음
- 유지보수 전략 : ●수요기업 대상으로 서비스를 제공하기 위해 세부적인 계획 수립서비스에 대한 상세 설명 및 수요기업의 니즈를 확인하는 미팅 진행수요기업과 서비스 계약 체결공급기업 및 수요기업의 신약후보물질 발굴을 위한 추진 계획 상세 협의서비스 일정 관련 협의서비스 수행을 위한 정보 교환서비스 목표에 따른 결과물 확인 및 피드백당사와 수요사 각각에서 주요 프로젝트 참여 인원을 임명하여 공동운영위원회(Joint Steering Committee, 이하 JSC)를 운영.선 합의된 회의 주기에 따라 JSC 회의를 진행하여 데이터 가공 프로세스 진행 경과와 결과물에 대하여 소통.●수요 증가시 대응 방안당사는 데이터 가공서비스를 위해 CPU 서버 2,000대 및 GPU 1,000개 유닛을 자체 보유하고 있으며, 이는 동시 최대 10개의 데이터 가공 프로젝트를 수행할 수 있는 규모의 컴퓨팅 인프라임수요 증가에 따른 컴퓨팅 인프라 확충이 가능하도록 현재 슈퍼컴퓨팅 센터를 건립 중에 있음.
해당 센터는 2023년 상반기 내 완공을 목표로 하고 있으며, 완공 시 총 10,000대의 CPU 서버 및 GPU를 수용할 수 있는 규모.프로젝트의 우선순위에 따라 유연하게 일정 조절이 가능하도록 스케줄링 전담 인력 및 내부 지침을 마련하여 운영 중임.●유지보수, 고객관리 및 고객 응대 계획당사는 아래와 같이 서비스 고객 응대 및 관리, 유지보수를 위하여 아래와 같은 운영체계를 구축하여운영중.
구체적으로 수요기업과의 계약이 체결된 후 역할별로 △서비스 주문 관리, ▲서비스 수행에 필요한 시스템 요청 및 장애처리, ▲계약 관리, ▲데이터 보안 관리담당 인원을 배치하였음.
이 외에도 위에서 기술된 바와 같이 프로젝트에 직접 참여하는 각 분야 전문가로 구성된 JSC 운영을 통하여 학술적인 고객 응대를 수행하고 있음. - 카테고리 구분 : 전처리,정보추출또는조합,분석
- 실적 : 구분전담부처과제명사업기간연구비 주관기관 비고1식품의약품 안전평가원컴퓨터기반 임상시험(ISCT) 모델링 개발 연구2018.02.01.~ 2020.11.30.385,000,000 신테카바이오 연구용역2중소벤처기업부BIG3 기업 수요 맞춤형 AI기반 연구개발 서비스2020.11.02.~ 2020.12.12.150,000,000안전성평가 연구소일반 용역3중소기업기술정보진흥원EGFR 길항제의 동반진단 바이오마커 및 검증 시스템 개발2018.06.01.~ 2019.05.31.106,500,000 신테카바이오 비공개4산업통상자원부의료AI 개발을 위한 임상 유전체 데이터 공유 및 저장 기술 표준화2018.06.01.
~2020.12.31128,742,000 연세대학교 산학협력단 공동연구5과학기술 정보통신부보건복지부(한국연구재단)면역항암제 부작용과 관련된 유전체 바이오마커를 이용한 인공지능 약물감시 플랫폼 구축2019.06.01.~ 2021.12.31.800,100,000 서울 아산병원비공개※ 기타 공동연구 및 용역 실적은 고객사와의 비밀유지계약으로 인해 세부 계약조건 및연구 내용 공개 불가 - 기업 개요 및 핵심역량 : ●기업 개요㈜신테카바이오는 AI 기반 빅데이터를 활용한 신약개발 전주기 (유효물질 발굴부터 임상·처방까지) 및 다양한 치료제 형태 (합성 의약품 & 항암백신·T세포 치료제)에 적용 가능한 플랫폼(DeepMatcher® & NEO
-ARS™ 외)을 구축한 AI 신약개발 기업.1.
신테카바이오의 주요 연혁㈜신테카바이오는 2009년에 설립된 회사로, 신약개발에 가장 중요한 요소인 3차원 단백질 구조 및 유전체 빅데이터를 처리하는 기술 기반 AI신약 플랫폼 개발 서비스와 자체 신약 파이프라인 개발을 주된 사업으로 영위하고 있음.
특히, 2014년 한국전자통신연구원(ETRI)의 ‘유전체 빅데이터용 슈퍼컴퓨팅’ 기술 출자, 보건복지부 주관 ‘차세대 맞춤의료 유전체 사업단 위탁연구’ 및 국제암유전체컨소시엄 전장 암유전체 분석(ICGC
-PCAWG) 프로젝트 참여를 통해 플랫폼 서비스 개발의 초석이 되는 슈퍼컴퓨팅 및 빅데이터 인프라를 직접적으로 활용함.
이를 시작으로 여러 대형병원과 정밀의료 연구, 제약바이오 기업들과 신약 후보 발굴 및 바이오마커 연구를 수행하고 있음.
다양한 자체 프로젝트 (코로나19 약물재창출 연구, 대규모 신약후보물질 탐색 프로젝트 등)를 통해 신약 후보물질 지속적으로 발굴 진행 중임.●핵심 역량1.
신테카바이오의 주요 사업 영역 및 서비스 소개당사는 AI 신약 플랫폼 서비스와 AI 유전체 빅데이터 플랫폼 서비스 두 가지의 서비스를 보유하고 있음
1) AI 신약 플랫폼 서비스는 크게 2가지로, ⑴ DeepMatcher®
-Hit (AI 활용 합성신약
-단백질 상호작용 데이터 분석 서비스)와 DeepMatcher®
-Lead (선도물질 도출 및 최적화 서비스), ⑵ NEO
-ARS™(항암백신 및 T세포 치료제 개발을 위한 암환자 개인 맞춤 신생항원 발굴·예측 서비스)를 제공하고 있음.
2) AI 유전체 플랫폼 서비스는 NGS
-ARS™ 파이프라인이 있으며, NGS 유전체 분석 서비스를 통해 고형암·혈액암·희귀유전질환의 질병 변이 검출 및 - 활용 사례 : 1.
DeepMatcher®
-Hit (AI 활용 합성신약
-단백질 상호작용 데이터 분석 서비스)초기 유효물질 (HIT)의 가상탐색개발하고자 하는 표적 단백질이 정해져 있을 경우, 바로 탐색 가능개발하고자 하는 표적 단백질은 미정이나 표적 질환이 있는 경우, 논의 후 가능표적 단백질 및 질환 모두 미정인 경우, 신테카 보유 유망 DB로 논의 후 가능2.
NEO
-ARS™ (AI 활용 신생항원 데이터 예측, 분석 서비스)암환자 개인의 유전체 정보를 입력받아 예측할 경우 개인맞춤(private) 신생항원을 발굴하여 개인별 치료제 개발이 가능암환자 유전체 빅데이터로부터 추출된 종양변이 정보를 입력받아 예측할 경우 여러 환자에게서 공통적으로 발생하는 공유(shared) 신생항원을 발굴하여 기성품(off
-the
-shelf) 치료제 개발이 가능가공된 데이터를 기반으로 예측된 신생항원 후보는 다양한 모달리티의 백신 플랫폼(예, DNA, mRNA, 펩타이드, 항원제시세포 기반 백신) 및 면역항암 세포치료제 플랫폼(예, 신생항원 기반 T세포 치료제, TCR
-T 치료제)과 결합하여 치료제 개발이 가능함
주식회사 데이터메이커 소개
- 주식회사 데이터메이커은 2018-10-24에 설립되었습니다.
- 주소 : 대전 유성구 유성대로 871 4-5층(죽동, CU빌딩)
- 주요 서비스 : AI 어시스트엔진과 Managed Workforce를 통한 AI 학습데이터 가공 서비스datamaker synapse를 활용한 고품질 데이터 구축 및 AI 모델 관리 솔루션[데이터메이커 제공 솔루션]어노테이터워크스페이스머신러닝통합 및 연동Image이미지 데이터를라벨링 하는 툴데이터셋 관리import & export데이터셋 관리모델 학습비 개발자도 쉽게학습할 수 있는 웹 UI플러그인기본 또는자체 플러그인으로 확장Video영상 데이터를라벨링 하는 툴프로젝트 관리팀원 간의 커뮤니케이션& 일정관리모델 조회실시간으로 확인할 수있는 모델 학습에이전트보유 중인 GPU 자원에자유롭게 세팅Text텍스트 데이터를라벨링 하는 툴작업자 관리작업 할당 & 모니터링& 급여 정산모델 활용학습 시킨 모델을데이터 셋에 적용3D Point Cloud3차원 센서 데이터를라벨링 하는 툴품질 관리효율적이고 편리한검수 시스템[데이터메이커 제공 서비스]Image AnnotationVideo AnnotationText AnnotationLiDAR Annotation이미지 데이터라벨링 서비스영상 데이터라벨링 서비스텍스트 데이터라벨링 서비스라이다 3차원센서 데이터라벨링 서비스
- 보유 솔루션 : 데이터메이커 보유 솔루션
1) 자체 개발한 데이터 라벨링 저작도구 SW (
1) 다양한 라벨링 방식 지원 (ex.
바운딩박스, 폴리곤, 세그멘테이션, 3D 바운딩 박스 등) (
2) 다양한 타입의 데이터 지원 (ex.
이미지, 비디오, 텍스트, 오디오, 센서 등) (3) 대용량 데이터 지원, 고도화 된 라벨링 기능 지원 (ex.
라벨 객체간 관계 지정 등 (4) 고객사 별 맞춤 기능이 필요한 경우 플러그인 활용 가능
2)데이터메이커 데이터셋 관리 시스템 (
1) 고객사 스토리지에 저장된 데이터를 연동하여 업로드 할 수 있도록 지원 (ex.
API, CLI, Browser) (
2) 인공지능 학습 맞춤형 필터링 및 버전 관리 가능 (3) 데이터셋 관리 시스템 내에서 라벨링 된 데이터 필터링하여 확인 가능 (4) 라벨링 종류, 프로젝트 종류, 데이터셋 종류 등으로 필터링 가능3)AI 관련 보유기술 및 성과보유 기술명활동성과다중 사용자 기반데이터Annotation Tool
1) Image object Annotation Tool
– Bounding Box, Polygon, Polyline, Keypoint
2) Image Semantic Segmentation Tool3)Audio Annotation Tool(Speech To Text, Audio Metadata Tagging등)4) Classification Tool위의4종 외에도, LiDAR데이터 및센서 데이터의 가공을 위한Annotation Tool2019 ~ 2022데이터 바우처 사업 67개 수행2020 ~ 2022 AI학습데이터 구축 사업에12개 참여하였으며,자체 개발 저작도구를 활용하여 데이터 라벨링 및 크라우드 소싱에 활용2020 ~ 2021 AI학습데이터 구축 사업에5개 위탁 용역과제로 참여하여 데이터 라벨링 및 저작도구 임대안면 인식 모델 기반 비식별화 엔진개인정보 보호를 위한 비식별화 엔진을자체적으로 개발하여,인공지능 학습 데이터 셋 구축 사업 등에서 데이터 공개를 위하여 활용개발한 모델을 기반으로 - 품질 확보 전략 : 1.
데이터메이커만의 품질 관리 운영 방식
– 크라우드소싱과 인하우스 방식의 장점만을 채택한 데이터메이커 운영 방식 (크라우드 소싱의 가격과 확장성 + 인하우스의 보안과 품질 장점 모두 취득)2.
프로젝트별 라벨링 규칙 및 S/W에 대한 숙련도가 높은 전문 라벨링 인력이 수행
– 인공지능 고도화에 따라 수요기업에서 필요한 라벨링의 수준도 상향되어 전문 라벨링 인력 육성 필요3.품질 수행 기준 및 오류 기준 확립
– 담당 PM이 직접 고객사로부터 교육 이수 후 소규모 샘플데이터로 파일럿 프로젝트 실시 (고객사와 본 프로젝트 착수 전 라벨링 가이드라인과 오류 기준 설정, 납품 품질 기준 합의 집중) - 유지보수 전략 : – 사업 완료 후 데이터 가공 프로세스와 DB 관리의 환경적, 기술적 특성을 충분히 이해하는 하자보수 책임자를 지정
– 하자보수 발생에 대한 신속한 대응과 문제 해결을 위한 비상 연락망을 구축
– 사용자 지원창구를 통해 접수 후 하자보수 전담 인원에게 이관함으로써 일관성있는 지원체계를 유지보유 기술명활동유지보수 책임자가공 및 납품 데이터의 하자보수 사항 파악 및 보수 총괄유지보수 담당자보수 방법 결정에 따른 실무 수행, 유지보수 인원 운영데이터랩 작업 인력하자보수가 필요한 데이터 재가공데이터랩 검수 인력재가공 데이터에 대한 검수구분내용유지보수 대상○ 공급한 시스템의 모든 구성 요소를 대상으로 지원한다.○ 재가공이 필요한 공급 데이터에 대해 하자보수(재가공)을 지원한다.무상유지보수대상○ 사업 완료 후 6개월 이내에 발생하는 응용프로그램의 결함에 대한 하자보수○ 가공 가이드라인에 맞지 않게 가공되어 재가공이 필요한 공급 데이터○ 프로그램 장애 발생 시 온라인 지원(현장 지원은 협의 후 진행 가능)내용○ 시스템 비효율성 개선(최적화)○ 프로그램 장애 발생시 발견한 결함 및 장애복구공급한 시스템 오류에 대한 개선가공 가이드라인에 맞지 않게 가공된 공급 데이터 재가공유상유지보수대상○ 고객의 실수 또는 천재지변에 의한 시스템 장애○ 무상하자보수 기간 경과 후 발견한 하자○ 유지보수 인력 이외의 인력이 수행한 시스템 개조, 첨가, 조정 및 수리로 시스템에 중대한 영향을 끼친 경우내용○ 하자보수 기간 중 새로운 운영체제 혹은 새로운 하드웨어 환경으로 이식하는 경우 유상으로 서비스 제공○ 수요기업이 요구한 기능 설계의 오류로 인한 기능 수정/보완금액○ 투입공수 기준 비용 별도 협의하여 보수 작업 착수 - 카테고리 구분 : 전처리,품질,코딩,시각화,정보추출또는조합,태깅또는라벨링,분석,기타
- 실적 : [유사 사업 참여실적]수행 기간사업 내용주관 기관2019~2022K
-Data 데이터바우처 사업 공급기업 선정 및 데이터 가공 프로젝트 수행(71건)K
-Data2022CT 기반 연골구조 측정 시스템 개발NIPA2022어패류 성장 예측 모델 시스템 개발NIPA2022철도 선로 영상 데이터 구축NIA2022비전 데이터 가공NIA2022CCTV 객체 재인식을 위한 데이터 가공대전테크노파크2022119 음성신고 데이터 가공대전테크노파크2021AI 주차 유도 시스템 개발NIPA2021굴/가리비 이미지 데이터 가공NIA2021열화상 이미지 데이터 가공NIA2021인공지능 학습 파이프라인 개발TIPA2021인공지능 학습용 CCTV 데이터셋 구축, 관내 음식점 DB 구축대전광역시2020CCTV 영상데이터 가공NIA2020제주도 방언 음성 데이터 가공NIA2020영상 콘텐츠 데이터 가공NIA2020기계시설물 관련 센서 데이터 가공NIA2020자율주행 이미지 데이터 가공NIA2020반려동물 이미지 데이터 가공NIA2020영상 요약 데이터 가공NIA[보도 자료](▼링크를 클릭하시면 보도자료를 확인할 수 있습니다.)데이터메이커, 라벨링 효율과 AI 학습까지 지원하는 혁신적 솔루션데이터메이커, ‘AI의 군사적 활용 방안’ 발표데이터메이커, 우수 가공기업으로 데이터바우처 사업 참여데이터메이커, 데이터바우처 수행 사례 연구집 발간써밋츠, 데이터메이커와 AI 의료 데이터셋 구축 MOU 체결”체계적인 데이터셋 관리가 효율적인 모델 개발 이끈다” 데이터메이커 MLOps 파이프라인 선보여 - 기업 개요 및 핵심역량 : 데이터메이커는 AI 어시스트 엔진과 Managed Workforce를 통해 AI 학습 데이터를 가공하고, MLOps 플랫폼datamaker synapse를 활용한 고품질 데이터 구축 및 AI 모델 관리 솔루션을 제공하는기업입니다.저희는 컴퓨터 비전, 자연어 처리, 음성 인식을 위한 AI 가공 분야와 빅데이터 솔루션 개발을 위한 일반 가공 분야를 지원하고 있습니다.고객사의 높은 수준의 AI 개발을 위하여 최강 보안 환경 속에서 최고 정확도, 최다 가공량의 데이터로 가공해드립니다.[데이터메이커 요약]
– 글로벌 데이터 가공 플랫폼 ‘데이터메이커’
– 고난도 이미지 데이터 가공 분야 ‘시멘틱 세그멘테이션(Semantic Segmentation)’ 최고 인기
– 동일 예산 대비 가장 많은 데이터 가공량 제공
– AI 어시스트 엔진과 이중 전수 검수로 ‘고품질의 학습 데이터’ 제공
– 인하우스 보안 시스템으로 ‘고객사 데이터 유출 및 반출 최소화’
– 고객사별 전담 프로젝트 매니저 배정 등 ‘고객사별 철저한 매니지먼트 상시 소통 가능’ - 활용 사례 : 데이터메이커 수행 대표 사례 | 데이터바우처 이용 고객사고객사 분들에게 최고의 결과물을 드리기까지 저희 데이터메이커가 진심으로 고민한 이야기들을 들려드리고자 합니다.2020~2022년도 데이터바우처 지원사업을 통해 데이터메이커를 이용해주신 다른 고객사들의 이야기를 확인해보세요.데이터메이커 프로젝트 수행기 바로가기<;
– 클릭[기타 수행 사례]
– 항만, 해상 이미지 데이터 시맨틱 세그멘테이션 가공
– 반려동물 비만도 데이터 수집 및 가공
– 시각장애인 보행 보조용 횡단보도 데이터 수집 및 가공
– 자율 주행 드론을 위한 드론 촬영 영상 데이터 가공
– 반려견 홍채와 비문 데이터 수집 및 가공
– 자동차 주행시 창문 이미지 데이터 가공
– 인도네시아어
-꼼바이어 자동 번역을 위한 데이터 수집 및 가공
– 운동 데이터 수집을 위한 개발 및 데이터 시각화
– 드론 운전 교육 플랫폼을 위한 주행 환경 이미지 데이터 가공
– 음원 메타 데이터 표준화용 커스텀 템플릿 개발 및 품질 확인
– 안전 장비 착용 이미지 가공
– 자율 주행체 운전을 위한 차선 이미지 데이터 가공
– 금속 표면 이미지 데이터 가공
– 주차 공간 판별을 위한 주차장 이미지 데이터 가공

데이터바우처 사업관리 가공기업 정보
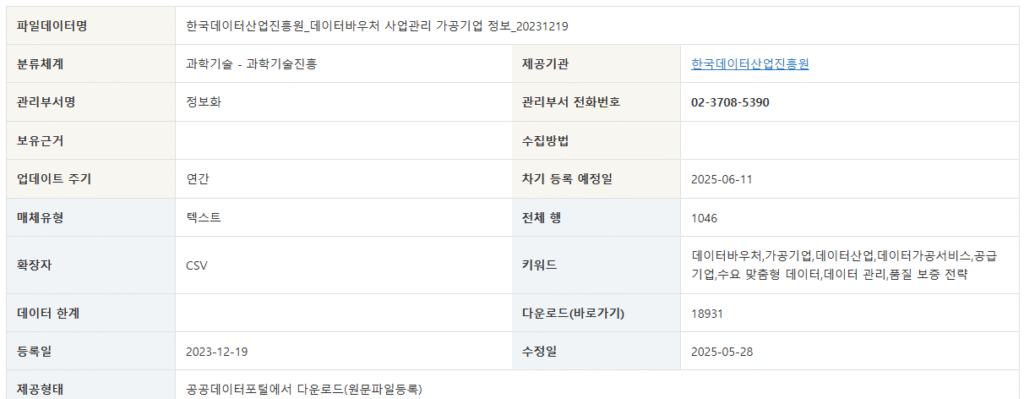
한국데이터산업진흥원 데이터바우처 사업을 통해 지정된 공급기업 중 데이터 가공기업 정보를 제공하고 있습니다. 본 데이터는 데이터바우처 지원사업에 참여하는 기업들의 정보를 포괄적으로 다룹니다. 특히, 수요기업이 필요로 하는 다양한 형태의 데이터 가공 서비스에 대한 정보를 제공함으로써, 데이터 활용의 범위를 넓히고, 기업의 데이터 기반 의사결정을 지원하는 역할을 합니다. 이 데이터가 보유한 컬럼은 다음과 같습니다.
기업한글명(문자형) : 해당 기업의 한글 이름
설립일자(날짜형) : 기업이 설립된 날짜
기본주소(문자형) : 기업의 본사 주소
상세주소(문자형) : 기업의 주소에 대한 추가 정보
주요서비스 상세정보(문자형) : 데이터 가공기업이 제공하는 구체적인 서비스 내용
보유솔루션(문자형) : 기업이 보유한 해결책 및 시스템에 관한 상세 정보
품질확보전략(문자형) : 데이터 품질 확보를 위한 기업의 전략
유지보수전략(문자형) : 데이터 가공 서비스 후속 지원 계획
카테고리구분(문자형) : 제공하는 데이터 가공 서비스의 카테고리 분류
등록일(날짜형) : 데이터가 등록된 날짜
실적(문자형) : 기업의 성과와 실적
기업개요 및 핵심역량(문자형) : 기업의 전반적인 설명과 주요 전문성
활용사례(문자형) : 데이터 및 서비스를 활용한 실제 사례
링크(URL) : 데이터에 대한 추가 정보 및 접근 링크
파일 다운받기
주요서비스 상세정보(요약), 보유솔루션(요약), 품질확보전략(요약), 유지보수(후속지원), 전략(요약), 실적(요약) 등의 일부 데이터 값은 데이터 미집계로 인해 공란이 있습니다.